亚马逊AWS官方博客
事半功倍:从事务性批处理转向有状态批处理
亚马逊每天处理来自一百多个不同商业实体的数亿笔金融交易,包括应收账款、应付账款、特许权使用费、摊销和汇款。所有这些数据都发送到电子商务金融一体化(eCFI)系统,它们在该系统中记录在子分类帐中。
旧式架构
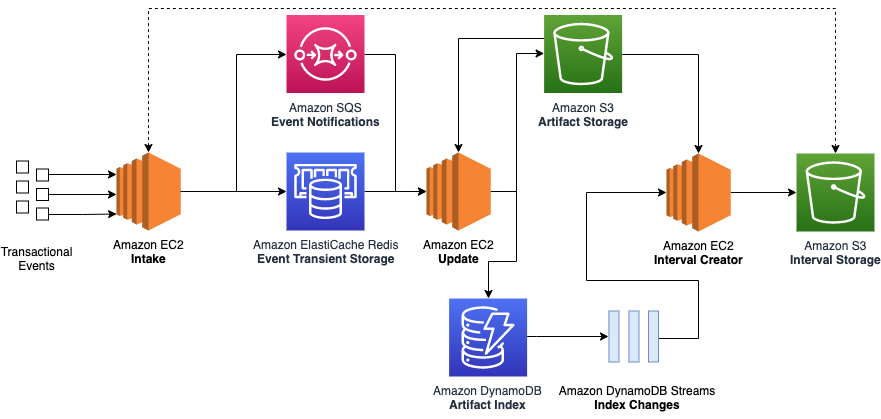
我们的旧式架构主要利用 Amazon Elastic Compute Cloud(Amazon EC2)将相关的财务事件分组为有状态的构件。但是,有状态构件会引用任何持久性构件,例如数据库条目或 Amazon Simple Storage Service(Amazon S3)对象。
我们发现这种方法在以下方面存在缺陷:
- 成本 – 每天在 Amazon S3 中单独存储数亿个财务事件会导致产生较高的 I/O 和 Amazon EC2 计算资源成本。
- 数据完整性 – 不同的事件以不同的速度流经系统。例如,虽然单个客户订单的小型有状态构件可以在几秒钟内记录下来,但包含一百万件的散装货件的有状态构件可能需要几个小时才能完全更新。这使得我们很难知道是否在给定的时间范围内处理了所有数据。
- 复杂的重试机制 – 使用单个网络调用在旧式系统之间传递财务事件,并且事件陷于回退重试策略中。尽管如此,网络超时、流量限制或流量高峰仍可能导致某些事件出错。这就要求我们构建一个单独的服务,以便标出、管理并在以后重试有问题的事件。
- 可扩展性 – 当不同的事件竞相更新同一个有状态构件时,会出现瓶颈。这会导致过多的重试或冗余更新,并随着系统的发展,使其成本效益降低。
- 运营支持 – 使用专用 EC2 实例意味着我们需要花费宝贵的开发时间来管理操作系统修补、处理主机故障和安排部署。
下图展示了我们的旧式架构。
演变是关键
我们的新架构需要解决这些缺陷,同时保留我们服务的核心目标:根据进来的财务事件更新有状态的构件。在我们的例子中,有状态构件指的是用于对账的一组相关财务事务。我们在堆栈演变时考虑了以下事项:
- 无状态和有状态分离
- 尽量减少端到端延迟
- 可扩展性
无状态和有状态分离
在我们的事务系统中,每个摄入的事件都会导致对有状态构件进行更新。当同一个有状态的构件同时出现成千上万的事件时,这就成了一个问题。
但是,通过摄入数据批次,我们有机会创建单独的无状态和有状态处理组件。无状态组件对输入批次执行初始缩减操作,以便将相关事件分组在一起。这意味着我们系统的其余部分可以在这些较小的无状态构件上运行,并执行更少的写入操作(更少的操作意味着更低的成本)。
然后,有状态组件会将这些无状态构件与现有的有状态构件连接起来,以生成更新的有状态构件。
举个例子,想象一下,一家在线零售商突然收到了某个热门商品的数千个订单。我们可以先生成一个汇总最新购买量的单个无状态构件,而不是更新商品数据库条目数千次。现在可以使用无状态构件一次性更新商品条目,从而减少了更新瓶颈。下图展示了此流程。

尽量减少端到端延迟
与传统的提取、转换和加载(ETL)任务不同,我们不想每天甚至每小时执行一次数据提取。我们的会计师需要能够在数据到达系统后的几分钟内访问更新的有状态构件。例如,如果他们手动发送了修正线,他们希望能够在同一小时内检查他们的调整是否对目标有状态构件产生了预期的效果,而不是等到第二天。因此,我们专注于通过将有状态组件的各个任务分解为子组件,尽可能地并行处理传入的数据批次。每个子组件可以彼此独立运行,这使我们能够以装配线形式处理多个批次。
可扩展性
无状态组件和有状态组件都需要对不断变化的流量模式和可能的输入批次积压作出反应。我们还希望整合无服务器计算,以便更好地对扩展作出响应,同时减少维护实例机群的开销。
这意味着我们不能简单地在输入批次和无状态构件之间进行一对一的映射。相反,我们在服务中融入了灵活性,因此无状态组件可以自动检测输入批次的积压,并将多个输入批次组合到一个任务中。类似的积压管理逻辑也应用于有状态组件。下图展示了此流程。

当前架构
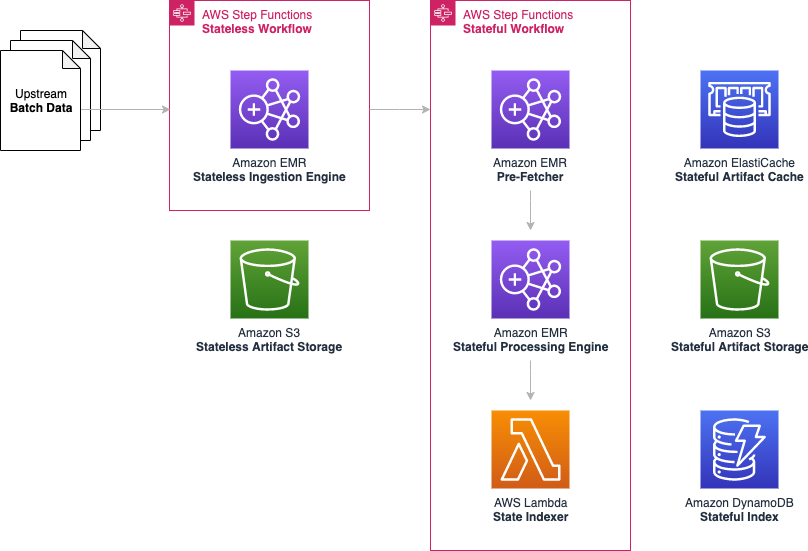
为了满足我们的需求,我们结合了多个 AWS 产品:
- AWS Step Functions – 编排我们的无状态和有状态工作流
- Amazon EMR – 对我们的无状态和有状态构件进行 Apache Spark 操作
- AWS Lambda – 有状态构件索引和编排积压管理
- Amazon ElastiCache – 优化 Amazon S3 请求延迟
- Amazon S3 – 我们的无状态和有状态构件的可扩展存储
- Amazon DynamoDB – 无状态和有状态的构件索引
下图展示了我们的当前架构。
下图显示了我们的无状态和有状态工作流。

下面的 GitHub 存储库中提供了用于呈现此架构的 AWS CloudFormation 模板和相应的 Java 代码。
无状态工作流
我们在长时间运行的 Amazon EMR 集群上使用了 Apache Spark 应用程序,以便同时摄入输入批次数据并执行缩减操作,生成无状态构件和相应的索引文件,供有状态处理使用。
我们之所以选择 Amazon EMR,是因为它具备在生产环境中久经考验的高可用性数据处理能力,而且还可以在流量负载增加时横向扩展。最重要的是,与自我管理的集群相比,Amazon EMR 具有更低的成本和更好的运营支持。
有状态工作流
每个有状态工作流都执行使用无状态构件创建或更新数百万个有状态构件的操作。与无状态工作流类似,所有有状态构件都存储在 Amazon S3 中的少量 Apache Spark 段文件中。仅此一项就大大降低了成本,因为我们显著减少了 Amazon S3 的写入次数(同时使用了相同的总存储量)。例如,使用事务性旧式架构存储 1000 万个单独的构件时仅在 PUT 请求方面就需要花费 50 美元,而 10 个 Apache Spark 段文件在 PUT 请求方面的成本仅为 0.00005 美元(按每 1000 个请求为 0.005 美元计算)。
但是,因为任何有状态构件都可能在将来的任何时候更新,我们仍然需要一种方法来检索单个有状态构件。为此,我们转向 DynamoDB。DynamoDB 是一个完全托管式且可扩展的键值和文档数据库。因为我们希望使用其唯一标识符作为主键来索引有状态输出文件中每个有状态构件的位置,所以它非常适合我们的访问模式。我们使用 DynamoDB 为有状态输出文件中每个有状态构件的位置建立索引。例如,如果我们的构件表示订单,我们将使用订单 ID(具有高基数)作为分区键,并将每个订单的文件位置、字节偏移量和字节长度存储为单独的属性。通过在 Amazon S3 GET 请求中传递字节范围,我们现在可以提取单个有状态构件,就好像它们是独立存储一样。我们不太关心优化 Amazon S3 GET 请求的数量,因为 GET 请求比 PUT 请求便宜 10 倍以上。
总体而言,这种有状态逻辑分为三个连续子组件,这意味着三个独立的有状态工作流可以在任何给定时间运行。
预取器
下图展示了我们的预取器子组件。

预取器子组件使用无状态索引文件来检索应该更新的现存有状态构件。这些可能是同一客户订单以前出的货,或者是同一仓库过去的库存变动。为此,我们再次转向 Amazon EMR 来执行这个高吞吐量提取操作。
每次提取都需要一个 DynamoDB 查找和一个 Amazon S3 GET 部分字节范围请求。由于有大量的外部调用,因此使用 Apache Spark flatMap 操作中包含的线程池对提取进行了高度并行化。预取的有状态构件整合到一个输出文件中,该文件随后用作有状态处理引擎的输入。
有状态的处理引擎
下图展示了有状态处理引擎。

有状态处理引擎子组件将预取的有状态构件与无状态构件连接起来,以在应用自定义业务逻辑后生成更新的有状态构件。更新后的有状态构件写入多个 Apache Spark 段文件。
由于有状态构件可能已经在预取(也称为进行中的更新)的同时对其进行索引,因此有状态处理器还会加入最近处理过的 Apache Spark 段文件。
在此我们再次使用 Amazon EMR 来利用 Apache Spark 操作,这是连接无状态和有状态构件所必需的。
状态索引器
下图展示了状态索引器。

这个基于 Lambda 的子组件在 DynamoDB 的有状态段文件中记录每个有状态构件的位置。状态索引器还会在 Amazon ElastiCache for Redis 集群中缓存有状态构件,以提升预取器执行的 Amazon S3 GET 请求的性能。
但是,即使使用线程池,单个 Lambda 函数的功能也不够强大,无法在 15 分钟的时间限制内为数百万个有状态构件建立索引。作为替代,我们采用一个 Lambda 函数集群。状态索引器从单个协调器 Lambda 函数开始,确定所需的工作线程函数的数量。例如,如果有状态处理引擎生成了 100 个段文件,则协调器可能会为要处理的 20 个 Lambda 工作线程函数中的每一个分配五个段文件。此方法具有很高的可扩展性,因为我们可以根据需要动态分配更多或更少的 Lambda 工作线程。
然后,每个 Lambda 工作线程都以多线程方式为每个分配的段文件中的所有有状态构件执行 ElastiCache 和 DynamoDB 写入。协调器函数监视每个 Lambda 工作线程的运行状况,并根据需要重新启动工作线程。

编排
我们使用 Step Functions 来协调每个无状态和有状态工作流,如下图所示。

每次运行新的工作流步骤时,都会通过 Lambda 函数将该步骤记录在 DynamoDB 表中。此表不仅维护了有状态批次的运行顺序,而且还形成了积压管理系统的基础,该系统指示无状态摄入引擎根据积压情况将更多或更少的输入批次分组在一起。
我们之所以选择 Step Functions,是因为它与许多 AWS 服务(包括通过 Amazon CloudWatch 计划事件规则触发和添加 Amazon EMR 步骤)原生集成,并且内置了对回退重试和复杂状态机逻辑的支持。例如,我们根据错误类型定义了不同的回退重试率。
结论
我们基于批次的架构帮助我们克服了最初打算解决的事务处理限制:
- 降低成本 – 每个 EMR 集群只需使用三到四个核心节点,我们就能够扩展到每天数以千计的工作流和数亿个事件。与类似的事务系统相比,这使我们的 Amazon EC2 使用量减少了 90% 以上。此外,写出批次而不是单个事务可使 Amazon S3 PUT 请求数减少 99.8% 以上。
- 数据完整性保证 – 由于每个输入批次都与一个时间间隔相关联,因此当一个批次处理完成时,我们知道该时间间隔内的所有事件都已完成。
- 简化的重试机制 – 批次处理意味着在批处理级别出现失败,并且可以通过工作流直接重试。由于批次数量远少于事务量,批次重试更易于管理。例如,在我们的服务中,一个典型的批次包含大约 200 万个条目。在服务中断期间,只需要重试一个批次,而旧式架构则需要重试两百万个单独的条目。
- 高可扩展性 – 如果我们检测到流量增加,我们可以轻松地动态扩展 EMR 集群,这给我们留下了深刻的印象。使用 Amazon EMR 实例机群还有助于我们自动选择不同可用区中最经济高效的实例。我们还喜欢我们基于 Lambda 的状态索引器所实现的性能。这个子组件不仅可以在没有人为干预的情况下动态扩展,而且具有令人惊讶的成本效益。我们的使用量中有很大一部分属于免费套餐范围。
- 卓越运营 – 使用 Lambda 等无服务器组件取代传统的主机,使我们能够减少在合规性工单上花费的时间,而把更多的精力放在为客户提供功能上。
我们对于投资从基于事务的系统转向批处理系统感到特别兴奋,尤其是我们从使用 Amazon EC2 转向使用无服务器 Lambda 和大数据 Amazon EMR 服务。这一经验表明,即使是最初基于 AWS 构建的服务,也可以通过重新思考 AWS 服务的使用方式来降低成本和提高性能。
受我们进步的鼓舞,我们的团队正在着手用无服务器组件取代许多其他旧式服务。同样,我们希望其他工程团队能够吸取我们的经验教训,继续创新,用更少的资源做更多的事情。
在以下 GitHub 存储库中找到本博文所用的代码。
特别感谢开发团队:Ryan Schwartz、Abhishek Sahay、Cecilia Cho、Godot Bian、Sam Lam、Jean-Christophe Libbrecht 和 Nicholas Leong。