亚马逊AWS官方博客
使用 AWS SCT 将大型数据仓库从 Greenplum 迁移到 Amazon Redshift – 第 1 部分
数据仓库收集和整合组织内各种来源的数据。它被用作分析和商业智能的集中式数据存储库。
解决方案概述
Amazon Redshift 是业界领先的云数据仓库。Amazon Redshift 使用结构化查询语言 (SQL),通过 AWS 设计的硬件和机器学习分析数据仓库、运营数据库和数据湖中的结构化数据与半结构化数据,针对任何规模提供最佳性价比。
AWS SCT 通过自动将源数据库架构和大多数数据库代码对象、SQL 脚本、视图、存储过程和函数转换为与目标数据库兼容的格式,使异构数据库迁移可预测。AWS SCT 可帮助您在数据库迁移期间同时实现应用程序现代化。架构转换完成后,AWS SCT 可以使用数据提取代理,帮助将数据从各种数据仓库迁移到 Amazon Redshift。
下图说明了我们使用 AWS SCT 数据提取代理将数据从 Greenplum 迁移到 Amazon Redshift 的架构。
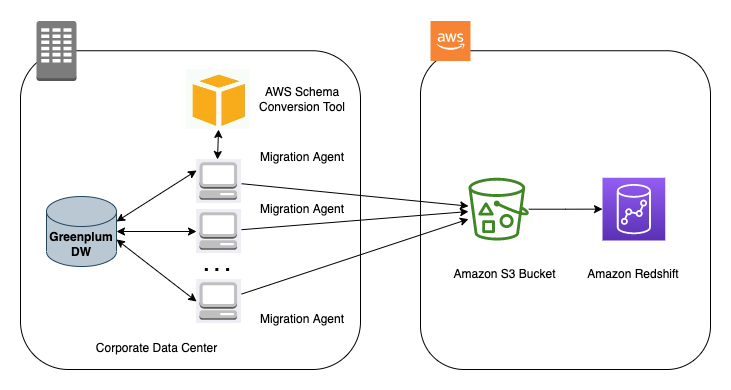
执行迁移评估
最初的数据迁移是该项目的第一个里程碑。此阶段的主要要求包括:尽量减少对数据源的影响,以及尽快传输数据。为此,AWS 提供了多种选择,具体取决于数据库的大小、网络性能(AWS Direct Connect 或 AWS Snowball)以及迁移是否为异构(AWS Database Migration Service (AWS DMS) 或 AWS SCT)。
AWS 提供云数据迁移服务组合,为任何数据迁移项目提供正确的解决方案。连接程度是数据迁移的重要因素,AWS 提供的产品可以满足您的混合云存储、在线数据传输和离线数据传输需求。
此外,借助 AWS Snow Family,可以轻松地通过离线方法将数据存储在 AWS 中或从中提取数据。如果您的数据达到 PB 或 EB 级,则根据数据大小,您可以使用 AWS Snowmobile 或 AWS Snowball。要确定哪种传输方法更适合您的使用案例,请参阅 AWS Snowball 的性能。
使用 AWS SCT 执行架构转换
要使用 AWS SCT 转换架构,您必须启动一个新的 AWS SCT 项目并连接数据库。请完成以下步骤:
- 安装 AWS SCT。
- 打开并启动新项目。
- 对于 Source database engine(源数据库引擎),选择 Greenplum。
- 对于 Target database engine(目标数据库引擎),选择 Amazon Redshift。
- 选择 OK(确定)。

- 打开您的项目,然后选择 Connect to Greenplum(连接到 Greenplum)。

- 输入 Greenplum 数据库信息。
- 选择 Test connection(测试连接)。

- 连接测试成功后,选择 OK(确定)。
- 选择 OK(确定),完成连接。

- 重复执行类似步骤,建立与 Amazon Redshift 集群的连接。

默认情况下,AWS SCT 使用 AWS Glue 作为迁移的提取、转换和加载 (ETL) 解决方案。在继续操作之前,必须禁用此设置。 - 在 Settings(设置)菜单上,选择 Project settings(项目设置)。

- 取消选中 Use AWS Glue(使用 AWS Glue)。
- 选择 OK(确定)。

- 在左侧窗格中,选择您的架构(右键单击),然后选择 Convert schema(转换架构)。
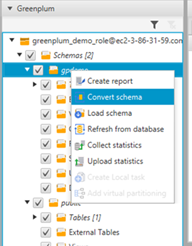
- 当系统要求替换对象时,选择 Yes(是)。

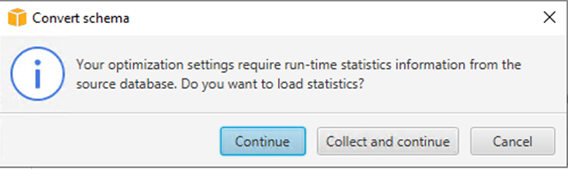
- 当系统要求加载统计信息时,选择 Continue(继续)。
在这一步结束时,所有 Greenplum 对象都应该迁移到 Amazon Redshift 语法。某些对象可能显示为红色,这意味着 AWS SCT 无法完全迁移这些对象。您可以查看迁移的评估摘要,了解更多信息。 - 在 View(视图)菜单上,选择 Assessment report view(评估报告视图)。

在底部窗格中,您可以并排查看选定对象的 Greenplum DDL 和 Amazon Redshift DDL 以进行比较。

- 选择带有红色图标的架构,表示需要手动转换。您将看到有关无法迁移到 Amazon Redshift 的表、约束或视图的特定操作。您必须调查这些问题,并使用所需的更改手动修复错误。一些示例是 BLOB 格式的二进制数据,AWS SCT 会自动将其转换为字符变化的数据类型,但系统可能会将其突出显示为问题。此外,一些供应商提供的过程和函数无法转换,因此,AWS SCT 可能会出错。
在最后一步,您可以验证表是否存在于 Amazon Redshift 中。 - 使用 Amazon Redshift Query Editor v2 或者您选择的其他第三方工具或实用程序进行连接,然后通过以下代码检查所有表:
迁移数据
要使用 AWS SCT 数据提取代理开始数据迁移,请完成以下步骤:
- 使用相应的 Greenplum 属性配置 AWS SCT 提取器属性文件:
接下来,您将 AWS SCT 提取器配置为执行一次性数据移动。处理大量数据时,您可以使用多个提取器。
- 要注册提取器,请在 View(视图)菜单上,选择 Data migration view(数据迁移视图)。

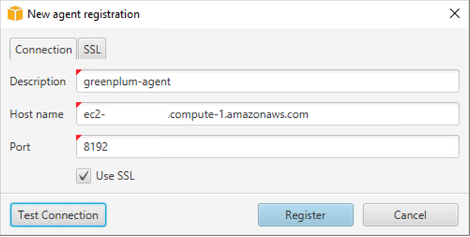
- 选择 Register(注册)。
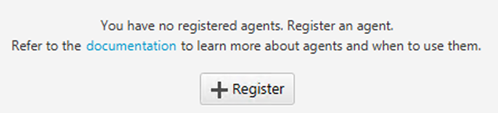
- 输入新代理的信息。
- 测试连接并选择 Register(注册)。
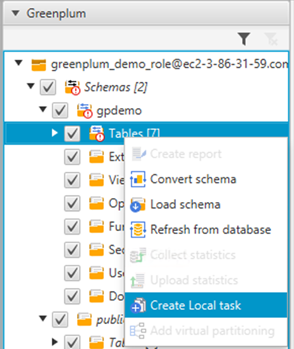
现在,为提取器创建一个任务,将数据提取到在 Amazon Redshift 上创建的表中。 - 在左侧窗格的架构下,选择 Tables(表)(右键单击),并选择 Create Local task(创建本地任务)。
- 对于 Task name(任务名称),输入名称。

- 测试连接并选择 OK(确定)。

- 选择 Create(创建)。
- 运行任务并监控其进度。

您可以选择每个任务以获取其活动的详细细分。请务必检查提取、上传和复制过程中的错误。

您可以监控任务的状态、已完成的百分比以及成功加载的表。您还必须验证加载到 Amazon Redshift 数据库中的记录计数。

技术验证
将初始提取的数据加载到 Amazon Redshift 后,您必须并行执行数据验证测试。此阶段的目标在于验证生产工作负载,以将来自相同输入的 Greenplum 和 Amazon Redshift 输出进行比较。
此阶段涵盖的典型活动如下:
- 每个表上的对象和行计数。
- 比较迁移的所有表在 Greenplum 和 Amazon Redshift 中的相同随机数据子集,以逐行验证该数据完全相同。
- 检查是否存在不正确的列编码。
- 识别不均匀的表数据。
- 标注没有从排序键中受益的查询。
- 识别不恰当的加入基数。
- 使用包含大型 VARCHAR 列的表进行识别。
- 确认连接目标环境时进程没有崩溃。
- 验证每日批处理作业(作业持续时间、处理的行数)。要查找执行其中大多数活动的正确技巧,请参阅 Amazon Redshift 的十大性能调整技巧
- 通过 Amazon Redshift Advisor 设置 Amazon Redshift 自动提醒
业务验证
成功迁移数据并验证数据移动后,剩下的最后一项任务是让数据仓库用户参与验证过程。这些来自公司不同业务部门的用户使用各种工具和方法访问数据仓库:JDBC/ODBC 客户端、Python 脚本、自定义应用程序等。在执行最终切换之前确保每位最终用户都验证并调整了该流程,以便与 Amazon Redshift 无缝写作,这是迁移的核心。
此阶段可能包括以下几项任务:
- 调整业务用户的工具、应用程序和脚本,以连接到 Amazon Redshift 端点。
- 修改用户的数据加载和转储过程,将通过 ODBC/JDBC 往返于共享存储的数据移动替换为往返于 Amazon Simple Storage Service (Amazon S3) 的 COPY 和 UNLOAD 操作。
- 修改任何不兼容的查询,以考虑 Amazon Redshift 与 PostgreSQL 之间的任何实施差别。
- 根据 Greenplum 和 Amazon Redshift 运行业务流程,并比较结果和运行时间。务必将任何问题或意外结果通知负责迁移的团队,以便对案例进行详细分析。
- 调整查询性能,以考虑表分配和排序键,并广泛使用 EXPLAIN 命令以便了解 Amazon Redshift 如何计划和运行查询。有关高级表设计概念,请参阅 Amazon Redshift Engineering 的高级表设计手册:序言、先决条件和优先级。
此业务验证阶段非常关键,因此,所有最终用户都需协调一致,为最终的切换做好准备。请遵循 Amazon Redshift 最佳实践,使最终用户能够充分利用其新数据仓库的功能。在针对 Amazon Redshift 执行所有迁移验证任务,连接和测试每个 ETL 作业、业务流程、外部系统和用户工具后,您便可断开所有进程与旧数据仓库的连接,现在可以安全地关闭和停用旧数据仓库了。
结论
在本文中,我们提供了使用 AWS SCT 从 Greenplum 迁移到 Amazon Redshift 的详细步骤。尽管本文描述了云仓库现代化及向其迁移,但您应该将这个转型过程扩展到成熟的现代数据架构。AWS 云支持多个使用案例,使您能够更加以数据为导向。对于现代数据架构,您应该使用有针对性的数据存储,例如 Amazon S3、Amazon Redshift、Amazon Timestream,以及其他基于您使用案例的数据存储。
请参阅本系列的第二篇文章,在其中,我们将介绍有关数据类型、函数和存储过程的规范性指导。
关于作者
 Suresh Patnam 是 AWS 的首席解决方案架构师。他热衷于帮助各种规模的企业转型为快速发展的数字组织,专注于大数据、数据湖和 AI/ML。Suresh 拥有杜克大学福库商学院工商管理硕士学位和密苏里州立大学 CIS 硕士学位。闲暇时,Suresh 喜欢打网球,陪伴家人。
Suresh Patnam 是 AWS 的首席解决方案架构师。他热衷于帮助各种规模的企业转型为快速发展的数字组织,专注于大数据、数据湖和 AI/ML。Suresh 拥有杜克大学福库商学院工商管理硕士学位和密苏里州立大学 CIS 硕士学位。闲暇时,Suresh 喜欢打网球,陪伴家人。
 Arunabha Datta 是Amazon Web Services (AWS) 高级数据架构师。他与客户和合作伙伴合作,使用 AWS Analytics 服务架构和实施现代数据架构。闲暇时间,Arunabha 喜欢摄影,陪伴家人。
Arunabha Datta 是Amazon Web Services (AWS) 高级数据架构师。他与客户和合作伙伴合作,使用 AWS Analytics 服务架构和实施现代数据架构。闲暇时间,Arunabha 喜欢摄影,陪伴家人。