亚马逊AWS官方博客
新增 — 将 Amazon S3 对象 Lambda 与 Amazon CloudFront 结合使用,为最终用户量身定制内容
借助 S3 Object Lambda,您可以使用自己的代码处理在 Amazon S3 返回到应用程序时从 Amazon S3 检索到的数据。随着时间的推移,我们为 S3 Object Lambda 添加了新功能,例如能够向 S3 HEAD 和 LIST API 请求添加自己的代码,此外还支持在启动时提供的 S3 GET 请求。
今天,我们要为 S3 Object Lambda 接入点启动别名。现在,别名会在创建 S3 Object Lambda 接入点后自动生成,并且可以在您使用存储桶名称访问 Amazon S3 中存储的数据的任何位置与存储桶名称互换。因此,您的应用程序不需要了解 S3 Object Lambda,可以将别名视为存储桶名称。
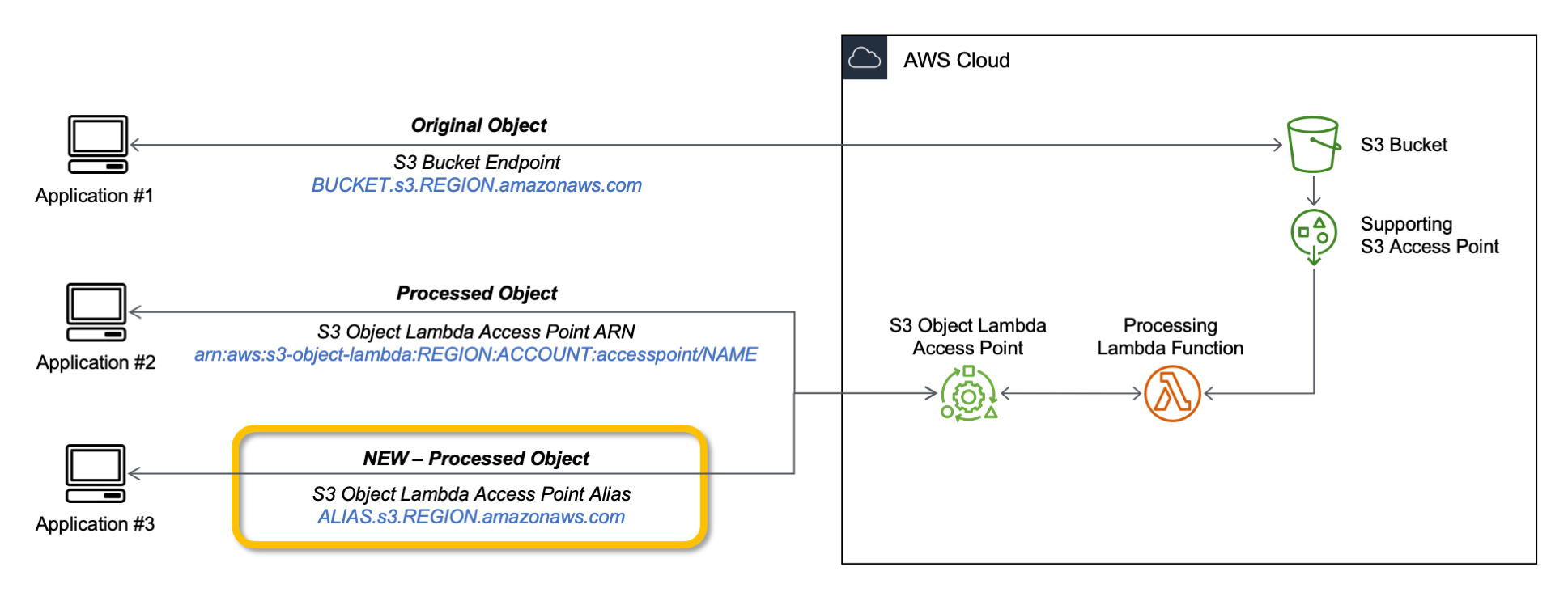
现在,您可以使用一个 S3 Object Lambda 接入点别名作为 Amazon CloudFront 分布的源,为最终用户量身定制或自定义数据。您可以使用它来实现自动调整图像大小,或者在下载内容时对其进行标记或注释。许多图像仍使用较旧的格式,如 JPEG 或 PNG,您可以使用转码功能以更高效的格式交付图像,如 WebP、BPG 或 HEIC。数字图像包含元数据,您可以实现去除元数据的功能,以帮助满足数据隐私要求。
我们来看看这些步骤的实际操作。首先,我将使用文本展示一个简单的示例,您只需使用 AWS 管理控制台即可遵循该示例。之后,我将实现更高级的使用案例处理图像。
使用 S3 Object Lambda 接入点作为 CloudFront 分布的源
为简单起见,我在发布帖子中使用了相同的应用程序,将原始文件中的所有文本更改为大写。这次,我使用 S3 Object Lambda 接入点别名通过 CloudFront 设置公共分布。
我按照与发布帖子中相同的步骤创建 S3 Object Lambda 接入点和 Lambda 函数。由于 Python 3.8 及更高版本的 Lambda 运行时不包含请求模块,因此我更新了函数代码以使用 Python 标准库中的 urlopen:
import boto3
from urllib.request import urlopen
s3 = boto3.client('s3')
def lambda_handler(event, context):
print(event)
object_get_context = event['getObjectContext']
request_route = object_get_context['outputRoute']
request_token = object_get_context['outputToken']
s3_url = object_get_context['inputS3Url']
# Get object from S3
response = urlopen(s3_url)
original_object = response.read().decode('utf-8')
# Transform object
transformed_object = original_object.upper()
# Write object back to S3 Object Lambda
s3.write_get_object_response(
Body=transformed_object,
RequestRoute=request_route,
RequestToken=request_token)
return为了测试这是否有效,我从存储桶和 S3 Object Lambda 接入点打开了相同的文件。在 S3 控制台中,我选择了我之前上传的存储桶和示例文件(名为 s3.txt),然后选择打开。

将打开一个新的浏览器选项卡(您可能需要在浏览器中禁用弹出窗口拦截器),其内容是包含混合大小写文本的原始文件:
Amazon Simple Storage Service (Amazon S3) is an object storage service that offers...
我从导航窗格中选择 Object Lambda 接入点,然后从下拉列表中选择我之前使用的 AWS 区域。然后,我搜索我刚刚创建的 S3 Object Lambda 接入点。我选择与以前相同的文件,然后选择打开。

在新选项卡中,文本已由 Lambda 函数处理,现在全部为大写:
AMAZON SIMPLE STORAGE SERVICE (AMAZON S3) IS AN OBJECT STORAGE SERVICE THAT OFFERS...
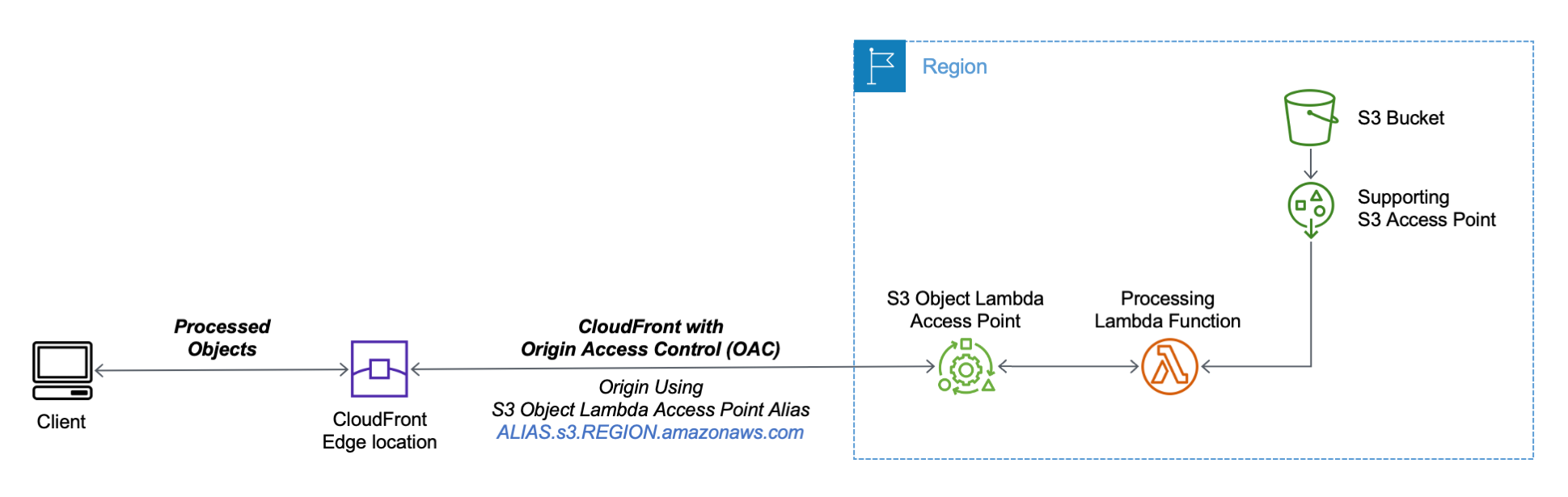
现在 S3 Object Lambda 接入点已正确配置,我可以创建 CloudFront 分布了。这样做之前,在 S3 控制台的 S3 Object Lambda 接入点列表中,我复制了自动创建的 Object Lambda 接入点别名:

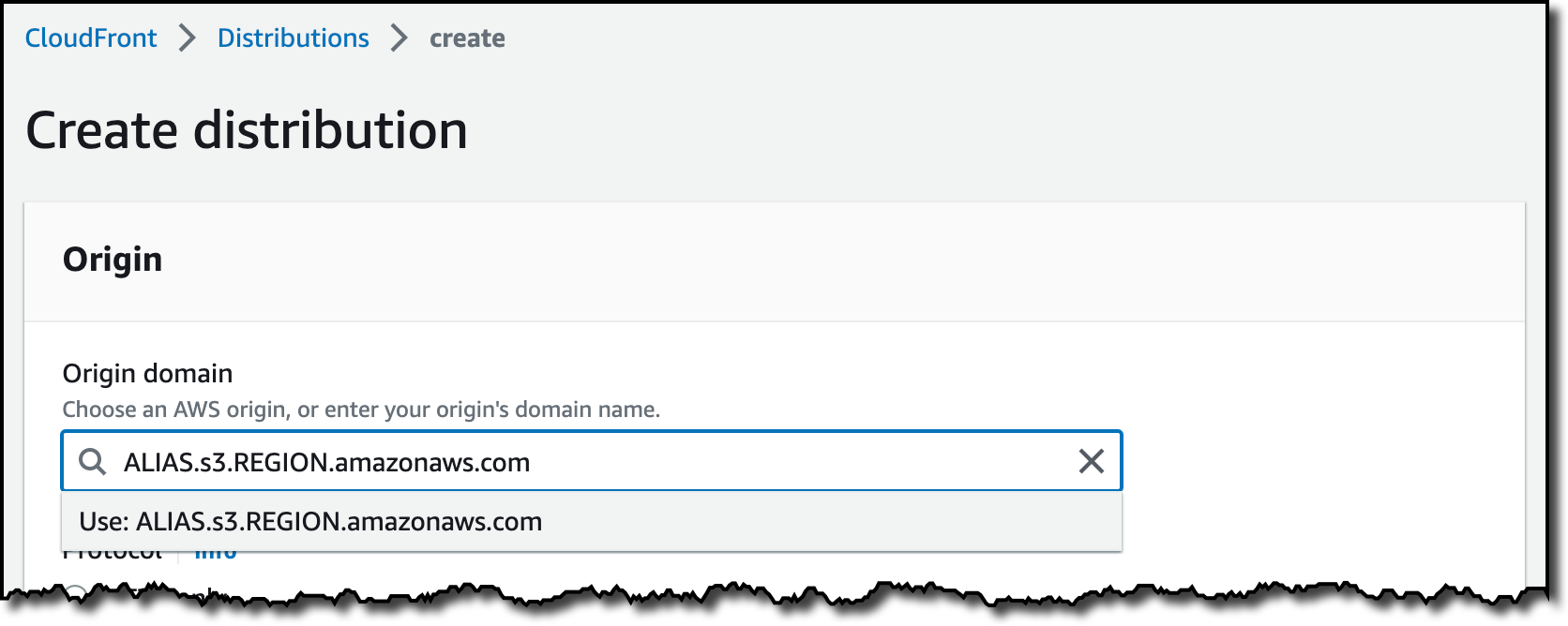
在 CloudFront 控制台中,我在导航窗格中选择分布,然后选择创建分布。在源域中,我使用 S3 Object Lambda 接入点别名和区域。该域的完整语法是:
ALIAS.s3.REGION.amazonaws.com
S3 Object Lambda 接入点不能公开,我使用 CloudFront 原始访问控制(OAC)对源请求进行身份验证。对于源访问权限,我选择源访问控制设置,然后选择创建控制设置。我为控制设置编写一个名称,然后在源类型下拉列表中选择为请求签名和 S3。

现在,我的源访问控制设置使用我刚刚创建的配置。

为了减少通过 S3 Object Lambda 的请求数量,我启用了源护盾并选择离我正在使用的区域最近的源护盾区域。然后,我选择 CachingOptimized 缓存策略并创建分布。在部署分布时,我更新了分布所用资源的权限。
设置使用 S3 Object Lambda 接入点作为 CloudFront 分布源的权限
首先,S3 Object Lambda 接入点需要授予对 CloudFront 分布的访问权限。在 S3 控制台中,我选择 S3 Object Lambda 接入点,然后在权限选项卡中使用以下内容更新策略:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "cloudfront.amazonaws.com"
},
"Action": "s3-object-lambda:Get*",
"Resource": "arn:aws:s3-object-lambda:REGION:ACCOUNT:accesspoint/NAME",
"Condition": {
"StringEquals": {
"aws:SourceArn": "arn:aws:cloudfront::ACCOUNT:distribution/DISTRIBUTION-ID"
}
}
}
]
}通过 S3 Object Lambda 调用时,支持接入点还需要允许访问 CloudFront。我选择该接入点并在权限选项卡中更新策略:
{
"Version": "2012-10-17",
"Id": "default",
"Statement": [
{
"Sid": "s3objlambda",
"Effect": "Allow",
"Principal": {
"Service": "cloudfront.amazonaws.com"
},
"Action": "s3:*",
"Resource": [
"arn:aws:s3:REGION:ACCOUNT:accesspoint/NAME",
"arn:aws:s3:REGION:ACCOUNT:accesspoint/NAME/object/*"
],
"Condition": {
"ForAnyValue:StringEquals": {
"aws:CalledVia": "s3-object-lambda.amazonaws.com"
}
}
}
]
}S3 存储桶需要允许访问支持接入点。我选择该存储桶并在权限选项卡中更新策略:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "*"
},
"Action": "*",
"Resource": [
"arn:aws:s3:::BUCKET",
"arn:aws:s3:::BUCKET/*"
],
"Condition": {
"StringEquals": {
"s3:DataAccessPointAccount": "ACCOUNT"
}
}
}
]
}最后,CloudFront 需要能够调用 Lambda 函数。在 Lambda 控制台中,我选择 S3 Object Lambda 使用的 Lambda 函数,然后在配置选项卡中选择权限。在基于资源的策略声明部分中,我选择添加权限并选择 AWS 账户。我输入一个唯一的声名 ID。然后,我输入 cloudfront.amazonaws.com 作为主体,然后从操作下拉列表中选择 Lambda:InvokeFunction 并选择保存。我们正在努力未来简化这一步骤。当这篇文章可用时,我会将其更新。
测试 CloudFront 分布
部署分布后,我测试安装程序是否与我之前使用的示例文件相同。在 CloudFront 控制台中,我选择该分布点并复制分布域名。我可以使用浏览器并在导航栏中输入 https://DISTRIBUTION_DOMAIN_NAME/s3.txt 向 CloudFront 发送请求,然后让 S3 Object Lambda 处理文件。为了快速获取所有信息,我使用带有 -i 选项的 curl 来查看 HTTP 状态和响应中的标头:
成功了! 正如预期的那样,Lambda 函数处理的内容都是大写的。由于这是首次调用此分布,因此尚未从缓存中返回它(x-cache: Miss from cloudfront)。该请求通过 S3 Object Lambda 发出,要求使用我提供的 Lambda 函数处理文件。
让我们再试一次同样的请求:
这次内容是从 CloudFront 缓存返回的(x-cache: Hit from cloudfront),S3 Object Lambda 没有进一步处理。通过使用 S3 Object Lambda 作为源,CloudFront 分布提供已由 Lambda 函数处理的内容,可以缓存以减少延迟和优化成本。
使用 S3 Object Lambda 和 CloudFront 调整图像大小
正如我在本文开头提到的那样,可以使用 S3 Object Lambda 和 CloudFront 实现的使用案例之一是图像转换。让我们创建一个 CloudFront 分布,它可以通过传递所需的宽度和高度作为查询参数(分别为 w 和 h)来动态调整图像大小。例如:
为了使此设置生效,我需要对 CloudFront 分布进行两项更改。首先,我创建一个新的缓存策略,在缓存密钥中包含查询参数。在 CloudFront 控制台中,我在导航窗格中选择策略。在缓存选项卡中,我选择创建缓存策略。然后,我输入缓存策略的名称。

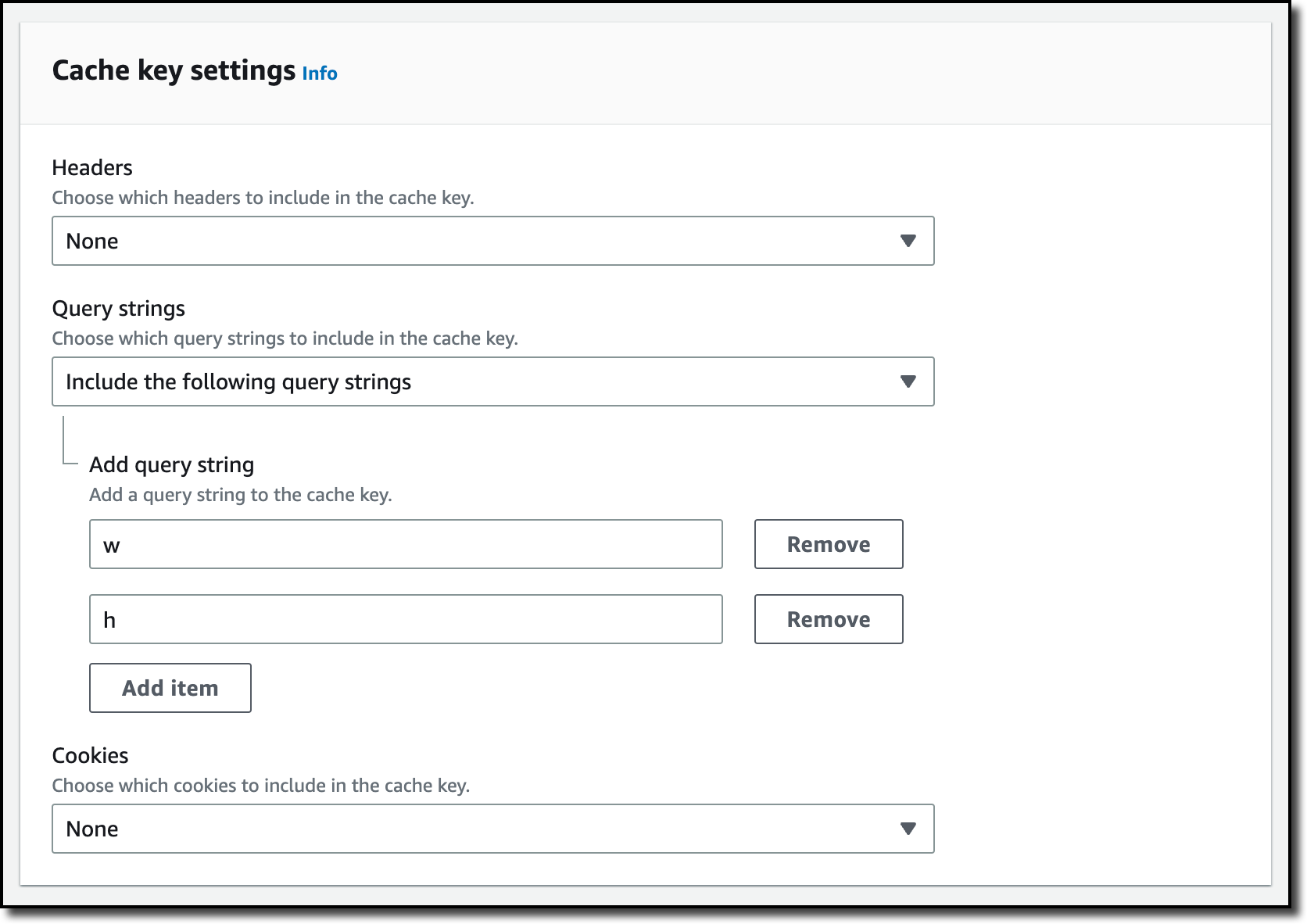
在缓存密钥设置的查询设置中,我选择相应选项以包含以下查询参数并添加 w(宽度)和 h(高度)。
然后,在分布的行为选项卡中,我选择默认行为并选择编辑。
在那里,我更新缓存密钥和原始请求部分:
- 在缓存策略中,我使用新的缓存策略在缓存密钥中包含
w和h查询参数。 - 在源请求策略中,使用
AllViewerExceptHostHeader托管策略将查询参数转发到源。

现在我可以更新 Lambda 函数代码了。要调整图像大小,此函数使用 Pillow 模块,该模块在上传到 Lambda 时需要与该函数一起打包。您可以使用 AWS SAM CLI 或 AWS CDK 等工具部署该函数。与前面的示例相比,此函数还处理并返回 HTTP 错误,例如在存储桶中找不到内容时。
import io
import boto3
from urllib.request import urlopen, HTTPError
from PIL import Image
from urllib.parse import urlparse, parse_qs
s3 = boto3.client('s3')
def lambda_handler(event, context):
print(event)
object_get_context = event['getObjectContext']
request_route = object_get_context['outputRoute']
request_token = object_get_context['outputToken']
s3_url = object_get_context['inputS3Url']
# Get object from S3
try:
original_image = Image.open(urlopen(s3_url))
except HTTPError as err:
s3.write_get_object_response(
StatusCode=err.code,
ErrorCode='HTTPError',
ErrorMessage=err.reason,
RequestRoute=request_route,
RequestToken=request_token)
return
# Get width and height from query parameters
user_request = event['userRequest']
url = user_request['url']
parsed_url = urlparse(url)
query_parameters = parse_qs(parsed_url.query)
try:
width, height = int(query_parameters['w'][0]), int(query_parameters['h'][0])
except (KeyError, ValueError):
width, height = 0, 0
# Transform object
if width > 0 and height > 0:
transformed_image = original_image.resize((width, height), Image.ANTIALIAS)
else:
transformed_image = original_image
transformed_bytes = io.BytesIO()
transformed_image.save(transformed_bytes, format='JPEG')
# Write object back to S3 Object Lambda
s3.write_get_object_response(
Body=transformed_bytes.getvalue(),
RequestRoute=request_route,
RequestToken=request_token)
return我在原始存储桶中上传一张我拍的特莱维喷泉的照片。首先,我生成一个小缩略图(200 x 150 像素)。
https://DISTRIBUTION_DOMAIN_NAME/trevi-fountain.jpeg?w=200&h=150

现在,我要求一个稍大一点的版本(400 x 300 像素):

它能够按预期工作。第一个具有特定大小的调用由 Lambda 函数处理。具有相同宽度和高度的其他请求由 CloudFront 缓存提供。
可用性和定价
S3 Object Lambda 接入点的别名现已在所有商业 AWS 区域推出。别名不会产生额外费用。使用 S3 Object Lambda,您可以为处理数据所需的 Lambda 计算和请求费用以及 S3 Object Lambda 返回到您的应用程序的数据付费。您还需要为 Lambda 函数调用的 S3 请求付费。有关更多信息,请参阅 Amazon S3 定价。
现在,在创建 S3 Object Lambda 接入点后会自动生成别名。对于现有 S3 Object Lambda 接入点,别名会自动分配且可供使用。
现在可以更容易地在现有应用程序中使用 S3 Object Lambda,别名释放了许多新的可能性。例如,您可以在 CloudFront 中使用别名来创建一个网站,使其将 Markdown 中的内容转换为 HTML,调整图像大小和加水印,或者屏蔽文本、图像和文档中的个人身份信息(PII)。
为使用 S3 Object Lambda 及 CloudFront 的最终用户自定义内容。
— Danilo