亚马逊AWS官方博客
如何使用 Apache Spark 与 Amazon EMR 改善 FRTB 的内部模型方法实现
《交易账户根本审查》(FRTB)是巴塞尔银行监管委员会针对银行市场的风险资本计算提出的一套建议方案。这套新的规则(通常被称为「巴塞尔协议IV」)旨在建立更具弹性的市场,并充分捕捉高压力市场条件下的风险因素。这项协议最初于2016年1月发布,并于2019年1月进行了修订。FRTB目前的生效日期暂定为2023年1月1日。
FRTB提出了两种用于交易账户内资本的计算方法:标准方法(SA)与内部模型方法(IMA)。目前整个行业的共识是:与SA相比,IMA对资本储备的影响较小,但实施难度则更高。在本文中,我们将深入探讨如何使用Amazon EMR for Apache Spark打造一套具备可扩展性、灵活性与理想经济效益的FRTB IMA运行平台。
为什么选择云平台运行IMA?
为了符合IMA的要求,银行的日终(EOD)市场风险系统需要保证其前台报告的准确率达到95%或者更高。为了实现这项目标,此类平台必须做出更多核算与调整。具体来讲,风险系统需要对各类市场冲击因素进行建模,并绘制出整个交易系统中的所有风险因素。所有这些过程都对EOD计算能力提出更高的要求。最后,由于需要对每个部门分别进行IMA,因此产生的数据量以及随之而来的分析与报告强度将大大增加。
具体来看,IMA集中式计算在每个工作日的特定数小时时段内往往会出现算力需求峰值(达到常规时段的3到5倍,甚至更高)。传统基础设施很难实现这样的增长,而云正是处理规模庞大、且在特定时段内快速波动的数据的理想选项。
本地网格设施在这方面则有着三大显著短板:
- 几乎所有资产组合评估都需要大规模算力以应对建模运算,因此使用本地网格支持FRTB的银行需要为配置容量投入更为可观的前期资本支出。
- 大多数本地网格只提供固定或标准的硬件类型,这不仅限制了灵活性,也导致银行面对丰富多样的IMA特征时、只能使用几种定量模型。
- 由于FRTB计算需要在几个小时之内完成,因此充裕的算力配置在一天内的大多数时段下完全处于闲置,这将导致资源利用率极为低下。
AWS提供计算、存储及数据库工具与服务,可帮助银行客户轻松调整计算容量,进而大规模、快速地存储文件与对象。这种计算规模调整能力与AWS提供的全面风险与压力测试功能,则在保障安全的同时带来良好的成本效益。金融机构可以针对不同的工作负载混合及搭配超过200种实例类型,并访问几乎无限的存储资源。
本文调查了将Amazon EMR用作FRTB IMA计算平台的实际情况,下图所示为用例中选择的特定Amazon EMR架构。
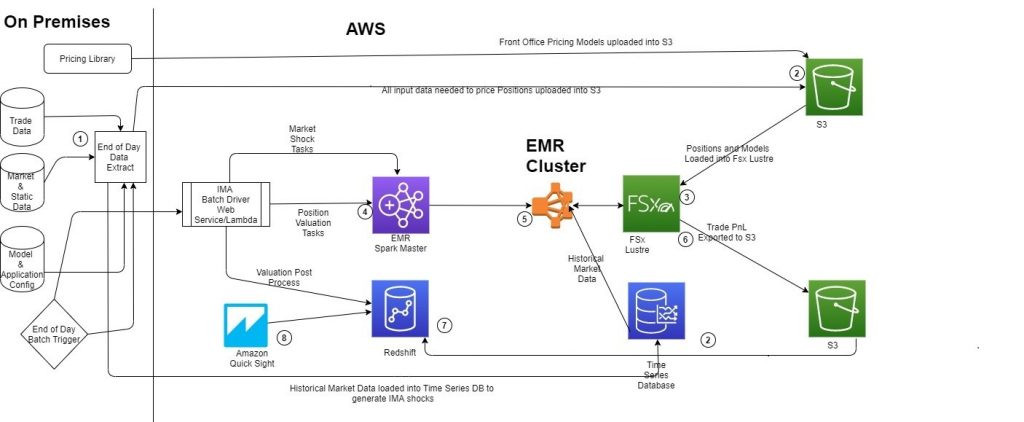
架构示意图:步骤顺序
- 本地日结触发器首先提取头寸、市场、模型与静态数据。
- 数据提取流程将头寸、市场、模型与静态数据上传至Amazon S3。
- 创建Amazon EMR for Apache Spark集群。各工作节点将FSxfor Lustre映射至S3存储桶(来自第2步)。各工作节点还将接入时序数据库。
- 调用IMA批处理驱动程序(Web服务或AWS Lambda进程)。批处理驱动程序创建计算任务,并将任务提交至Spark主节点。
- Spark工作节点将历史市场数据上传至该时序数据库,而后开始处理实际计算任务。
- 工作节点将PnL保存至FSx Lustre目录。一旦Spark作业处理完成,Amazon FSx目录将被导出至Amazon S3。
- 将PnLs从Amazon S3加载至Amazon Redshift。Amazon Redshift为各业务部门、办公室以及法人实体生成聚合PnL,并计算预期短缺结果。
- Amazon QuickSIght加载数据集并显示报告。
在这种“以数据为中心”的高性能计算(HPC)方案当中,各个投资组合/账户都将映射至一个独立的Amazon EMR节点,所需的计算任务将在这些节点上并行运行。而后,各PnL结果将被进一步汇总为交易账户以计算预期PnL与短缺结果。请注意,如果使用的是基于蒙特卡洛模拟的模型(而非本文中探讨的示例),则将产生生成基础流程的模拟路径(例如Equity Index SPX价格),而后利用这些模拟价格在各个Amazon EMR节点上为所有衍生产品定价(例如期权)。
解决方案亮点
Amazon EMR是一套行业领先的云大数据平台,可使用多种开源工具(Apache Spark, Apache Hive, Apache HBase, Apache Flink, Apache Hudi, 以及Presto)处理大量数据。借助Amazon EMR,您能够以不到传统本地解决方案一半的成本运行PB级分析,且速度比标准Apache Spark快三倍以上。对于短期运行的作业,您可以对集群进行纵向规模伸缩,并为实际使用的实例按秒支付费用。对于长期运行的工作负载,您也可以创建具备高可用性的自动伸缩集群以满足业务需求。
Amazon Elastic Compute Cloud (Amazon EC2)提供超过200种实例类型供您选择,这些实例类型经过针对性优化以适应不同的用例需求。如此强大的灵活性,意味着您可以根据性能、成本以及可用性需求做出明智选择。例如,某些批处理作业 需要在特定的小时数内完成以生成监管报告,则组织可以选择使用Amazon EC2预留实例在生产环境中运行FRTB。而在开发与测试方面,组织则可选择使用各类Amazon EC2竞价实例以优化计算成本。
在本文中,我们选择了Amazon EC2 m5.24xlarge作为主实例。最佳实践是建议大家将预留或者按需实例作为Amazon EMR主实例。而在工作节点(Spark executors
)方面,我们则建议使用Amazon EC2竞价实例以优化计算成本。
最后,还建议大家配置Amazon EMR instance fleet以充分利用多种多样的配置选项。
Amazon S3是一项对象存储服务,能够提供行业领先的可扩展性、数据可用性、安全性与性能表现。Amazon S3在设计上拥有99.999999999(11个9)的持久性,且集成有支持风险数据存储的安全功能并提供近乎无限的存储容量。
FSx for Lustre是目前最受欢迎的高性能文件系统。它提供全托管选项,能够与Amazon S3相集成,并针对机器学习、高性能计算以及财务建模等需要快速处理的工作负载进行了优化。在接入S3存储桶之后,Fsx for Lustre文件系统将把Amazon S3对象透明显示为文件形式,并允许大家将更改的数据写入回Amazon S3当中。
与Hadoop分布式文件系统(HDFS)等共享文件系统相比,Amazon FSx在处理大量小型文件(例如头寸PnLs数组)的写入操作时性能表现更好。Amazon FSx的另一大优势,则是支持可移植操作系统接口(POSIX),因此任何定价库/供应商模型只需要遵守POSIX标准即可与之匹配,无需进行重构。
解决方案模型详细信息
在我们的概念验证应用程序当中,我们选择了两种计算期权的方法,用于演示不同方法之间的差异:
- 经典布莱克-舒尔斯模型:虽然在计算美式期权价格时存在一定限制,但这种经典模型仍然得到广泛应用与充分认可。


- 朗斯特夫-施瓦茨(Longstaff Schwartz,简称LS)模型:使用几何布朗运动(GBM)模拟最长5年周期之内(共60个月点)中每个月的股票价格。这种模型得出的结果更准确,但占用的CPU资源也更多。
- 将蒙特卡洛路径的数量设置为10000。
- 在实际生产场景中,某些实现可能使用2万或10万条路径运行,这会显著增加CPU运行时间。
- 计算过程如下所示:


-
-
- St 在t条件下模拟价格
- r 在t条件下计算无风险利率
- 条件下的σ波动率(非随机)
- wt 布朗运动
- 我们使用GBM的第二种形式以模拟股票价格。
- 我们使用2因子基函数进行运动决策。

-

-
- yt 为内在值→ min (Strike -St, 0)。
- 在10000个蒙特卡洛路径中,我们仅采用yt 不为0的路径。
相较于LS模型,布莱克-舒尔斯模型方法采用封闭形式(即使用有限数量的标准运算进行表示的数学表达式),因此其运行时间也要比LS模型短得多。
解决方案结果
我们在200万个头寸上,使用快速模型(布莱克-舒尔斯)与慢速模型(LS)配合相同投资组合时的运行时长。下表整理出不同实例类型与虚拟CPU(vCPU)组合下的时长结果。
| 实例类型 | vCPU/实例 | 实例个数 | 布莱克-舒尔斯模型 | LS模型 |
| c4.8xlarge | 36 | 100 | 50 秒 | 640 秒 |
| c4.8xlarge | 36 | 200 | 28 秒 | 435 秒 |
| c5.9xlarge | 36 | 100 | 20 秒 | 600 秒 |
| c5.9xlarge | 36 | 200 | 14 秒 | 400 秒 |
| c5.24xlarge | 96 | 100 | 47 秒 | 440 秒 |
| c5.24xlarge | 96 | 200 | 27 秒 | 280 秒 |
| c5.24xlarge | 96 | 40 | 30 秒 | 760 秒 |
| c5n.xlarge | 4 | 100 | 50 秒 | 1740 秒 |
| c5n.18xlarge | 72 | 20 | 53 秒 | 2560 秒 |
下图使用上表内的数据绘制而成。其中x轴代表总vCPU数量(vCPU/实例 x 实例数量),y轴则代表运行时长。

从图中,我们可以得出以下结论。对于LS算法,可以看到运行时长随着vCPU的增加而减少(呈指数级衰减,而非线性降低)。与之形成鲜明对比的是,对于运行时间本就较短的布莱克-舒尔斯模型,添加vCPU并不会带来明显的性能提升效果——结果的分散化可能源自所选实例类型集的函数。在使用相同的总vCPU数量时,布莱克-舒尔斯模型仍然存在多个运行时长点,因此基本可以支持这项假设。从表中可以看到,新型实例在执行分析负载时花费的时间更短。
时间与成本分析
上一节中介绍了在200万个头寸上,不同实例类型与vCPU搭配下的计算运行时长。
在这里,我们使用200个C5.24xlarge实例作为参考,反映整体FRTB运行一整天的实际运算量。这里我们还决定选择LS模型——这是因为此模型的CPU占用量更高,因此时间估算结果将更接近包含200万个蒙特卡洛类型模拟衍生头寸的最大计算时间(更接近于实际FRTB的运行情况)。
对于LS模型,运行时间为280秒,大约是5分钟。配合一年的历史数据(约250个交易日)以及4项风险因素(以股票期权为例,包括基本估值、部分股权估值、利率以及波动率),每个头寸的总体计算需求量为250 x 4 = 1000个估值/头寸。
以此为基础,可以看到使用选定集群规模时,总体运行时间为5分钟 x 1000,大概是85个小时。这种批量计算周期实在太长,所以我们需要选择规模更大的计算集群。
如果将完成FRTB批处理作业的目标时长设定为5个小时,那么我们需要85小时/5小时 = 17套集群(每个集群包含200个C5.24xlarge实例)。其中各个集群都可以独立运行(例如按办公室、业务部门或者区域划分)。
如上表所示,在运行布莱克-舒尔斯模型时,运行时间将显著缩短。结果就是,根据投资组合中头寸的类型与模型复杂度(计算任务质量),运行时间与成本都将有所区别。
扩展资源: Amazon EC2实例计费标准与Amazon EMR计费标准。
AWS的优势
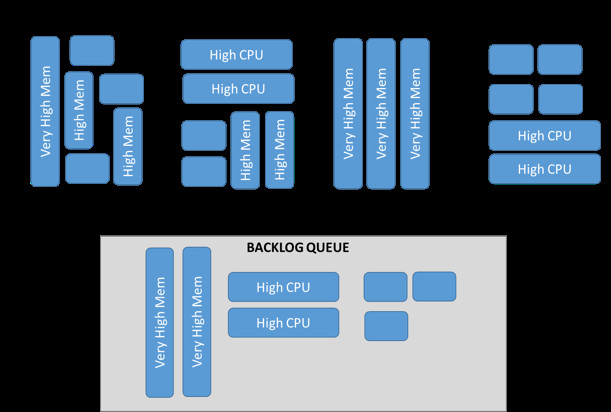
1. 多工作负载网格对单工作负载网格
组织通常使用公共网格处理本地上的不同工作负载,这可能导致工作量严重积压。另外,大多数本地网格只采用固定或标准的硬件类型,因此会大大限制灵活性空间。在AWS上,客户可以针对特定工作负载对每个网格进行优化。
| 本地 | vs. | AWS |
| 由于不同类型的工作负载共同使用同一公共网格,因此将导致工作量严重积压。 | 由于不同类型的工作负载使用不同类型的网格,因此可消除积压队列并优化网格资源使用。 | |
 |
 |
|
| 现有本地部署网格在峰值时段(市场关闭后)以最大容量运行。为了实现FRTB,银行需要采购大规模硬件容量,且这部分容量几乎只能遵循统一的实例类型。这不仅会降低成本效益,同时也会影响需要多种资源配伍形式(例如CPU、内存、I/O密集度或者GPU)的定价及定量模型的实际运行效率。例如,利率掉期及信用违约掉期等金融产品需要使用的CPU核心数量很低,CDX分期付款等一篮子金融产品则需要占用大量CPU资源。另外,在资产或抵押担保证券类负载中,系统需要将大量文件加载至内存当中,因此内存容量就成了决定性能的核心因素。 | 与本地网格不同,AWS客户无需为所有工作负载指定相同的固定类型集群。AWS客户可以选择多种实例类型,并根据模型类型与目标运行时长变更资源组合,借此响应头寸与模型层面的变化。Amazon EC2提供广泛的实例类型选项,这些实例类型皆经过优化,能够充分适合从CDX发行到关联产品再到资产与抵押担保证券等不同用例。这些实例类型涵盖多种CPU、内存、存储与网络容量组合,充分强调资源组合的灵活性。另外,每种实例类型都对应一种或者多种实例大小,能够更好地根据目标工作负载进行资源规模伸缩。 |
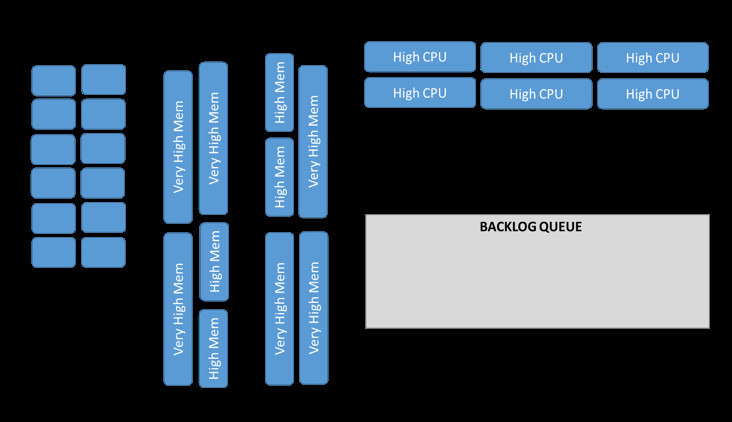
2. “长尾”任务引发的过度配置
金融工具在定价与风险核算批处理任务中往往包含大量短期任务与少量长期任务——这就造成了所谓“长尾”任务。在长期阶段,网格容量将无法得到充分利用。在AWS上,客户能够动态配置计算资源,保证为长时间运行的任务配备一套规模较小的稳定网格。
| 本地 | vs. | AWS |
 |
  |
|
| 针对不同工作负载提供不同网格类型的另一大优势,在于极大提升定价网格中常见的“长尾”任务的处理效果。由于本地部署网格往往由不同类型的定量模型进行共享,因此运行时间较长的任务往往会长期占用网格并导致资源发生益。 |
在AWS上,我们可以对各个集群进行优化与规模调整,并将其与特定工作负载类型对应起来。
|
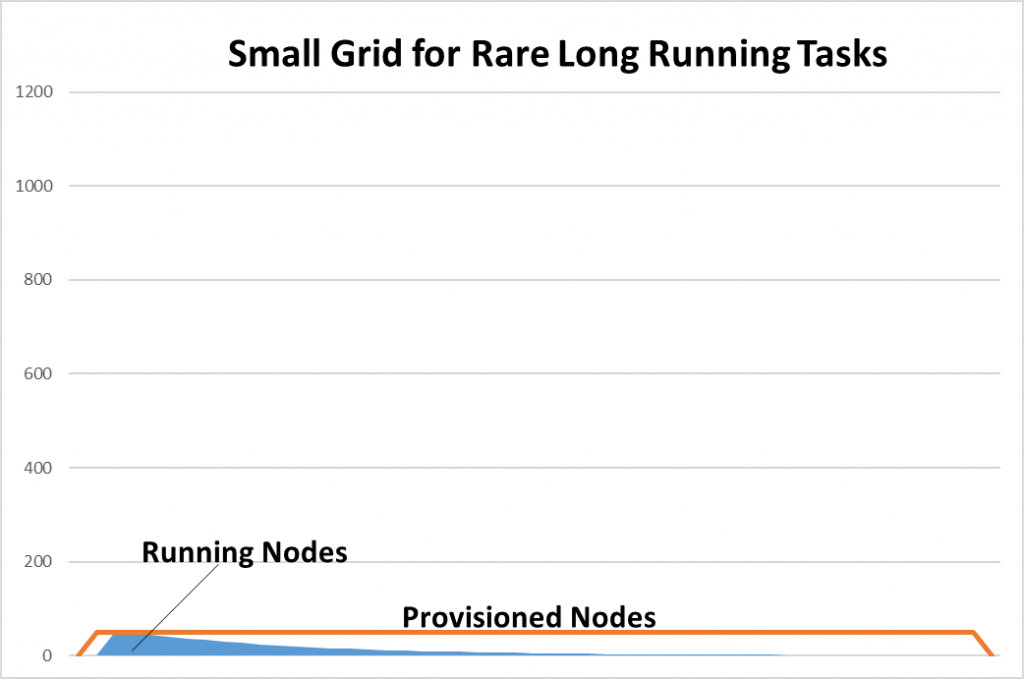
3. 24×7置备,真正的峰值却只有几个小时
在典型的定价与风险核算网格当中,大部分批处理运行任务只发生在一天内的几个小时当中。
| 本地 | vs. | AWS |
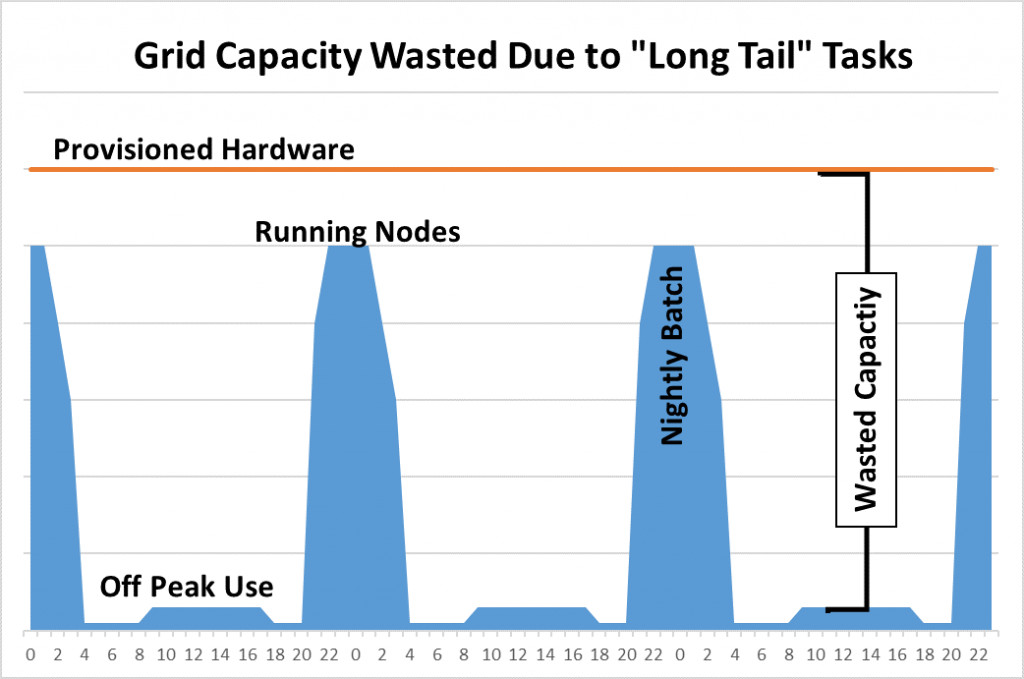 |
 |
|
| 本地网格的容量采取预先置备形式,意味着即便不加使用,这些网格容量也将始终存在。 | 通常,批处理任务在一天之内只需要运行几个小时,这也是AWS适合运行网格的另一个重要原因。在AWS中,客户可以使用即时容量。网格容量仅在FRTB批处理运行周期内存在,在运行完成之后,集群即告关闭。 | |
|
由于本地网格容量是固定的,因此一旦在批处理过程中发现问题(例如输入数据有误),也几乎无法重新运行批处理。
|
由于AWS资源具有弹性,因此可以轻松实现批处理的重新运行。通常,每个办公室都可以计算风险指标(预期短缺/VaR),而无需等待其他办公室完成其对应的计算任务。 |
4. 高安全性
AWS非常了解金融机构在全球范围内需要承担的独特安全性、法规与合规性义务。因此,AWS在从基础设施到自动化的各个层面上为金融机构提供完备的合规与安全工具与资源。AWS在目前24个在线区域的76个可用区内提供最广泛的全球服务覆盖规模。
AWS网络高度关注对客户信息、身份、应用程序以及设备的保护。AWS通过全面的服务与功能帮助客户满足核心安全性与合规性要求,例如数据本地性、保护与保密性等等。客户可以在自己的虚拟专有云(VPC)中运行Amazon EMR,保证其集群与其他VPC内的其他应用程序彻底隔离开来。Amazon EMR还支持对静态及传输数据进行加密。Amazon S3与各集群节点间的流量将通过传输层安全(TLS)协议加密。此外,大家也可以使用服务器端或者客户端加密机制对Amazon S3中的静态数据进行加密。
我们强烈建议客户在指定有私有子网的VPC上运行Amazon EMR集群,防止来自互联网的集群访问活动。Amazon S3数据将由VPC终端节点直接访问,保证没有任何数据离开AWS网络。
| 本地 | vs. | AWS |
 |
 |
5. 运行成本低于本地网格
最后,管理大型本地网格将占用大量资源。除了硬件采购之外,持续的维护与修复也会进一步增加成本、时间与精力投入。AWS提供多种成本与时间优化方案。AWS Managed Services代表客户运营AWS基础设施,并可自动执行诸如变更请求、监控、补丁管理、安全性保障以及备份服务等常见操作。
扩展资源: AWS总体拥有成本计算器
总结
在进行设计优化的过程中,我们注意到以下重要观察结果:
- 每种模型与工作负载类型都拥有一类最优集群大小。创建超大规模集群也无法实现运行时长的线性缩短。
- YARN(资源管理器)也能够实现集群优化。手动设置执行程序与核心执行程序的数量,不会给运行时长造成显著影响。
- 保证分区数相当于虚拟核心数量的2到4倍。不同分区大小对于运行时长的影响并不明显。
- 后续调优包括消除长尾难题以实现进一步资源优化。另外,大家可以考虑保存各个头寸的计算时间并据此在下次运行时重新分区头寸数据,尽可能保证所有分区花费相同的运行时长。
随着金融机构积极拥抱FRTB,AWS提供的定性式解决方案将帮助更多组织满足愈发严苛的业务需求。凭借着AWS出色的弹性与速度表现,金融机构可以更快地响应新的、更复杂的法规要求。我们参考实例展示了金融机构如何实际使用AWS计算、存储以及其他服务资源。