Amazon Web Services ブログ
イノベーションの加速: AWS のサーバーレス機械学習は F1 で洞察を得るのにどのように役立つか
FORMULA 1 (F1) は 2020 年に 70 周年を迎えます。これはリアルタイムのスキルとエンジニアリングおよび技術力を組み合わせた数少ないスポーツの 1 つです。F1 では常にテクノロジーが中心的な役割を果たしてきました。ルールとツールの進化が F1 の DNA に組み込まれています。レースは 10 分の 1 秒で雌雄を決するので、ファンは引き込まれ、ドライバーとチームは常に限界にチャレンジし続けています。
ピットストップは 2 秒未満~ 1 分超まで、5G がかかるコーナリングとブレーキング、最高速度は時速 375 km に達し、22 か国でレースが開催されています。その進化と新技術の採用においてこれほどダイナミックなスポーツはありません。FORMULA 1 は継続的にイノベーションを追求しており、最新のイノベーションは、ドライバーとチームが一瞬で決定したことを視聴者に伝えることによって、5 億を超えるファンの成長基盤のエクスペリエンスを強化し、データと分析の力によってトラック上とトラック外で何が起こるかについての理解を向上させています。
各レースカーに 300 のセンサーが装着され、1 秒あたり 1.1M のデータポイントを生成してレースカーからピットに送信されるため、ファンのエクスペリエンスは反応型からリアルタイムにシフトしています。これにより、トラック上でのアクションが加速しています。F1 は、Amazon SageMaker で作成され、AWS Lambda でホストされている機械学習 (ML) モデルなどのクラウドネイティブテクノロジーを活用することで、ドライバーのパフォーマンス、そして限界にチャレンジしているかどうかをピンポイントで調べることができます。その結果、オーバーテイクやピットストップの戦いの結果を予測できます。放送パートナーやデジタルプラットフォームを通じて、世界中のファンとこのような洞察を瞬時に共有できます。
この記事では、Amazon ML Solutions Lab とプロフェッショナルサービスチームが F1 と協力して、AWS テクノロジーを駆使したリアルタイムのレース戦略予測アプリケーションをどう構築して、「ピットウォール」(チームの司令基地) の決定を視聴者に伝えているか、そしてそれがどう Pit Strategy Battle の視覚化につながったかについて詳しく説明します。この記事では、レース戦略とそれをアプリケーションロジックにどう変換するかについて説明します。その際、複数のチームが並走するという概念を逆算して取り組んでいきます。また、サーバーレスアーキテクチャが世界中で最小限のレイテンシーで ML 予測をもたらす方法と、自社の ML ジャーニーを開始する方法についても学習できます。
ピットインするか否か
ファンにとって、20 人のドライバーと 10 のチームがレーストラックにひしめき合っている様子は、カオスのように感じられることもあるでしょう。けれども、ドライバーとエンジニアは、さまざまな戦略を駆使して、レーシングカーの性能をさらに引き出し、競合チームよりも優位に立とうと取り組んでいます。一部はよく計算されたリスクで、他は運を天に任せるようなギャンブルなところもありますが、すべてがレースの結果を左右するほど重要です。時に秒を争うレースになり、アドレナリンが大量に分泌されてファンを呼び戻すことに貢献します。F1 は、このような決定をどう行っているのか、そしてそれがレースが展開されるにつれて戦いにどのような影響を及ぼすのかを垣間見ることができるようにして、ファンのためにベールの裏側をもっと見せたいと考えています。
タイヤの状態は、レースカーのパフォーマンスに影響を与える重要な要素です。タイヤ一式でドライバーが競争力を維持し、レースを完走することは不可能です。チームはさまざまなタイヤのペアの中から、パフォーマンスと耐久性のバランスが取れたものを選択します。より柔らかいペアは、タイヤ急速に劣化するのと引き換えに優れたグリップとハンドリングを提供し、より硬いペアは、優れた耐久性を提供しますが、コーナリングの速度とトラクションを制限します。ドライバーとチームは、ピットインのタイミングと頻度を決定しますが、ルール上は、ドライバーはグランプリごとに少なくとも 1 回はピットストップを行う必要があります。
新品のタイヤセットは、車両のパフォーマンスを大幅に向上させ、ドライバーが別の車を追い抜くことができる可能性を高めます。ただし、これにはコストがかかります。ピットストップを実行するには平均で約 20 秒かかるからです。慎重に計画し、対戦相手のピットインのタイミングを念頭に置いていつピットインするかをよく考えて実行すると、勝利につながる利点が得られます。
ドライバー 1 とドライバー 2 の 2 人のドライバー間の戦いを想像してみてください。ドライバー 1 がリードしてそのポジションを守ろうとしています。ドライバー 2 は追い越しを試みるために差を詰めようととしています。その速いペースをもってしても、追い越すことは至難の業であるのは明らかです。両ドライバーが少なくとも一度はタイヤを交換する必要があることを考えると、ドライバー 2 はパフォーマンス上の利点を得るために最初にピットインすることを選択するかもしれません。ドライバー 1 のタイヤの劣化がパフォーマンスの制約になっているため、早い段階でピットインすることで、ドライバー 2 は優位に車両同士の差を詰めることができます。ドライバー 2 がピットイン後にドライバー 1 に追いついた場合、ドライバー 1 が最終的にピットインに追い込まれたときにドライバー 2 が追い越すことができます。この戦略はアンダーカットと呼ばれています。

これは言わずもがなかもしれませんが、その反対の戦略であるオーバーカットも時に奏功します。ドライバー 2 は、ドライバー 1 が最初にピットインし、おそらくドライバー 1 のタイヤの摩耗が早いことを期待して、自分の車両をできるだけ遠くまで運ぶようにする場合があります。ここで計算されているのは、前方にドライバー 1 の車がないことでドライバー 2 が先に進むことができる利点であるかもしれません。この戦略をうまく実行すると、後行車は最終的なピットストップの後で先行車を追い越すことができます。トラックに 3 人以上のドライバーがいる場合、事態はすぐに複雑になります。あるドライバーは後行車ですが、他のドライバーにとってはその人は先行車で、そのような戦いが複数のラップにわたって展開される場合があります。混沌としたレースの中で、観客はどのドライバーが有利で、どの戦略をチームが採用しているかを追跡することはほぼ不可能です。最もダイハードな F1 ファンでさえ、複雑な事態をシンプルにするデータ分析の恩恵を受けています。
F1 は AWS と提携して、F1 で新たな洞察を構築しています。逆算して ML モデルを構築することで、ピットバトルを追跡して観戦体験を向上させることができたのです。
Working Backwards
AWS はお客様を起点に取り組み、そこから逆算していきました。これにより、お客様の価値に対してアイデアを検証する必要が出てきました。Working Backwards ドキュメントには 3 つの部分があります。その 3 つとは、顧客中心の言語を使用して高レベルでアイデアを説明するプレスリリース、顧客や内部の利害関係者が尋ねる可能性があるよくある質問、およびアイデアを伝えるのに役立つビジュアルです。アイデアのメリットを比較検討するときは、考えられるすべてのエクスペリエンスの結果を描き出すことが重要です。それはホワイトボードスケッチ、ワークフロー図、またはワイヤーフレームの形になるかもしれません。以下は、Pit Strategy Battle のユースケースの最初のビューです。
この概念図により、利害関係者は、グラフィックスアプリケーション、アプリケーション開発、ML モデルなど、さまざまな結果と目標に合わせて調整できます。そして小さなユーザーグループでテストして、望ましい結果を確認できます。また、さまざまなグラフィックワイヤーフレームの開発 (グラフィック)、データの収集 (運用)、レースロジックのアプリケーションロジックへの変換 (開発チーム)、ML モデルの構築 (ML チーム) など、作業をチャンクに分割して並列処理することもできます。
Working Backwards モデルは、最初から明確なビジョンをもたらしました。当社は F1 の放送パートナーと協力して、使用するメッセージとフォーマットのタイプを調整し、イラストレーターはオンスクリーングラフィックチームの概念実証として動画を作成しました。
Amazon SageMaker ノートブックを使用して探索的分析を行い、Amazon S3 にアップロードされた大量のタイミングデータ、タイヤデータ、気象データを視覚化しました。これにより、アルゴリズムの観点からレースがどのように見えるかを理解できました。過去のレースで使用した戦略と、結果を左右した要因を特定し、レースを際限なく再現しました。これにより、当社の ML モデルのために抽出できる過去のフィーチャと、ライブレースでそのようなフィーチャをどのように抽出するかを確認しました。
さまざまなソースから関連データを抽出してクリーンアップした後、ML タスクを開始しました。ML プロジェクトを開始するとき、達成できる最良の結果は何かに確信が持てることはほとんどありません。すばやく実験して反復するために、次の 2 つの主要業績評価指標 (KPI) を設定しました。
- ビジネス KPI – これは、すべての関連する利害関係者に特定の境界内の予測の割合などの進捗状況を伝えるように設計されています。
- テクニカル KPI – これは、二乗平均平方根誤差など、モデルを最適化するために使用します。
これらの KPI、技術要件、およびセット出力形式を検証コードで使用して、機能エンジニアリングとさまざまなアルゴリズムをすばやく試して、予測エラーを最適化することができます。
アーキテクチャーの実装
アプリケーションアーキテクチャの外観を設計するとき、多くの要件に直面しました。中には、一見矛盾しているように見えるものもありました。クラウドネイティブの AWS のサービスを使用しながら、重要なことに集中し、メンテナンスにほとんどオーバーヘッドをかけずに、目標を達成しました。また、従量課金制のモデルにより、コストを比較的低く抑えることができました。
アーキテクチャの概要
次の図は、アーキテクチャを詳細に示しています。
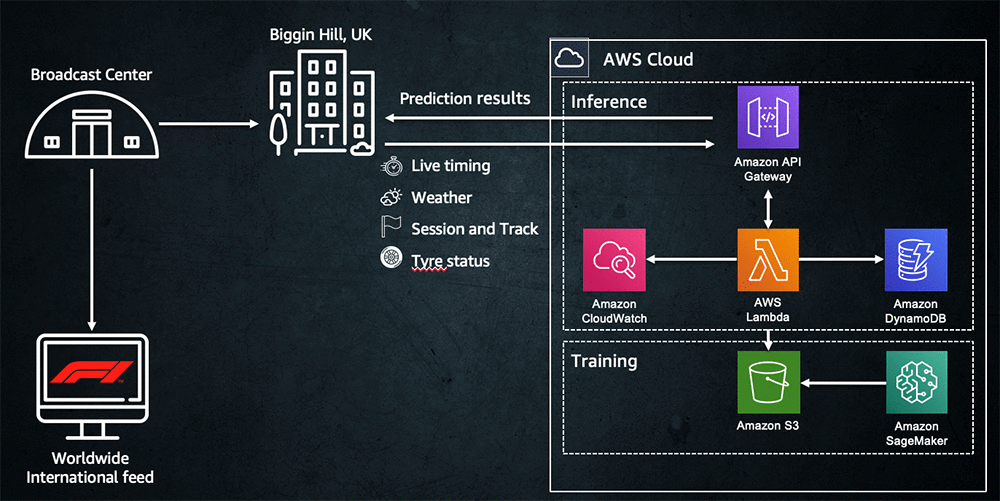
信号がレーストラックでキャプチャされると、信号は最初に F1 インフラストラクチャを経由して、次に HTTP 呼び出しとして AWS クラウドへと通過します。Amazon API Gateway は、レースロジックを実装する Lambda の関数としてホストされるアプリケーションへのエントリポイントとして機能します。関数が着信メッセージを受信すると、Amazon DynamoDB に保存されているレース状態を更新します (たとえば、ドライバーの位置の変更)。更新が完了すると、関数はこれが予測のトリガーであるかどうかを評価します。そうである場合は、Amazon SageMaker でトレーニングされたモデルを使用して予測を行います。予測は、呼び出しへの応答として送り返され、F1 インフラストラクチャに取り込まれます。放送センターに戻り、レースディレクターが使用できるようになります。プロセス全体を 500 ミリ秒未満で完了する必要がありました。
適切なツールの選択
最初の課題は、特に厳しい締め切りを考えると、どのアプローチが効果的かを事前に知らなかったことでした。プロトタイプを迅速に作成、検証、および実験し、概念実証から本番環境対応のアプリケーションにすばやく移行できるようにする一連のツールを選択する必要がありました。Lambda、API Gateway、DynamoDB、Amazon CloudWatch、S3 など、AWS が提供するサーバーレス製品を駆使しました。たとえば、操作のオーバーヘッドゼロで Lambda でプロトタイプをホストし、結果に満足したら、簡単なスクリプトによりアプリケーションを本番環境に移行できました。Lambda はリクエストの割合が増えると自動的にリソースをスケールアップするため、インフラストラクチャのプロビジョニングについて心配する必要はありませんでした。レースが終了すると、手作業を要さずにリソースが解放されました。予測はライブで行われるため、可用性の高いインフラストラクチャを用意することが重要です。従来、このようなインフラストラクチャを構築するには、専門の熟練したシステムエンジニアのチームが必要でした。Lambda は、あらゆるアプリケーションに可用性の高いインフラストラクチャを事前準備なしに提供します。
アプリケーションがトラックからメッセージを受信したとき、単一のメッセージの内容では予測をトリガーするのに十分ではありませんでした。たとえば、1 人のドライバーが位置を変更しても、トラック上の全体の状況についてはあまりつかめません。予測はコース上の過去と現在の状況を含む包括的なインプットの形をとるので、レースの状態を保存および管理するためにデータベースを採り入れる必要がありました。DynamoDB は、レース状態、タイミングデータ、モニタリングしている戦略、ML モデルの機能を保存するための重要なツールでした。DynamoDB は、テーブルの行数に関係なく、1 桁のミリ秒のパフォーマンスを提供し、運用上のオーバーヘッドはありません。データベースクラスターの起動と管理に時間を費やす必要はなく、稼働時間の心配も無用でした。
プロトタイプから本番環境への反復を自動化するために、AWS CodePipeline や AWS CodeBuild などの CI/CD ツールを使用して、環境を分離し、準備ができたときにコードを本番環境に移行しました。AWS CloudFormation を使用して、Infrastructure as Code (IaC) と呼ばれるアプローチを実装し、環境をプロビジョニングして、予測可能なデプロイを実現しました。
これらのリソースはそのほとんどをライブレースまたはテスト中にのみ使用したため、消費したリソースに対してのみ支払いたいと考えました。過剰なプロビジョニングにコストがかかるのを回避するには、コンポーネントを手動で開始および停止する必要があります。使用したサービスは、従量課金制のモデルで請求されます。請求書には使用したストレージの正確な量のみが含まれており、呼び出しの数によってコンピューティングリソースの料金が決まりました。これは、SageMaker エンドポイントでモデルをホストする代わりに Lambda でモデルをホストしたために可能でした。Lambda でのモデルのホスティングの詳細については、こちらのブログ記事をご覧ください。
精度とパフォーマンス
ML モデルに関しては、精度とランタイムパフォーマンスに基づいて要件を設定しました。精度を達成するために、アプローチをすばやくテストし、実験し、繰り返すことができるツールが必要でした。モデルをトレーニングするために、Amazon SageMaker を使用しました。その組み込みアルゴリズムの XGBoost は、グラディエントブーストツリーアルゴリズムの一般的で’効率的なオープンソース実装です。レースデータとモデル予測を慎重に分析して、レースデータで利用できるフィーチャを抽出しました。モデルと入力フィーチャの最適な設計が完了したら、Amazon SageMaker のトレーニングジョブを使用して、過去のレースデータでモデルをトレーニングしました。このフィーチャの利点は、データサイエンティストがモデルの最適化に集中できる一方で、リソースのプロビジョニングとプロビジョニング解除を完全に実装できることです。さらに、SageMaker では、トレーニングに使用するインスタンスタイプとインスタンス数を制御できます。これは、大きなデータセットをトレーニングする場合に特に便利です。
アルゴリズムのトレーニング時間は難なく進みましたが、推論はリアルタイムで行わなければなりませんでした。F1 は、世界中の何億人もの視聴者にライブストリームを提供しています。ミリ秒単位で雌雄を決するスポーツにあっては、数秒前のデータでも使いものになりません。必要な応答時間を満たすために、Amazon SageMaker でトレーニングされたモデルを Lambda でホストされているアプリケーションにロードし、関数コードに推論を実装しました。モデルは実行中のコードのすぐ隣のメモリに読み込まれたままなので、呼び出しのオーバーヘッドを最小限に抑えることができます。組み込みのオープンソースアルゴリズム XGBoost を使用してモデルをトレーニングしました。追加のオープンソースパッケージを使用して、モデルをより小さくより高性能な形式で記録しました。これにより、推論速度が向上し、デプロイサイズが縮小されました。アプリケーションとモデルを Lambda でホストしたため、インフラストラクチャを伸縮自在にスケーリングし、操作の介入なしでレース中のさまざまな予測率に簡単に対応できました。
ツールとサービスの選択は、プロジェクトが成功する要です。AWS が提供する幅広く奥深いサービスのおかげで、要件と運用モデルに最適なツールを選ぶことができました。また、サーバーレステクノロジーにより、インフラストラクチャの維持に費やす時間が解放され、最も重要なことに集中できるようになりました。
結果
Pit Strategy Battle の洞察は、2019 年 3 月 17 日、2019 F1 シーズンの公式スタートであるオーストラリアグランプリでリリースされました。ポテンシャルを最大限発揮した Pit Strategy Battle のグラフィックを示すために、3 月 31 日にバーレーンに足を運び、バーレーングランプリに参加しました。このグランプリは 2019 シーズンで最も爽快なレースの 1 つで、アンダーカット戦略を実行する Mercedes がトップクラスの実力を示す檜舞台でもありました。次の短いクリップは、Hamilton が 1 周前のピットストップで新しいタイヤに交換して Vettel を追いかけ、14 周目でピットストップをしている間に Vettel を追い越そうとしている様子が収録されています。
動画では、Hamilton がアンダーカットをどのように成功させたかを見ることができます。グラフィックは、サスペンスを構築し、視聴者がトラックで何が起こっているのかを理解するのに役立ちました。アプリケーションは、履歴データでトレーニングした ML モデルを使用して、予測された時間ギャップと追い越し確率の両方のライブ予測を提供しました。これらはすべて 500 ミリ秒以内に行われました。
まとめ
F1 の技術革新の歴史にもかかわらず、現在収集できるデータから取りかかり、各レースカーの 300 以上のセンサーが毎秒 110 万以上のデータポイントを生成しています。この記事では、AWS プロフェッショナルサービスチームが F1 と協力してこのデータを取り込み、ML と分析を実行してファンが洞察を得てレースをよりよく理解できるようにする方法を示しました。複数のチームの間で共通の理解を生み出し、逆算して作業することで最終目標を明確にしました。それにより、各チームは並行して作業できるようになりました。これにより、プロジェクトの進捗状況が大幅に改善され、ボトルネックが解消されました。
他のビジネスと同様に、F1 はカオスの中に理を見つけようとしています。ここで使用した上位レベルのサービスと基本原則はあらゆる業界に適用することができます。アプリケーションホスティングに Lambda、ストレージに DynamoDB、モデルトレーニングに Amazon SageMaker を使用することで、デベロッパーとデータサイエンティストは重要なことに集中できます。インフラストラクチャの構築とメンテナンスに時間を費やしたり、稼働時間とコストを心配したりすることなく、ビジネス知識をアプリケーションロジックに変換し、実験し、すばやく繰り返すことに集中できます。
それがパーソナライズされた製品を提供するウェブサイトを構築している会社、より効率的に稼働したい工場、または収穫量を増やしたい農場であるかどうかに関係なく、それぞれのビジネスでデータを活用してより迅速に開発し、すばやくスケーリングすることから利益を得ることができます。AWS プロフェッショナルサービスは、専門的なスキルと経験をもってお客様のチームを補完する準備ができており、ビジネスの成果を達成するサポートをさせていただきます。詳細については、AWS プロフェッショナルサービスを参照するか、アカウントマネージャーを通じてご連絡ください。
著者について
 Luuk Figdor は、AWS プロフェッショナルサービスチームのデータサイエンティストです。彼はさまざまな業界のお客様と協力して、機械学習を使ってデータでストーリーを伝える手助けをしています。余暇には、省察したり、心理学、経済学、AI の学際的分野を学んだりするのが好きです。
Luuk Figdor は、AWS プロフェッショナルサービスチームのデータサイエンティストです。彼はさまざまな業界のお客様と協力して、機械学習を使ってデータでストーリーを伝える手助けをしています。余暇には、省察したり、心理学、経済学、AI の学際的分野を学んだりするのが好きです。
 Andrey Syschikov は、AWS プロフェッショナルサービスチームのフルスタック技術者です。彼はお客様がアイデアを革新的なクラウドベースのアプリケーションの形で実現するのをサポートしています。Andrey がコンピュータから離れることは滅多にありませんが、仕事以外ではオーディオブック、ピアノ、ハイキングを楽しんでいます。
Andrey Syschikov は、AWS プロフェッショナルサービスチームのフルスタック技術者です。彼はお客様がアイデアを革新的なクラウドベースのアプリケーションの形で実現するのをサポートしています。Andrey がコンピュータから離れることは滅多にありませんが、仕事以外ではオーディオブック、ピアノ、ハイキングを楽しんでいます。