Blog AWS Indonesia
Menjelajahi Gambar di Media Sosial Menggunakan Amazon Rekognition dan Amazon Athena
Jika Anda seperti kebanyakan perusahaan, Anda ingin lebih memahami pelanggan dan citra merek Anda. Anda ingin melacak keberhasilan kampanye pemasaran Anda, dan topik yang menarik — atau frustrasi — bagi pelanggan Anda. Media sosial adalah hal yang sangat menjanjikan untuk menjadi sumber yang kaya dari jenis informasi ini, dan banyak perusahaan mulai mengumpulkan, mengumpulkan, dan menganalisis informasi dari platform seperti Twitter.
Namun, semakin banyak percakapan media sosial berpusat di sekitar gambar dan video; pada satu proyek terbaru, sekitar 30% dari semua tweet (kicauan) yang dikumpulkan termasuk satu atau lebih gambar. Gambar-gambar ini berisi informasi yang relevan yang tidak mudah diakses tanpa analisis.
| Tentang tulisan ini | |
| Waktu menyelesaikan | 1 jam
|
| Biaya yang dikeluarkan | ~ US$5 (di saat publikasi blog post ini, tergantung region dan kondisi) |
| Level pelajaran | Intermediate (200) |
| Layanan AWS | Amazon Rekognition
Amazon Athena Amazon Kinesis Data Firehose Amazon S3 AWS Lambda |
Gambaran Umum Solusi
Diagram berikut menunjukkan komponen solusi dan bagaimana gambar dan data yang diekstraksi secara mengalir di solusi ini:

Komponen ini tersedia melalui templat AWS CloudFormation.
- Twitter Search API mengumpulkan tweet.
- Amazon Kinesis Data Firehose mengirimkan tweet untuk disimpan di Amazon S3.
- Dengan adanya objek S3 dalam bucket atau direktori akan memicu fungsi Lambda.
- Lambda mengirimkan setiap teks tweet ke Amazon Comprehend untuk mendeteksi sentimen (positif atau negatif), entitas (objek dunia nyata seperti orang, tempat, dan barang komersial), dan referensi yang tepat untuk langkah-langkah seperti tanggal dan jumlah. Untuk informasi lebih lanjut, anda dapat melihat
DetectSentimentdanDetectEntitydi panduan pengembang untuk Amazon Comprehend. - Lambda memeriksa setiap tweet untuk media jenis ‘
photo’ di tweetextended_entities. Jika foto memiliki extention.JPGatau.PNG, Lambda akan memanggil Amazon Rekognition API berikut untuk setiap gambar:Detect_labels, untuk mendeteksi obyek sepertiPerson,Pedestrian,Vehicle, danCardari gambar.Detect_moderation_labels, untuk menentukan apakah gambar atau video yang disimpan berisi konten yang tidak aman, seperti konten dewasa yang eksplisit atau konten kekerasan.- Jika
detect_labelsAPI mengembalikan hasil labelText,detect_textakan mengekstraksi garis, kata, atau huruf yang ditemukan dalam gambar. - Jika
detect_labelsAPI mengembalikan hasil labelPerson, maka Lambda akan memanggil API berikut:detect_faces, untuk mendeteksi wajah dan menganalisisnya untuk fitur seperti kacamata hitam, jenggot, dan kumis.recognize_celebrities, untuk mendeteksi sebanyak mungkin selebriti dalam beberapa setting yang berbeda, makeup kosmetik, dan kondisi lainnya.
- Hasil dari semua panggilan untuk satu gambar digabungkan menjadi satu JSON record. Untuk informasi lebih lanjut tentang API ini, lihat Actions pada panduan pengembang untuk Amazon Rekognition.
- Hasil dari Lambda akan dikirim ke Kinesis Data Firehose. Kinesis Data Firehose mengumpulkan record-record tersebut dan menuliskannya ke dalam folder di S3 bucket tertentu.
- Anda dapat menggunakan Amazon Athena untuk membangun tabel dan view atas dataset S3, kemudian katalog definisi ini dalam data catalog di AWS Glue. Tabel dan definisi view menjadikan lebih mudah untuk query objek JSON yang kompleks di dalam dataset S3 ini.
- Setelah tweet diproses dan disimpan di S3, Anda dapat query data dengan Athena.
- Anda juga dapat menggunakan Amazon QuickSight untuk visualisasi data, atau Amazon SageMaker atau Amazon EMR untuk memproses data lebih lanjut. Untuk informasi lebih lanjut anda dapat membaca artikel Build a social media dashboard using machine learning and BI services. Sedangkan tulisan ini hanya akan menggunakan Athena.
Prasyarat
Prasyarat dalam ulasan ini adalah:
- Memiliki akun AWS.
- Memiliki app di Twitter. Untuk membuat app, maka anda dapat melihat Apps section di website Twitter untuk pengembang.
- Buat consumer key (API key), consumer secret key (API secret), access token, dan access token secret. Solusi ini menggunakan data-data tersebut sebagai parameter dalam AWS CloudFormation stack.
Ulasan
Tulisan ini akan menjelaskan kepada anda langkah-langkah sebagai berikut:
- Meluncurkan template AWS CloudFormation yang disediakan dan mengumpulkan tweet.
- Memeriksa bahwa stack membuat dataset pada S3
- Membuat view atas dataset menggunakan Athena.
- Eksplorasi data
S3 menyimpan data mentah tweet dan keluaran dari Amazon Comprehend dan Amazon Rekognition akan dalam format JSON. Anda dapat menggunakan tabel dan definisi view di Athena untuk meratakan hasil JSON yang kompleks dan mengekstraksi field yang Anda inginkan. Pendekatan ini membuat data lebih mudah untuk diakses dan dipahami.
Meluncurkan templat AWS CloudFormation
Tulisan ini menyediakan template AWS CloudFormation yang membuat komponen ingestion seperti yang ada dalam diagram sebelumnya, kecuali untuk notifikasi S3 untuk Lambda (garis biru putus-putus dalam diagram).
- Di AWS Management Console, luncurkan AWS CloudFormation Template berikut.

Ini akan meluncurkan stack AWS CloudFormation secara otomatis ke dalam regionus-east-1. - Di tulisan blog Build a social media dashboard using machine learning and BI services, di bagian “Build this architecture yourself”, ikuti langkah-langkahnya dengan perubahan sebagai berikut:
- Gunakan pranala Launch Stack dari tulisan ini.
- Jika basisdata AWS Glue
socialanalyticsblogsudah ada (misalnya, jika Anda menyelesaikan ulasan dari posting sebelumnya), ubahlah nama basisdata saat meluncurkan stack AWS CloudFormation, dan menggunakan nama basisdata baru untuk solusi ini selanjutnya. - Untuk bahasa Twitter, gunakan ‘
en‘ (Bahasa Inggris) saja. Tulisan ini tidak menggunakan kemampuan Amazon Comprehend Translate untuk kesederhanaan dan untuk mengurangi biaya. - Lewati bagian “Setting up S3 Notification – Call Amazon Translate/Comprehend from new Tweets.” Hal ini terjadi secara otomatis ketika meluncurkan stack AWS CloudFormation oleh fungsi lambda “Add Trigger”. Berhenti di bagian “Create the Athena Tables” dan selesaikan petunjuk berikut di tulisan ini sebagai gantinya.
Anda dapat memodifikasi istilah mana yang akan diambil dari Twitter streaming API untuk menjadi yang relevan bagi perusahaan Anda dan pelanggan Anda. Tulisan ini menggunakan beberapa istilah terkait Amazon.
Implementasi ini membuat dua panggilan Amazon Comprehend dan hingga lima panggilan Amazon Rekognition untuk setiap tweet. Biaya menjalankan implementasi ini berbanding lurus dengan jumlah tweet yang Anda kumpulkan. Jika Anda ingin mengubah persyaratan menjadi sesuatu yang dapat mengambil puluhan atau ratusan tweet per detik, untuk efisiensi dan manajemen biaya, pertimbangkan untuk melakukan panggilan batch atau menggunakan AWS Glue dengan pemicu untuk melakukan pemrosesan batch dibandingkan dengan pemrosesan stream.
Memeriksa Berkas S3
Setelah stack berjalan selama sekitar lima menit, dataset mulai muncul di S3 bucket (rTweetsBucket) yang dibuat oleh AWS Cloudformation. Setiap dataset direpresentasikan sebagai file-file berikut pada direktori terpisah di S3:
- Raw – Data mentah tweets yang diterima dari Twitter.
- Media – Keluaran dari hasil pemanggilan Amazon Rekognition API.
- Entities – Hasil dari analisa entitas oleh Amazon Comprehend.
- Sentiment – Hasil dari analisa sentimen oleh Amazon Comprehend.
Lihat tangkapan dari direktori berikut:
Untuk entity dan analisa sentimen, anda dapat melihat Build a social media dashboard using machine learning and BI services.
Bila Anda memiliki cukup data untuk dijelajahi (tergantung pada seberapa populer istilah yang dipilih dan seberapa sering mereka memiliki gambar), Anda dapat menghentikan produser aliran Twitter, dan menghentikan atau mematikan instans Amazon EC2, Ini menghentikan biaya Anda dari Amazon Comprehend, Amazon Rekognition, dan EC2.
Membuat View di Athena
Langkah selanjutnya adalah membuat basisdata Athena secara manual. Untuk informasi lebih lanjut di Getting Started pada panduan pengguna Athena.
Ini adalah waktu yang cocok untuk menggunakan fitur crawling dari AWS Glue pada arsitektur data lake anda. Crawler secara otomatis menemukan format data dan jenis data dari dataset Anda yang berbeda yang ada di S3 (serta database relasional dan data warehouse). Untuk informasi selengkapnya, lihat Defining Crawlers.
- Di console Athena, di bagian Query Editor, akses file sql ini. Stack AWS CloudFormation tersebut akan membuat basisdata dan tabel untuk Anda secara otomatis.
- Jalankan perintah
view createke dalam Athena Query Editor satu-persatu, kemudian eksekusi. Langkah ini membuat view dari tabel.
Dibandingkan dengan posting sebelumnya, tabel dan view media_rekognition disini adalah baru. Tabel tweet memiliki kolom baru extended_entities untuk metadata gambar dan video. Definisi dari tabel lainnya sama dengan tulisan sebelumnya.
Database Athena Anda akan terlihat mirip dengan screenshot berikut. Ada empat tabel, satu untuk masing-masing dataset pada S3. Ada juga tiga view, menggabungkan dan memperlihatkan rincian dari tabel media_rekognition:
Celeb_viewyang fokus pada hasil dari APIrecognize_celebritiesMedia_image_labels_queryyang fokus pada hasil dari APIdetect_labelsMedia_image_labels_face_queryyang fokus pada hasil APIdetect_faces

Anda dapat mengeksplorasi tabel dan definisi view. Objek JSON itu kompleks, dan definisi ini menunjukkan berbagai kegunaan untuk query objek bersarang (nested object) dan larik (array) dengan jenis kompleks. Sekarang banyak dari query dapat relatif sederhana, hal ini karena berkat tabel dan definisi view yang mendasari merangkum kompleksitas JSON. Untuk informasi selengkapnya, lihat Querying Arrays with Complex Types and Nested Structures.
Eksplorasi hasil
Bagian ini menjelaskan tiga kasus penggunaan untuk data ini dan menyediakan SQL untuk mengekstrak data yang serupa. Karena istilah pencarian dan jangka waktu Anda berbeda dari yang ada di tulisan ini, hasil Anda akan berbeda. Tulisan ini menggunakan seperangkat istilah terkait Amazon. Kolektor tweet berjalan selama sekitar enam minggu dan mengumpulkan sekitar 9,5 juta tweet. Dari tweet, ada sekitar 0,5 juta foto, yaitu sekitar 5% dari tweet. Jumlah ini rendah dibandingkan dengan beberapa set lain dari istilah pencarian terkait bisnis, di mana sekitar 30% tweet berisi foto.
Tulisan ini mengulas untuk empat kasus penggunaan gambar:
- Buzz
- Label dan wajah
- Isi yang mencurigakan
- Menemukan selebriti
Buzz
Bidang topik utama yang diwakili oleh pranala (link) yang terkait dengan tweet sering memberikan pelengkap yang baik untuk topik konten bahasa tweet muncul melalui pemrosesan bahasa alami (natural language processing). Untuk informasi lebih lanjut Anda dapat membaca Build a social media dashboard using machine learning and BI services.
Kueri pertama adalah situs mana yang ditautkan dengan tweet. Kode berikut menunjukkan nama domain teratas yang ditautkan dari tweet:
SELECT lower(url_extract_host(url.expanded_url)) AS domain,count(*) AS countFROM(SELECT *FROM "tweets"CROSS JOIN UNNEST (entities.urls) t (url))GROUP BY 1ORDER BY 2 DESCLIMIT 10;Tangkapan layar berikut menunjukkan 10 domain teratas:

Tautan ke situs web Amazon sering terjadi, dan beberapa properti berbeda diberi nama, seperti amazon.com, amazon.co.uk, dan goodreads.com.
Eksplorasi lebih lanjut menunjukkan bahwa banyak dari link ini ke halaman produk di situs Amazon. Sangat mudah untuk mengenali link ini karena mereka memiliki /dp/ (untuk halaman detail) di link. Anda bisa mendapatkan daftar link tersebut, gambar yang ada di dalamnya, dan baris pertama teks dalam gambar (jika ada), dengan kueri berikut:
SELECT tweetid,
user_name,
media_url,
element_at(textdetections,1).detectedtext AS first_line,
expanded_url,
tweet_urls."text"
FROM
(SELECT id,
user.name AS user_name,
text,
entities,
url.expanded_url as expanded_url
FROM tweets
CROSS JOIN UNNEST (entities.urls) t (url)) tweet_urls
JOIN
(SELECT media_url,
tweetid,
image_labels.textdetections AS textdetections
FROM media_rekognition) rk
ON rk.tweetid = tweet_urls.id
WHERE lower(url_extract_host(expanded_url)) IN ('www.amazon.com', 'amazon.com', 'www.amazon.com.uk', 'amzn.to')
AND NOT position('/dp/' IN url_extract_path(expanded_url)) = 0 -- url links to a product
LIMIT 50;Tangkapan layar berikut menunjukkan beberapa baris dikembalikan oleh kueri ini. Kolom first_line menunjukan hasil dari API detect_text dari gambar yg URLnya ada di kolom media_url.
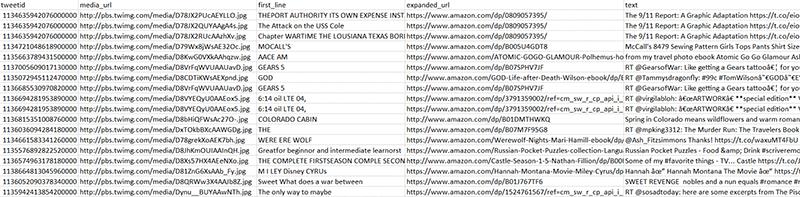
Banyak gambar yang berisi teks. Anda juga dapat mengidentifikasi produk yang ditautkan dengan tweet; banyak tweet adalah iklan produk oleh penjual, menggunakan gambar yang berhubungan langsung dengan produk mereka.
Label and wajah
Anda juga bisa mendapatkan konten visual dari gambar dengan melihat hasil dari panggilan API detect_labels pada Amazon Rekognition. Kueri berikut ini akan mendapatkan objek yang paling umum dari foto:
SELECT label_name,COUNT(*) AS countFROM media_image_labels_queryGROUP BY label_nameORDER BY COUNT(*) descLIMIT 50;Tangkapan layar berikut menunjukkan hasil dari permintaan tersebut. Label yang paling populer sejauh ini adalah Human atau Person, dengan Text, Advertisement, dan Poster. Novel ada juga di bagian bawah daftar. Hasil ini mencerminkan produk yang paling populer yang di-tweet tentang di situs buku web Amazon.

Anda dapat mengeksplorasi wajah lebih jauh dengan melihat hasil dari API detect_faces. API tersebut mengembalikan detail untuk setiap wajah dalam gambar, termasuk jenis kelamin, rentang usia, posisi wajah, apakah orang tersebut mengenakan kacamata hitam atau memiliki kumis, dan ekspresi di wajah mereka. Masing-masing fitur ini juga memiliki tingkat kepercayaan yang terkait dengannya. Untuk informasi selengkapnya, lihat DetectFaces di panduan pengembang Amazon Rekognition.
View media_image_labels_face_query membuka banyak fitur dari objek JSON yang kompleks yang dihasilkan dari panggilan API, membuat pemrosesan jadi lebih mudah.
Anda dapat mengeklorasi definisi View untuk media_image_labels_face_query , termasuk penggunaan reduce operator dari array (emotion,confidence) yang dikembalikan oleh Amazon Rekognition untuk mengidentifikasi dan mengembalikan kategori ekspresi dengan skor kepercayaan tertinggi yang terkait dengannya, dan mengaitkan nama top_emotion.
Lihatlah kode berikut ini:
reduce(facedetails.emotions, element_at(facedetails.emotions, 1), (s_emotion, emotion) -> IF((emotion.confidence > s_emotion.confidence), emotion, s_emotion), (s) -> s) top_emotionAnda dapat menggunakan field top_emotion. Lihat kode berikut ini:
SELECT top_emotion.type AS emotion ,
top_emotion.confidence AS emotion_confidence ,
milfq.* ,"user".id AS user_id ,"user".screen_name ,"user".name AS user_name ,
url.expanded_url AS urlFROM media_image_labels_face_query milfqINNER JOIN tweets
ON tweets.id = tweetid, UNNEST(entities.urls) t (url)WHERE position('.amazon.' IN url.expanded_url) > 0;Tangkapan layar berikut menunjukkan kolom dari tengah kueri yang luas ini, termasuk kacamata, rentang usia, dan di mana tepi wajah ini diposisikan. Detail terakhir ini berguna ketika beberapa wajah hadir dalam satu gambar, untuk membedakan antara wajah.

Anda dapat melihat ekspresi tertinggi yang ditemukan dari wajah-wajah ini dengan menggunakan code berikut:
SELECT top_emotion.type AS emotion,COUNT(*) AS "count"FROM media_image_labels_face_query milfqWHERE top_emotion.confidence > 50GROUP BY top_emotion.typeORDER BY 2 desc; Tangkapan dari hasil kueri berikut ini menunjukan bahwa CALM adalah ekspresi yang tertinggi, kemudian diikuti oleh HAPPY. Anehnya, ada yang jauh lebih sedikit ekspreksi bingung daripada ekspresi jijik.
Konten yang Mencurigakan
Topik yang sering menjadi perhatian adalah apakah ada konten dalam tweet, atau gambar terkait, yang harus dimoderasi. Salah satu API Amazon Rekognition dipanggil oleh Lambda untuk setiap gambar adalah moderation_labels, yang mengembalikan label yang menunjukkan kategori konten yang ditemukan, jika ada. Untuk informasi selengkapnya, lihat Detecting Unsafe Content.
Kode berikut akan menemukan tweet dengan gambar yang mencurigakan. Twitter juga menyediakan flag possibly_sensitive berdasarkan teks pada tweet.
SELECT tweetid,
possibly_sensitive,
transform(image_labels.moderationlabels, ml -> ml.name) AS moderationlabels,"mediaid", "media_url" ,
tweets.text,"url"."expanded_url" AS url ,(CASE WHEN ("substr"("tweets"."text", 1, 2) = 'RT') THENtrueELSE false END) "isretweet"FROM media_rekognitionINNER JOIN tweets
ON ("tweets"."id" = "tweetid"), UNNEST("entities"."urls") t (url)WHERE cardinality(image_labels.moderationlabels) > 0OR possibly_sensitive = True;Tangkapan layar berikut menunjukkan beberapa hasil pertama. Untuk sebagian besar entri ini, teks tweet atau gambar mungkin berisi konten sensitif, tetapi belum tentu keduanya. Memasukan kedua kriteria tersebut memberikan keamanan tambahan.

Perlu dicatat bahwa penggunaan konstruksi transform dalam kueri sebelumnya untuk memetakan atas array JSON label moderasi yang dikembalikan oleh Amazon Rekognition. Konstruksi ini memungkinkan Anda mengubah konten asli dari object moderationlabels (di array berikut ini) ke dalam daftar yang hanya berisi field nama:
[{confidence=52.257442474365234, name=Revealing Clothes, parentname=Suggestive}, {confidence=52.257442474365234, name=Suggestive, parentname=}] Anda dapat memfilter kueri ini untuk fokus pada jenis konten yang tidak aman tertentu dengan memfilter label moderasi tertentu. Untuk informasi selengkapnya, lihat Detecting Unsafe Content.
Banyak tweet ini memiliki pranala produk yang ditanamkan dalam URL. URL untuk situs Amazon.com memiliki pola: setiap URL dengan /dp/ di dalamnya adalah link ke halaman produk. Anda dapat menggunakannya untuk mengidentifikasi produk yang mungkin memiliki konten eksplisit yang terkait dengannya.
Eksplorasi selebriti
Salah satu API Amazon Rekognition yang Lambda panggil pada setiap gambar adalah recognize_celebrity. Untuk informasi lebih lanjut anda dapat melihat Recognizing Celebrities in an Image.
Kode berikut akan membantu untuk menentukan selebriti mana yang sering muncul dari dataset:
SELECT name as celebrity,COUNT (*) as countFROM celeb_viewGROUP BY nameORDER BY COUNT (*) desc;Hasilnya menghitung contoh identifikasi selebriti, dan menghitung gambar dengan beberapa selebriti beberapa kali.
Sebagai contoh, misalnya ada selebriti dengan name JohnDoe. Untuk mengeksplorasi gambar lebih jauh maka kita dapat menggunakan kueri berikut ini. Kueri ini akan menemukan gambar yang terkait dengan tweet dimana ada JohnDoe yang muncul di teks atau di gambar.
SELECT cv.media_url,
COUNT () AS count ,
detectedtext
FROM celeb_view cv
LEFT JOIN -- left join to catch cases with no text
(SELECT tweetid,
mediaid,
textdetection.detectedtext AS detectedtext
FROM media_rekognition , UNNEST(image_labels.textdetections) t (textdetection)
WHERE (textdetection.type = 'LINE'
AND textdetection.id = 0) -- get the first line of text
) mr
ON ( cv.mediaid = mr.mediaid
AND cv.tweetid = mr.tweetid )
WHERE ( ( NOT position('johndoe' IN lower(tweettext)) = 0 ) -- JohnDoe IN text
OR ( (NOT position('johndoe' IN lower(name)) = 0) -- JohnDoe IN image
AND matchconfidence > 75) ) -- with pretty good confidence
GROUP BY cv.media_url, detectedtext
ORDER BY COUNT() DESC;
API recognize_celebrity mencocokkan setiap gambar dengan selebriti yang muncul paling dekat. Ia mengembalikan nama selebriti dan informasi terkait, bersamaan dengan skor kepercayaan. Terkadang, hasilnya bisa kurang memuaskan; misalnya, jika wajah dipalingkan, atau saat orang tersebut mengenakan kacamata hitam, mereka bisa sulit dikenali dengan benar. Dalam kasus lain, API dapat memilih model gambar karena kesamaan mereka dengan selebriti. Ini mungkin bermanfaat untuk menggabungkan kueri ini dengan logika menggunakan respon dari face_details, untuk memeriksa kacamata ataupun posisi wajah.
Pembersihan
Untuk menghindari menimbulkan biaya di masa mendatang, hapuslah stack AWS CloudFormation, dan isi S3 bucket yang dibuat. Anda cukup masuk ke dalam konsol AWS CloudFormation, pilih stack yang dibuat, dan hapus.
Kesimpulan
Tulisan ini menunjukkan bagaimana untuk mulai mengeksplorasi apa yang pelanggan Anda katakan tentang Anda di media sosial menggunakan gambar. Kueri dalam posting ini hanyalah awal dari apa yang mungkin dilakukan. Untuk lebih memahami totalitas percakapan pelanggan Anda, Anda dapat menggabungkan kemampuan dari posting ini dengan hasil menjalankan pemrosesan bahasa alami (natural language processing) terhadap tweet.
Seluruh proses, analitik, dan pipeline pembelajaran mesin (machine learning) ini—dimulai dengan Kinesis Data Firehose, menggunakan Amazon Comprehend untuk melakukan analisis sentimen, Amazon Rekognition untuk menganalisis foto, dan Athena untuk kueri data, dan dimungkinkan tanpa menggunakan server apa pun.
Tulisan ini menambahkan layanan pembelajaran mesin lanjutan (advanced machine learning) (ML) ke pipeline pengumpulan Twitter, melalui beberapa panggilan sederhana dalam Lambda. Solusinya juga menyimpan semua data ke S3 dan menunjukkan bagaimana untuk query objek JSON yang kompleks menggunakan beberapa pernyataan SQL. Anda dapat melakukan analisis lebih lanjut pada data menggunakan Amazon EMR, Amazon SageMaker, Amazon Elasticsearch Service, atau layanan AWS lainnya. Batasannya hanyalah imajinasi anda.
Tulisan ini berasal dari artikel Exploring images on social media using Amazon Rekognition and Amazon Athena yang ditulis oleh Veronika Megler dan Chris Ghyzel dan diterjemahkan oleh Rudi Suryadi.