Artificial Intelligence
Using Pipe input mode for Amazon SageMaker algorithms
Today, we are introducing Pipe input mode support for the Amazon SageMaker built-in algorithms. With Pipe input mode, your dataset is streamed directly to your training instances instead of being downloaded first. This means that your training jobs start sooner, finish quicker, and need less disk space. Amazon SageMaker algorithms have been engineered to be fast and highly scalable. This blog post describes Pipe input mode, the benefits it brings, and how you can start leveraging it in your training jobs.
With Pipe input mode, your data is fed on-the-fly into the algorithm container without involving any disk I/O. This approach shortens the lengthy download process and dramatically reduces startup time. It also offers generally better read throughput than File input mode. This is because your data is fetched from Amazon S3 by a highly optimized multi-threaded background process. It also allows you to train on datasets that are much larger than the 16 TB Amazon Elastic Block Store (EBS) volume size limit.
Pipe mode enables the following:
- Shorter startup times because the data is being streamed instead of being downloaded to your training instances.
- Higher I/O throughputs due to our high-performance streaming agent.
- Virtually limitless data processing capacity.
Built-in Amazon SageMaker algorithms can now be leveraged with either File or Pipe input modes. Even though Pipe mode is recommended for large datasets, File mode is still useful for small files that fit in memory and where the algorithm has a large number of epochs. Together, both input modes now cover the spectrum of use cases, from small experimental training jobs to petabyte-scale distributed training jobs.
Amazon SageMaker algorithms
Most first-party Amazon SageMaker algorithms work best with the optimized protobuf recordIO format. For this reason, this release offers Pipe mode support only for the protobuf recordIO format. The algorithms in the following list support Pipe input mode today when used with protobuf recordIO-encoded datasets:
- Principal Component Analysis (PCA)
- K-Means Clustering
- Factorization Machines
- Latent Dirichlet Allocation (LDA)
- Linear Learner (Classification and Regression)
- Neural Topic Modelling
- Random Cut Forest
Benchmarks
To show you the benefits of Pipe mode, we ran jobs with the first-party PCA and K-Means algorithms over the New York City taxi trip record dataset. This dataset is publicly available in the AWS Open Data Registry.
For the following benchmarks, we converted the original dataset to the protobuf recordIO format using the SageMaker Python SDK. The conversion’s outcome was 1674 files with a total size of 78.1 GiB. We then uploaded this new dataset to an Amazon S3 path and made it accessible to the training instances.
The first benchmark that follows compares Pipe mode against File mode using the PCA algorithm. Both jobs are run with an identical set of hyperparameters.
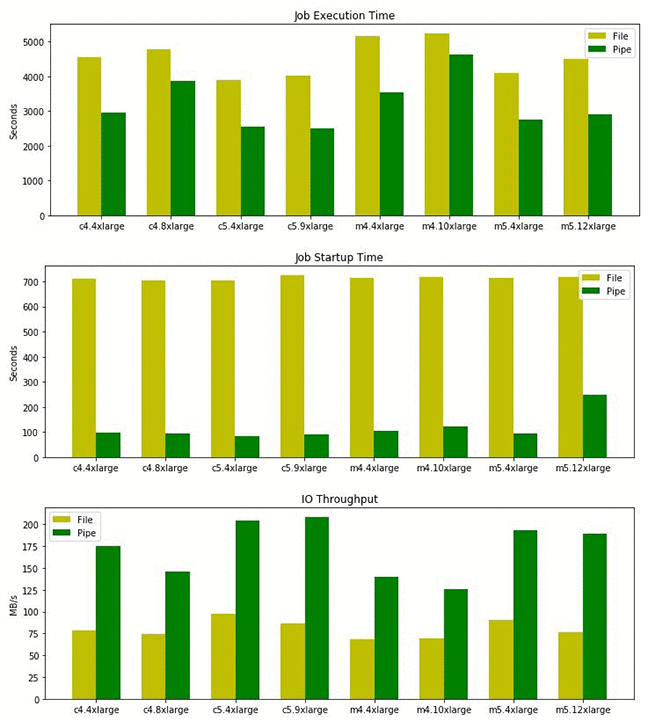
With Pipe mode, the startup time is reduced significantly from 11.5 minutes to 1.5 minutes in most experiments. Also the overall I/O throughput is at least twice as fast as that of File mode. Both of these improvements made a positive impact on the total training time, which is reduced by up to 35%.
Next, we used the same dataset with the K-Means algorithm, which is computationally much more intensive than PCA and also requires high network bandwidth for parameter server communication. We ran training jobs for three epochs in three-machine clusters.
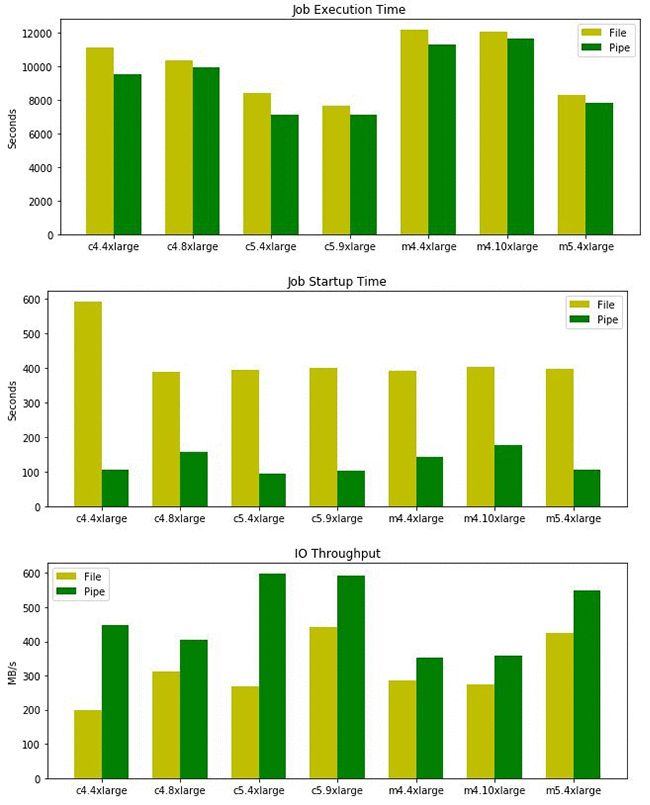
Again, the startup times with Pipe mode are significantly faster than those of File mode, as expected. And although File mode can leverage the file system cache for secondary epochs, the overall I/O throughput with Pipe mode is still faster than file mode. Because K-Means is mostly compute bound, the impact of Pipe mode on the total training time is less dramatic compared to PCA but still significant. Overall, Pipe mode jobs finished 10 to 25 minutes earlier than their File mode counterparts, while using only 10 GB EBS volumes. Note that PCA and K-Means models are far smaller than this 10 GB, but more complex models (particularly those with checkpoints) could surpass this in some cases.
How to use pipe mode
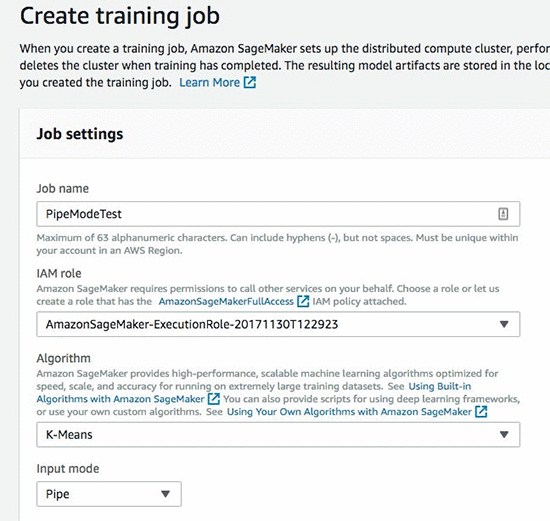
Amazon SageMaker console
Leveraging the benefits of Pipe mode in your training jobs is very straightforward. If you are using the Amazon SageMaker console, you simply need to specify Pipe as your job’s input mode.
Amazon SageMaker Python SDK
The Amazon SageMaker Python SDK provides an easy way to run training and inference jobs programmatically. The SDK hides the technical details and offers a clean API to Amazon SageMaker. In the following code, we submit a new PCA training job using the SageMaker Python SDK. Notice that leveraging Pipe mode involves only changing the value of the input_mode parameter.
AWS SDK for Python (Boto3)
If you prefer low-level programmatic access, you can use the AWS SDK for Python (Boto3) to initiate training jobs with Pipe mode. In the following code, you can see how you can submit a new PCA job using the Boto3 Python client. Again, the only change required is setting input_mode as “Pipe”.
Conclusion
With the newly-introduced Pipe input mode support, you can now run your training jobs with built-in Amazon SageMaker algorithms faster than ever. It seamlessly integrates with the existing algorithms and requires no change in how you store your datasets. Just specifying “Pipe” as the input mode for your training jobs is enough to start taking advantage of Pipe mode today.
About the Authors
 Can Balioglu is a Software Development Engineer on the AWS AI Algorithms team where he is specialized in high-performance computing. In his spare times he loves to play with his homemade GPU cluster.
Can Balioglu is a Software Development Engineer on the AWS AI Algorithms team where he is specialized in high-performance computing. In his spare times he loves to play with his homemade GPU cluster.
 Ishaaq Chandy is a Senior Engineer in Amazon AI where he loves his work in building an innovative and massively scalable training platform for Amazon Sagemaker. Prior to this he was working on AWS ELB where he was part of the launch teams for both ALB as well as NLB.
Ishaaq Chandy is a Senior Engineer in Amazon AI where he loves his work in building an innovative and massively scalable training platform for Amazon Sagemaker. Prior to this he was working on AWS ELB where he was part of the launch teams for both ALB as well as NLB.
 David Arpin is AWS’s AI Platforms Selection Leader and has a background in managing Data Science teams and Product Management.
David Arpin is AWS’s AI Platforms Selection Leader and has a background in managing Data Science teams and Product Management.