Amazon Web Services ブログ
Amazon SageMaker でより速いパイプモードを使用してモデルのトレーニングを高速化する
Amazon SageMaker には現在、より高速のパイプモードが実装されているため、機械学習モデルをトレーニングしながら、Amazon Simple Storage Service (S3) から Amazon SageMaker へのデータのストリーミング速度を大幅に高速化することができます。
パイプモードは、モデルトのレーニングを開始する前に、ローカルの Amazon Elastic Block Store (EBS) ボリュームにデータをダウンロードするファイルモードよりも大幅に優れた読み取りスループットを提供します。つまり、トレーニングジョブがより早く始まり、迅速に完了し、必要なディスク容量が少なくて済み、Amazon SageMaker で機械学習モデルをトレーニングするための全体的なコストが削減されることを意味します。たとえば、Amazon SageMaker の組み込みアルゴリズム用パイプ入力モードを開始した今年の早い時期に、内部ベンチマークを実施しました。その結果、78 GB のトレーニングデータセットで開始時間が最大 87% 短縮されたことが分かりました。さらに、一部のベンチマークではスループットが 2 倍に向上し、合計トレーニング時間が最大 35% 短縮されることが分かりました。
概要
Amazon SageMaker は、トレーニングデータを転送するために、ファイルモードとパイプモードの 2 つのメカニズムをサポートしています。ファイルモードでは、トレーニングデータは、トレーニングを開始する前に、まずトレーニングインスタンスに添付された暗号化された EBS ボリュームにダウンロードされます。しかし、パイプモードでは、入力データは実行中にトレーニングアルゴリズムに直接ストリームされます。この連続的なデータのストリーミングによって、いくつかの大きな利点がもたらされます。まず、トレーニングジョブの起動時間が入力データのサイズとは無関係になり、特にギガバイトおよびペタバイトの規模のデータセットでのトレーニングでは、起動がはるかに迅速になります。さらに、大きなデータセットをダウンロードするために大容量のディスクボリュームの使用料を支払う必要がありません。最後に、トレーニングのアルゴリズムで I/O の負荷が大きい場合、パイプモードで採用されている並行性の高い高スループットの読み取りメカニズムにより、モデルのトレーニングが大幅にスピードアップされます。
より速いパイプモードでより高い I/O スループット
パイプモードの最新の実装は、以前よりも高いデータストリーミングのスループットを実現しています。次の図は、今年初めにパイプモードのサポートを開始したときと比較した、パイプモードでのスループットの向上を示しています。同一条件での比較では、ストリーミングスループットの数値は、Amazon SageMaker のトレーニングでサポートされているインスタンスタイプで測定したファイルモードのスループットの数値に対するベースラインに基づいています。
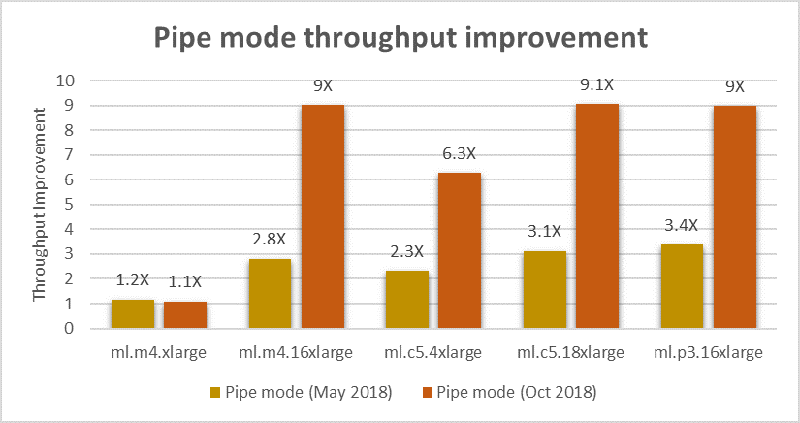
ご覧のように、パイプモードを使用してトレーニングデータをストリーミングすると、以前の場合よりも最大で 3 倍高速になることがあります。パイプモードのサポートは、Amazon SageMaker の組み込みアルゴリズムですぐに使用できるように用意されています。ここでは、独自のカスタムトレーニングアルゴリズムを Amazon SageMaker に導入する場合に、パイプモードを活用する方法の例を紹介します。
パイプモードのトレーニングコードを書く
パイプモードでは、データは高い並行性とスループットで Amazon S3 からプリフェッチされ、Unix の名前付きパイプ (別名 FIFO) にストリームされます。1 エポックあたり 1 チャネルの FIFO が 1 つあります。アルゴリズムは FIFO を読み取り用にオープンし、<EOF> (または、必要に応じて中間ストリーム) まで読み込む必要があります。完了したら、ファイルの終端記述子を閉じる必要があります。その後、オプションで、次のエポックの FIFO が作成されるのを待ってから、読み込みを開始することができます。アルゴリズムは、完了条件を達成するまでエポックを繰り返します。
このノートブックの例では、Python での非常にシンプルなパイプモードの 「トレーニング」のアルゴリズムが実装されています。Amazon SageMaker のトレーニングで必要な仕様に準拠しています。パイプモードでデータを読み込みますが、そのデータでは何もしません。単にデータを読み込んで、投げ捨てるだけです。この例は、実際のトレーニングアルゴリズムでコードを複雑にすることなく、パイプモードをサポートするために必要なことを正確に示すためにこのように書かれています。
train.py Python プログラムにコードが含まれています。次のコードスニペットは、対応する FIFO を通じて各エポックのデータを読み取ることを繰り返します。
パイプモードとファイルモードの使用
パイプモードがトレーニングに最適な選択肢ではない場合がいくつかあります。その場合は、ファイルモードを使用してください。
- アルゴリズムが、あるエポック内でバックトラックまたはスキップする必要がある場合。基礎となる FIFO が lseek() 操作をサポートできないため、パイプモードではこれが不可能であるためです。
- トレーニングデータセットがメモリに収まるほど小さく、複数のエポックを実行する必要がある場合。この場合、すべてをメモリに読み込んで、繰り返し実行するほうが迅速かつ簡単になる可能性があるためです。
- ストリーミングのソースからトレーニングのデータセットを解析することが容易でない場合。
他のすべてのシナリオでは、I/O の負荷が大きいトレーニングアルゴリズムを使用している場合、パイプモードに切り替えると、必要なディスクボリュームのサイズを縮小するだけでなく、大幅なスループット向上が実現します。これにより、時間が節約され、トレーニングコストも削減されます。
著者について
 Ishaaq Chandy は、Amazon AI のシニアエンジニアであり、Amazon Sagemaker のための革新的で大規模に拡張可能なトレーニングプラットフォームの構築に関心を寄せています。以前は、AWS ELB に携わり、ALB と NLB の両方の立ち上げチームの一員でした。
Ishaaq Chandy は、Amazon AI のシニアエンジニアであり、Amazon Sagemaker のための革新的で大規模に拡張可能なトレーニングプラットフォームの構築に関心を寄せています。以前は、AWS ELB に携わり、ALB と NLB の両方の立ち上げチームの一員でした。
 Sumit Thakur は、顧客がクラウドの深い学習を迅速かつ簡単に開始できるようにする製品に取り組んでいます。彼は、Amazon SageMaker と AWS Deep Learning AMI のプロダクトマネージャーです。余暇には、自然に触れたり、SF テレビシリーズを視聴することが好きです。
Sumit Thakur は、顧客がクラウドの深い学習を迅速かつ簡単に開始できるようにする製品に取り組んでいます。彼は、Amazon SageMaker と AWS Deep Learning AMI のプロダクトマネージャーです。余暇には、自然に触れたり、SF テレビシリーズを視聴することが好きです。