ฐานความรู้สำหรับ Amazon Bedrock
ด้วยฐานความรู้สำหรับ Amazon Bedrock คุณสามารถให้ข้อมูลบริบทแก่โมเดลพื้นฐานและเจ้าหน้าที่จากแหล่งที่มาของข้อมูลส่วนตัวของบริษัทของคุณ เพื่อให้คำตอบที่เกี่ยวข้อง แม่นยำ และปรับแต่งได้มากขึ้น
การสนับสนุนที่มีการจัดการเต็มรูปแบบสำหรับเวิร์กโฟลว์ RAG แบบครบวงจร
เพื่อให้โมเดลพื้นฐาน (FM) มีข้อมูลที่ทันสมัยและเป็นกรรมสิทธิ์ องค์กรต่าง ๆ จึงใช้ Retrieval Augmented Generation (RAG) ซึ่งเป็นเทคนิคที่ดึงข้อมูลจากแหล่งที่มาของข้อมูลของบริษัทและเพิ่มประสิทธิภาพความรวดเร็วในการให้คำตอบที่เกี่ยวข้องมากขึ้นและแม่นยำยิ่งขึ้น ฐานความรู้สำหรับ Amazon Bedrock เป็นความสามารถในการจัดการอย่างเต็มรูปแบบมาพร้อมกับการจัดการบริบทเซสชันและการระบุแหล่งที่มาในตัว ซึ่งช่วยให้คุณสามารถใช้เวิร์กโฟลว์ RAG ทั้งหมดตั้งแต่การนำเข้าข้อมูลไปจนถึงการดึงข้อมูลและการเพิ่มประสิทธิภาพอย่างรวดเร็วโดยไม่ต้องสร้างการผสานรวมแบบกำหนดเองกับแหล่งที่มาของข้อมูลและจัดการกระแสข้อมูล นอกจากนี้ คุณยังสามารถถามคำถามและสรุปข้อมูลจากเอกสารเดียวโดยที่ไม่ต้องตั้งค่าฐานข้อมูลเวกเตอร์ได้อีกด้วย หากข้อมูลของคุณมีแหล่งที่มาที่มีโครงสร้าง Amazon Bedrock Knowledge Bases จะจัดเตรียมภาษาธรรมชาติที่ได้รับการจัดการในตัวให้กับโซลูชันภาษาการสืบค้นที่มีโครงสร้างเพื่อสร้างคำสั่งการสืบค้นเพื่อดึงข้อมูลโดยไม่จำเป็นต้องย้ายข้อมูลไปยังคลังข้อมูลอื่น
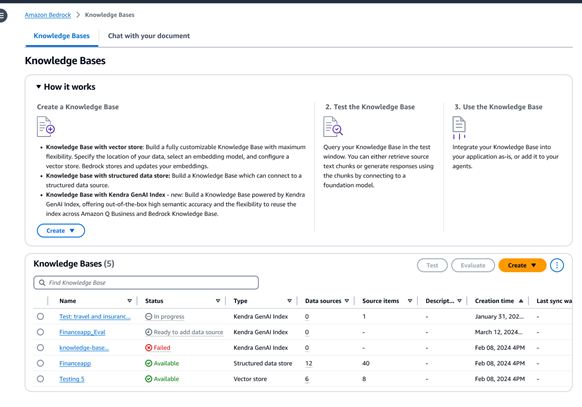
เชื่อมต่อ FM และเอเจนต์กับแหล่งที่มาของข้อมูลอย่างปลอดภัย
หากคุณมีแหล่งที่มาของข้อมูลที่ไม่มีโครงสร้าง ฐานความรู้สำหรับ Amazon Bedrock จะดึงข้อมูลจากแหล่งต่าง ๆ โดยอัตโนมัติ เช่น Amazon Simple Storage Service (Amazon S3), และ Confluence, Salesforce, SharePoint, หรือ Web Crawler ในการแสดงตัวอย่าง นอกจากนี้ คุณยังได้รับการนำเข้าเอกสารด้วยโปรแกรมเพื่อให้ลูกค้าสามารถรับข้อมูลสตรีมมิ่งหรือข้อมูลจากแหล่งที่ไม่รองรับได้ เมื่อนำเนื้อหาเข้ามาแล้ว Amazon Bedrock Knowledge Bases จะแปลงเนื้อหาดังกล่าวให้เป็นบล็อกข้อความ จากนั้นแปลงข้อความดังกล่าวให้เป็นข้อมูลที่มีการฝังไว้ แล้วจัดเก็บข้อมูลที่มีการฝังไว้ในฐานข้อมูลเวกเตอร์ของคุณ คุณสามารถเลือกจากพื้นที่จัดเก็บเวกเตอร์ที่รองรับหลายแห่ง ได้แก่ Amazon Aurora, Amazon OpenSearch แบบไม่ต้องใช้เซิร์ฟเวอร์, การวิเคราะห์ Amazon Neptune, MongoDB, Pinecone และ Redis Enterprise Cloud นอกจากนี้ คุณยังสามารถเลือกที่จะเชื่อมต่อกับดัชนีการค้นหาแบบไฮบริดของ Amazon Kendra สำหรับการดึงข้อมูลที่มีการจัดการได้อีกด้วย
เมื่อใช้ฐานความรู้สำหรับ Amazon Bedrock คุณยังสามารถเชื่อมต่อกับพื้นที่จัดเก็บข้อมูลที่มีโครงสร้างเพื่อสร้างการตอบสนองที่สมเหตุสมผล ซึ่งมีประโยชน์อย่างยิ่งเมื่อคุณมีแหล่งที่มา เช่น รายละเอียดการทำธุรกรรม ซึ่งได้รับการจัดเก็บไว้ในคลังข้อมูลและที่จัดเก็บข้อมูลดิบ ฐานความรู้สำหรับ Amazon Bedrock ใช้การเปลี่ยนจากภาษาธรรมชาติให้เป็น SQL เพื่อแปลงการสืบค้นเป็นคำสั่ง SQL และเรียกใช้คำสั่งเพื่อดึงข้อมูล โดยไม่จำเป็นต้องย้ายจากแหล่งที่มาของข้อมูลของคุณ
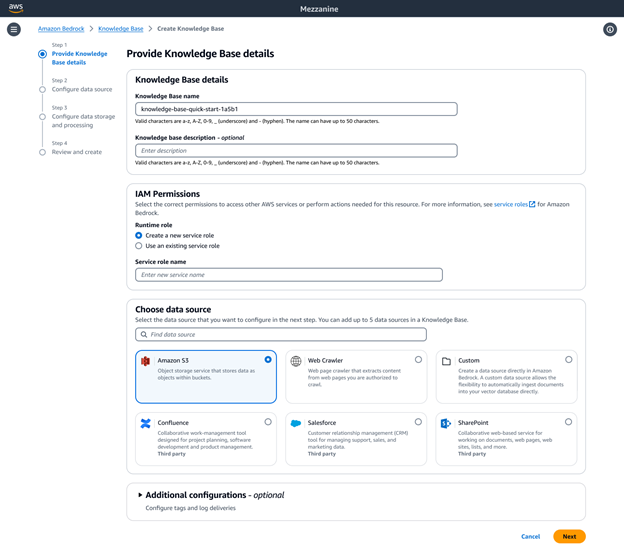
ปรับแต่งฐานความรู้ Amazon Bedrock เพื่อตอบสนองที่แม่นยำในช่วงรันไทม์
ด้วย Amazon Bedrock Knowledge Bases ซึ่งเป็นโซลูชัน RAG ที่คุณบริหารจัดการอย่างเต็มรูปแบบ คุณจึงมีความยืดหยุ่นในการปรับแต่งและปรับปรุงความแม่นยำในการเรียกค้น สำหรับแหล่งที่มาของข้อมูลที่ไม่มีโครงสร้างซึ่งประกอบด้วยข้อมูลหลายรูปแบบ เช่น ภาพ และเอกสารที่มีภาพหลากหลายพร้อมเค้าโครงที่ซับซ้อน (เช่น เอกสารที่ประกอบด้วยตาราง รูปภาพ แผนภูมิ และแผนผัง) คุณสามารถกำหนดค่าฐานความรู้ เพื่อแยกวิเคราะห์ และดึงข้อมูลเชิงลึกที่มีความหมายได้ คุณสามารถเลือก Bedrock Data Automation หรือโมเดลพื้นฐานเป็นตัวแยกวิเคราะห์ได้ ช่วยให้สามารถประมวลผลข้อมูลหลายรูปแบบที่ซับซ้อนได้อย่างราบรื่น ช่วยให้คุณสร้างแอปพลิเคชัน GenAI ที่มีความแม่นยำสูงได้
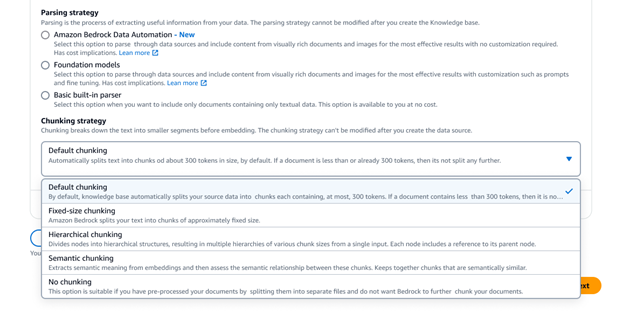
Amazon Bedrock Knowledge Bases มีตัวเลือกการแบ่งข้อมูลขั้นสูงที่หลากหลาย รวมถึงการแบ่งตามความหมาย ลำดับชั้น และขนาดคงที่ เพื่อการควบคุมแบบเต็มรูปแบบ คุณยังสามารถเขียนโค้ดการแบ่งส่วนข้อมูลของคุณเองเป็นฟังก์ชัน Lambda และยังใช้ส่วนประกอบสำเร็จรูปจากเฟรมเวิร์กอย่าง LangChain และ LlamaIndex ได้อีกด้วย หากคุณเลือก Amazon Neptune Analytics เป็นที่จัดเก็บเวกเตอร์ Amazon Bedrock Knowledge Bases จะสร้างการฝังและกราฟที่เชื่อมโยงเนื้อหาที่เกี่ยวข้องในแหล่งที่มาของข้อมูลของคุณโดยอัตโนมัติ Bedrock Knowledge Bases ใช้ประโยชน์จากความสัมพันธ์เนื้อหาเหล่านี้กับ GraphRAG เพื่อปรับปรุงความแม่นยำของการดึงข้อมูล ทำให้สามารถตอบสนองแก่ผู้ใช้ปลายทางได้อย่างครอบคลุม เกี่ยวข้อง และอธิบายได้มากขึ้น
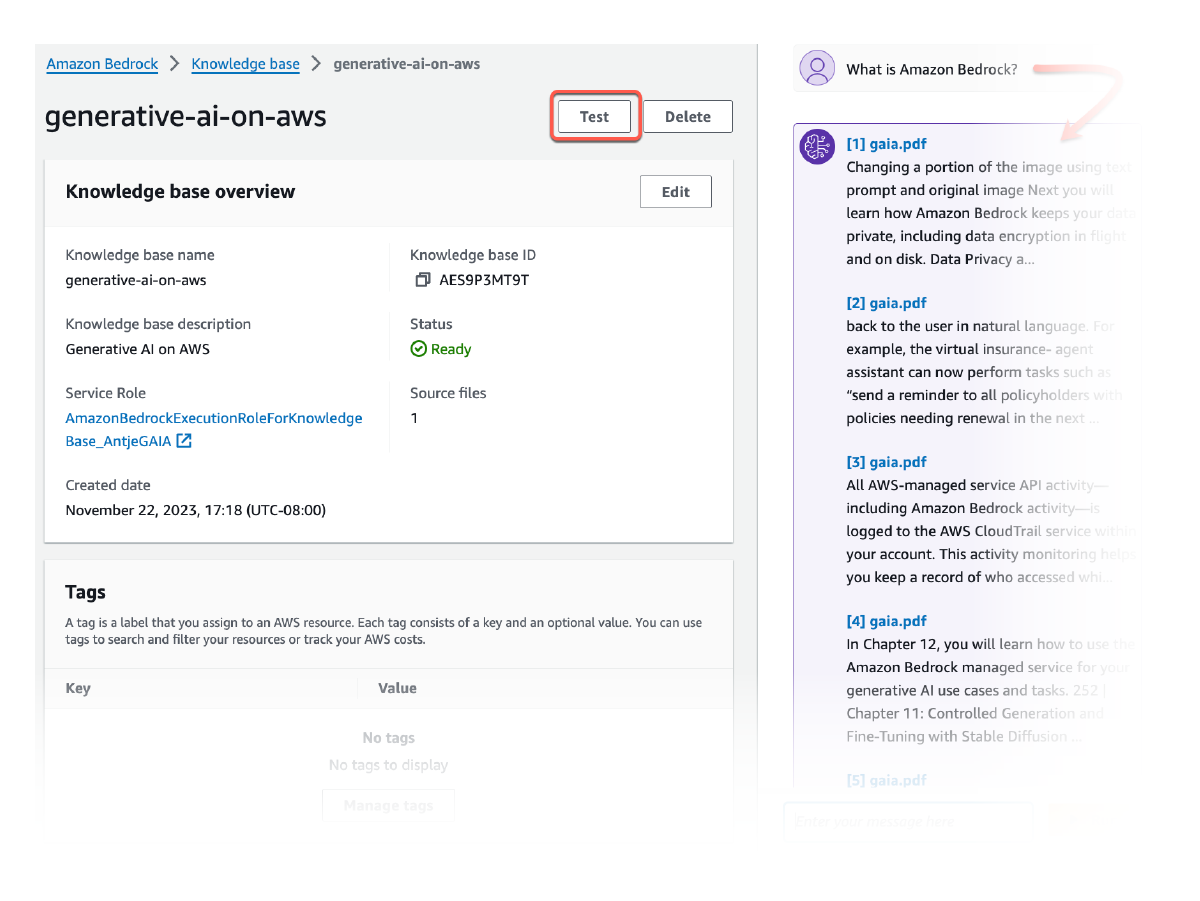
ดึงข้อมูลและพร้อมท์เพิ่มเติม
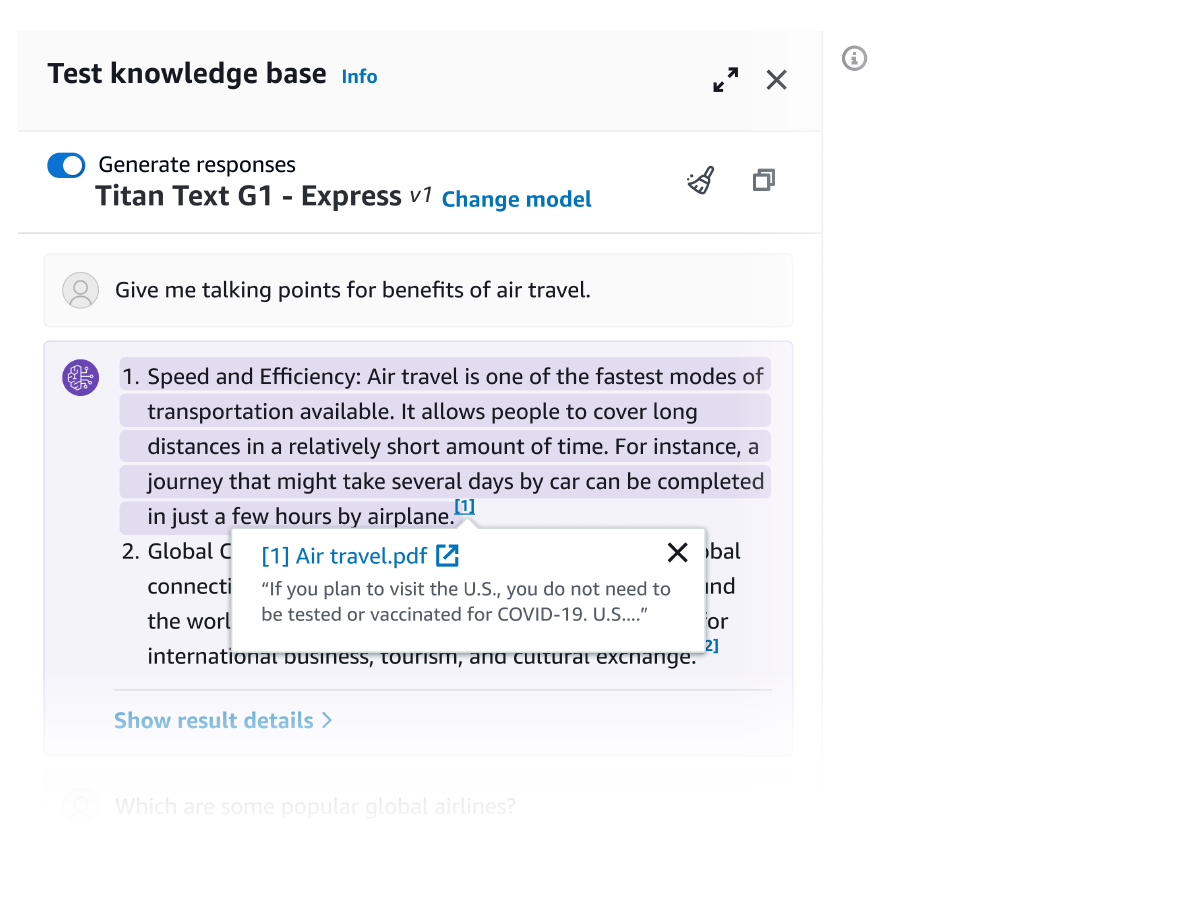
การใช้ Retrieve API ช่วยให้คุณสามารถดึงผลลัพธ์ที่เกี่ยวข้องสำหรับการสืบค้นของผู้ใช้จากฐานความรู้ รวมไปถึงองค์ประกอบภาพ เช่น ภาพ แผนผัง แผนภูมิ ตาราง เนื้อหาเสียงและวิดีโอ หรือข้อมูลที่มีโครงสร้างจากฐานข้อมูลเมื่อสามารถใช้ได้ RetrieveAndGenerate API ก้าวไปอีกขั้นหนึ่งโดยใช้ผลลัพธ์หลายรูปแบบที่ดึงมาโดยตรงเพื่อเพิ่มพร้อมท์ FM และส่งคืนการตอบกลับ คุณสามารถเลือกที่จะจัดให้มีตัวกรองหรือใช้ FM เพื่อสร้างตัวกรองโดยนัยเพื่อจำกัดผลลัพธ์ที่ส่งคืนให้เหลือเฉพาะเนื้อหาที่เกี่ยวข้องเท่านั้น Amazon Bedrock Knowledge Bases นำเสนอโมเดลการจัดอันดับใหม่เพื่อปรับปรุงความเกี่ยวข้องของชิ้นส่วนเอกสารที่เรียกค้นในเนื้อหาข้อความ ภาพ และมัลติมีเดีย
ระบุแหล่งที่มา
ข้อมูลทั้งหมดที่ดึงมาจาก Amazon Bedrock Knowledge Bases นั้นมีการอ้างอิง (ซึ่งรวมถึงภาพด้วย) เพื่อปรับปรุงความโปร่งใสและลดผลลัพธ์เพี้ยนให้เหลือน้อยที่สุด
วันนี้คุณพบสิ่งที่กำลังมองหาแล้วหรือยัง
การแจ้งให้เราทราบจะช่วยให้เราปรับปรุงคุณภาพของเนื้อหาในหน้าได้