Amazon Web Services ブログ
Amazon Elasticsearch Service が Elasticsearch 5.1 をサポート
Amazon Elasticsearch Service は、オープンソース検索および分析エンジンである Elasticsearch を容易にデプロイ、運用、拡張できるようにするマネージド型サービスです。このたび Amazon Elasticsearch Service で Elasticsearch 5.1 および Kibana 5.1 がサポートされるようになったことを、ここにお知らせいたします。Elasticsearch 5 は非常に多くの新機能と機能拡張を備えており、Amazon Elasticsearch Service をご利用のお客様はそれらを活用いただけるようになりました。今回の Elasticsearch 5 のリリースには、次のような内容が含まれています。
- インデックス作成のパフォーマンス: ロックの実装の更新および非同期のトランザクションログ FSYNC による、インデックス作成のスループットの向上
- 取り込みパイプライン: 受信データは一連の取り込みプロセッサを適用するパイプラインに送信できます。これにより検索インデックスに必要なデータに正確に変換できます。単純な付加アプリケーションから複雑な正規表現アプリケーションまで、20 個のプロセッサが含まれています
- Painless スクリプティング: Amazon Elasticsearch Service は Elasticsearch 5 のための新しい安全でパフォーマンスに優れたスクリプト言語である、Painless をサポートします。スクリプト言語を使用すると、検索結果の優先順位を変更したり、クエリでインデックスフィールドを削除したり、検索結果を修正して特定のフィールドを戻したりすることができます。
- 新しいデータ構造: 新しいデータ型である Lucene 6 データ構造をサポートし、半精度浮動小数点、テキスト、キーワード、さらにピリオドが含まれるフィールド名を完全にサポートします
- 検索と集計: リファクタリング検索 API、BM25 関連性計算、Instant Aggregations、ヒストグラム集計と用語集計の機能強化、再設計されたパーコレーターと完了サジェスタ
- ユーザーエクスペリエンス: 厳密な設定、本文とクエリ文字列パラメーターの検証、インデックス管理の向上、デフォルトで廃止予定のログを記録、新しい共有割り当て API、ロールオーバーと圧縮 API のための新しいインデックス効率パターン
- Java REST クライアント: Java 7 で稼働してノード障害時に再試行 (またはラウンドロビン、スニッフィング、要求のログ記録) を処理するシンプルな HTTP/REST Java クライアント
- その他の向上: 遅延ユニキャストのホスト DNS ルックアップ、再インデックス作成の自動並列タスク、update-by-query、delete-by-query、タスク管理 API による検索のキャンセル
Elasticsearch 5 による強力な新機能や機能強化により、サービスをより迅速に、より容易に提供することができ、さらにセキュリティの強化を図ることができます。マネージド型サービスである Amazon Elasticsearch Service を使うと、お客様は Elasticsearch による次のような機能を活用して、ソリューションを構築、開発、デプロイすることができます。
- 複数のインスタンスタイプを設定
- データストレージに Amazon EBS ボリュームを使用
- 専用マスターノードによるクラスターの安定性の向上
- ゾーン対応 – 同じリージョン内の 2 つのアベイラビリティーゾーンにまたがるクラスターノード割り当て
- AWS Identity and Access Management (IAM) によるアクセスコントロールとセキュリティ
- リソース用にさまざまな地理的場所やリージョンを活用
- Amazon Elasticsearch ドメインのスナップショットによるレプリケーション、バックアップ、リストア
- Amazon CloudWatch との統合による Amazon Elasticsearch ドメインメトリクスのモニタリング
- AWS CloudTrail との統合による設定の監査
- Kinesis Firehose および DynamoDB などの他の AWS のサービスとの統合による、リアルタイムストリーミングデータの Amazon Elasticsearch Service への読み込み
Amazon Elasticsearch Service では、ダウンタイムなしで動的な変更を行うことができます。インスタンスの追加、インスタンスの削除、インスタンスのサイズの変更、ストレージ設定の変更、その他の変更を動的に行うことができますい。上記の機能のいくつかについて、その機能を具体例でご紹介します。先日の IT/Dev カンファレンスでは、Express.js、AWS Lambda、Amazon DynamoDB、および Amazon S3 を使用して、サーバレスで従業員オンボーディングシステムを構築する方法の説明を、プレゼンテーションさせていただきました。このデモでは、架空のオンボーディングプロセス用の従業員に関する人事データを収集して、DynamoDB に保存しました。収集された従業員データを、会社の人事部門が必要に応じて検索、照会、分析するシナリオを考えてみます。オンボーディングシステムを容易に拡張して、従業員テーブルが DynamoDB Streams を使用して Lambda を起動するようにし、必要な従業員の属性を Amazon Elasticsearch Service に保存することができます。この結果、次のようなソリューションアーキテクチャとなります。
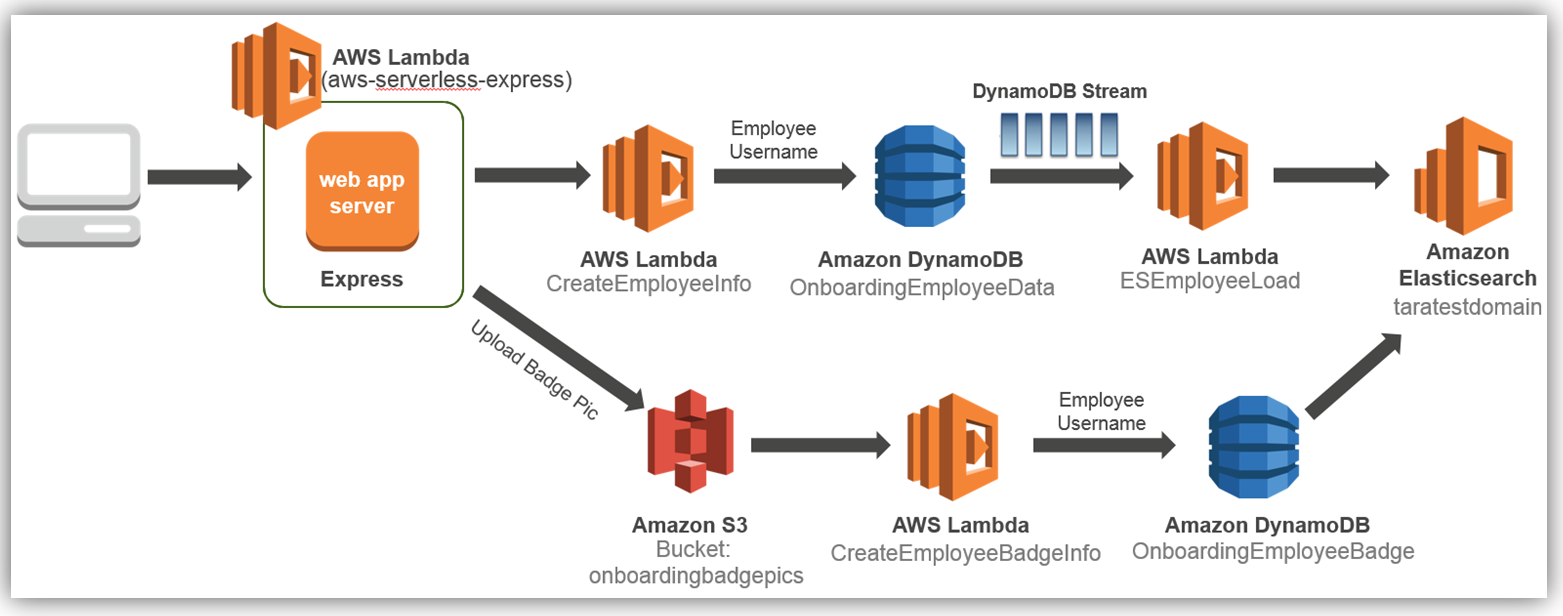
従業員レコードが入力されてデータベースに保存されるたびに、従業員データを Amazon Elasticseach Service に動的に保存してインデックスを作成する方法のみに焦点を当てます。前述の既存のオンボーディングソリューションにこの拡張機能を追加するには、以下の詳細なクラウドアーキテクチャ図に示すように、ソリューションを実装します。
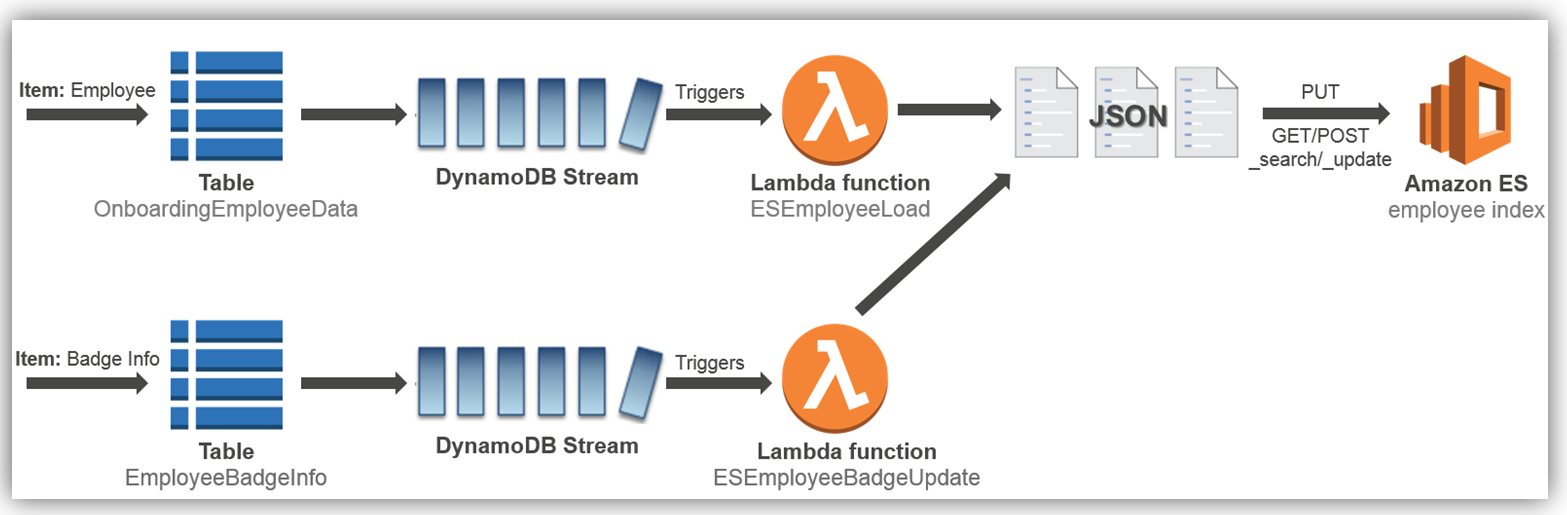
従業員の Amazon Elasticsearch Service へのロードプロセスを実装する方法を見てみましょう。これは上の図に示されている最初のプロセスフローです。Amazon Elasticsearch Service: ドメイン作成 AWS コンソールにアクセスして、Elasticsearch 5 が実行されている Amazon Elasticsearch Service を確認しましょう。ご想像どおり、AWS コンソールのホームから [分析] グループの [Elasticsearch Service] を選択します。
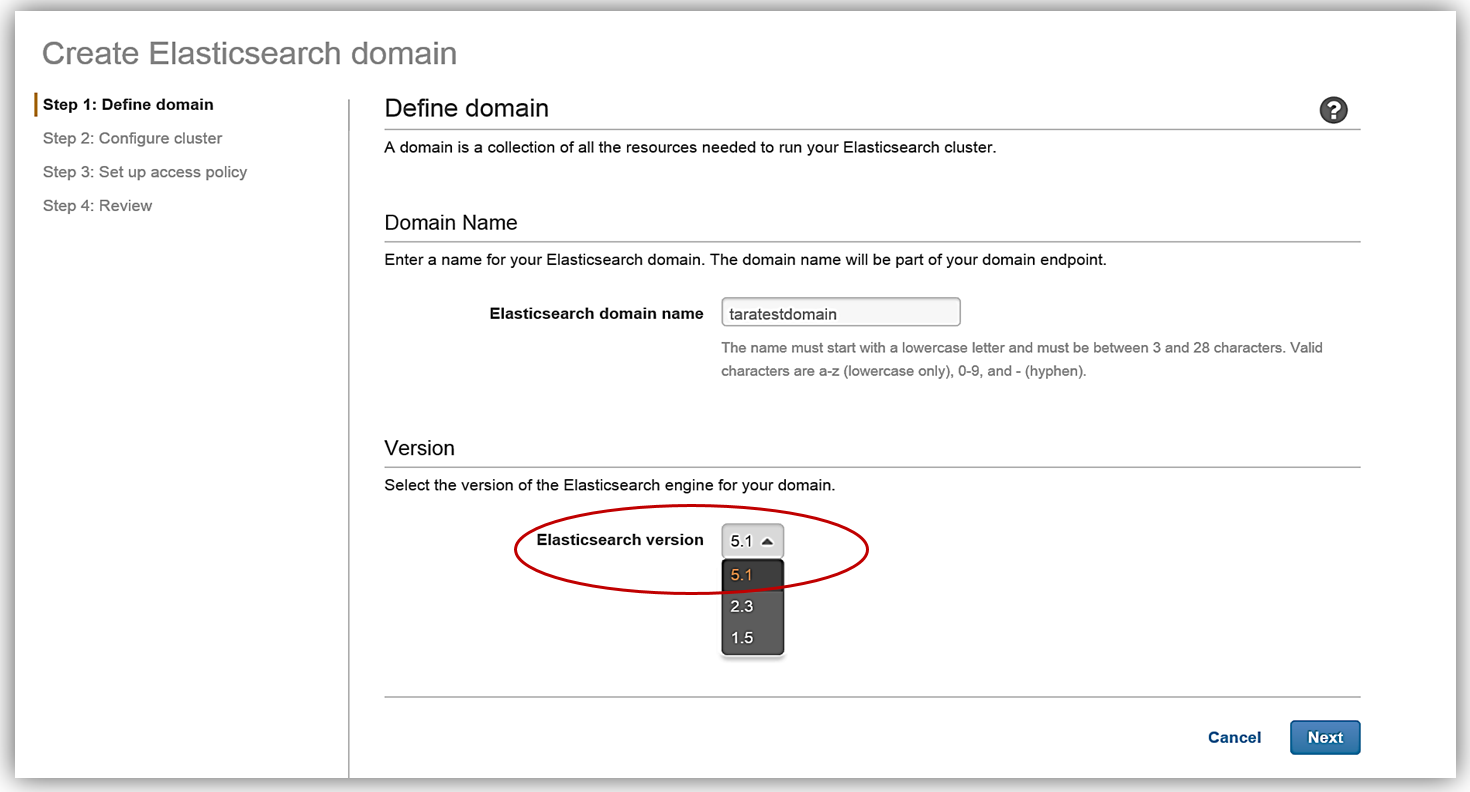
Elasticsearch ソリューションを作成するための最初のステップは、ドメインの作成です。お気付きのとおり、Amazon Elasticsearch Service ドメインの作成時に Elasticsearch 5.1 バージョンを選択できるようになりました。今日の本題は Elasticsearch 5 のサポート開始ですので、Amazon Elasticsearch Service でのドメイン作成にあたり、もちろん 5.1 Elasticsearch エンジンのバージョンを選択します。
[Next] をクリックし、インスタンスとストレージの設定を構成して、Elasticsearch ドメインを設定します。クラスターのインスタンスタイプとインスタンス数は、アプリケーションの可用性、ネットワークボリューム、およびデータのニーズに基づいて決定する必要があります。データの不整合や Elasticsearch のスプリットブレインの問題を回避するために、複数のインスタンスを選択することが推奨されるベストプラクティスです。そこで、今回はクラスター用に 2 つのインスタンス/データノードを選択し、EBS をストレージデバイスとして設定します。
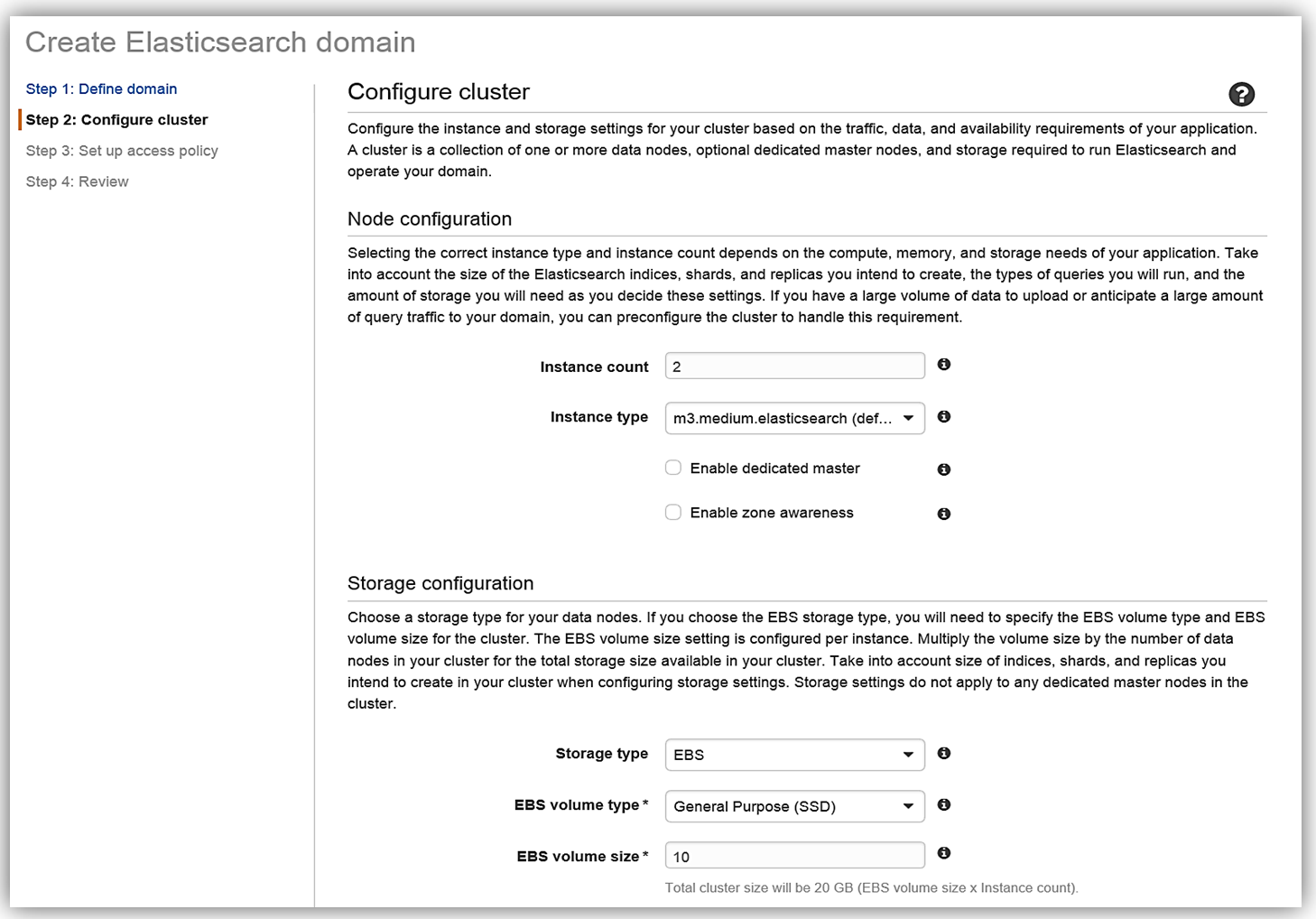
具体的なアプリケーションに必要なインスタンスの数を理解するには、AWS データベースブログの「Get Started with Amazon Elasticsearch Service: How Many Data Instances Do I Need (Amazon Elasticsearch Service をはじめよう: 必要なインスタンス数の算出方法)」の記事を参照してください。あと必要なのは、アクセスポリシーを設定してサービスをデプロイするだけです。サービスを作成すると、ドメインが初期化され、デプロイされます。
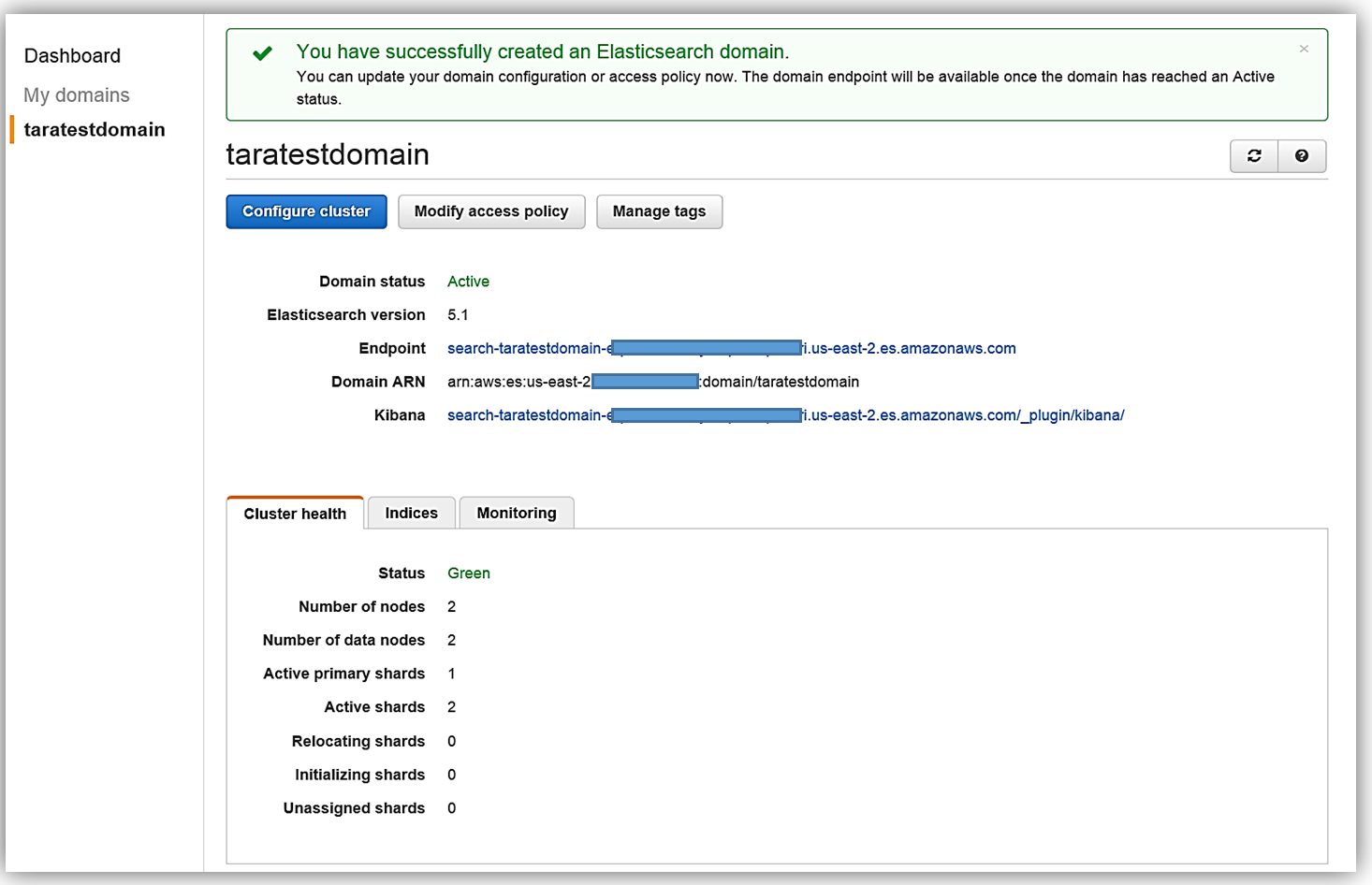
これで Elasticsearch Service を実行することができました。次は、データを入力するメカニズムが必要です。DynamoDB Streams を使用して、Amazon Elasticsearch Service への従業員データの動的なデータロードプロセスを実装します。Amazon DynamoDB: テーブルとストリーム DynamoDB コンソールに着手する前に、まずは基本を簡単に確認しましょう。 Amazon DynamoDB はスケーラブルな分散 NoSQL データベースサービスです。DynamoDB Streams は、すべての CRUD オペレーションの順序付けられた時間ベースのシーケンスを DynamoDB テーブル内の項目に提供します。各ストリームレコードには、テーブル内の個々の項目のプライマリ属性の変更に関する情報が含まれています。ストリームは非同期で実行され、実質的にリアルタイムでストリームレコードを書き込むことができます。さらに、ストリームはテーブルの作成時に有効にでき、また既存のテーブルで有効にして変更することができます。DynamoDB Streams の詳細については、「DynamoDB 開発者ガイド」を参照してください。それでは DynamoDB コンソールから、OnboardingEmployeeData デーブルを確認しましょう。
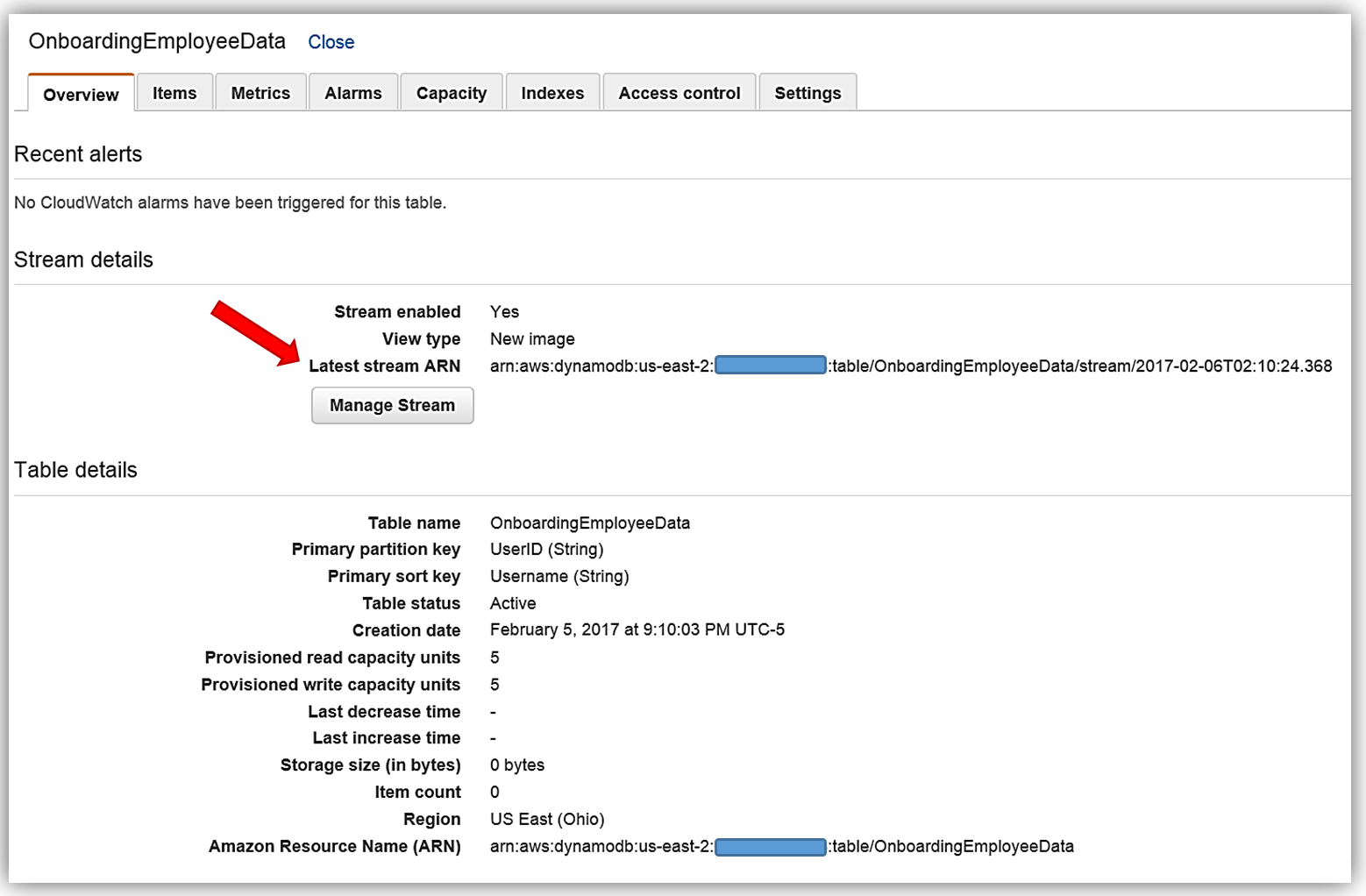
このテーブルには、プライマリパーティションキー UserID があり、これは文字列データ型です。さらにプライマリソートキー Username があり、これも文字列データ型です。ここでは UserID を Elasticsearch のドキュメント ID として使用します。さらにこのテーブルではストリームが有効で、ストリームの表示タイプは New image です。表示タイプが New image に設定されたストリームには、更新された後に項目レコード全体を表示するストリームレコードがあります。ストリームが、変更前のデータ項目を提供するレコードを表示するようにすることもできます。また項目のキー属性のみを提供したり、古い項目と新しい項目の情報を提供したりすることもできます。AWS CLI を使用して DynamoDB テーブルを作成する場合、取得するキー情報は [Stream Details] セクションの下に表示される 最新のストリーム ARN です。DynamoDB ストリームには一意の ARN 識別子があります。これは DynamoDB テーブルの ARN の外にあります。ストリーム ARN は、ストリームと Lambda 関数の間のアクセス権限の IAM ポリシーを作成するために必要です。

IAM ポリシー あらゆるサービスの実装で第一に重要なことは、適切なアクセス権限を設定することです。このため、まずは IAM コンソールを使って、DynamoDB と Elasticsearch にアクセス権限を設定する、Lambda 関数のロールとポリシーを作成します。まず、DynamoDB ストリームを使用した Lambda の実行のための既存の管理ポリシーに基づくポリシーを作成します。
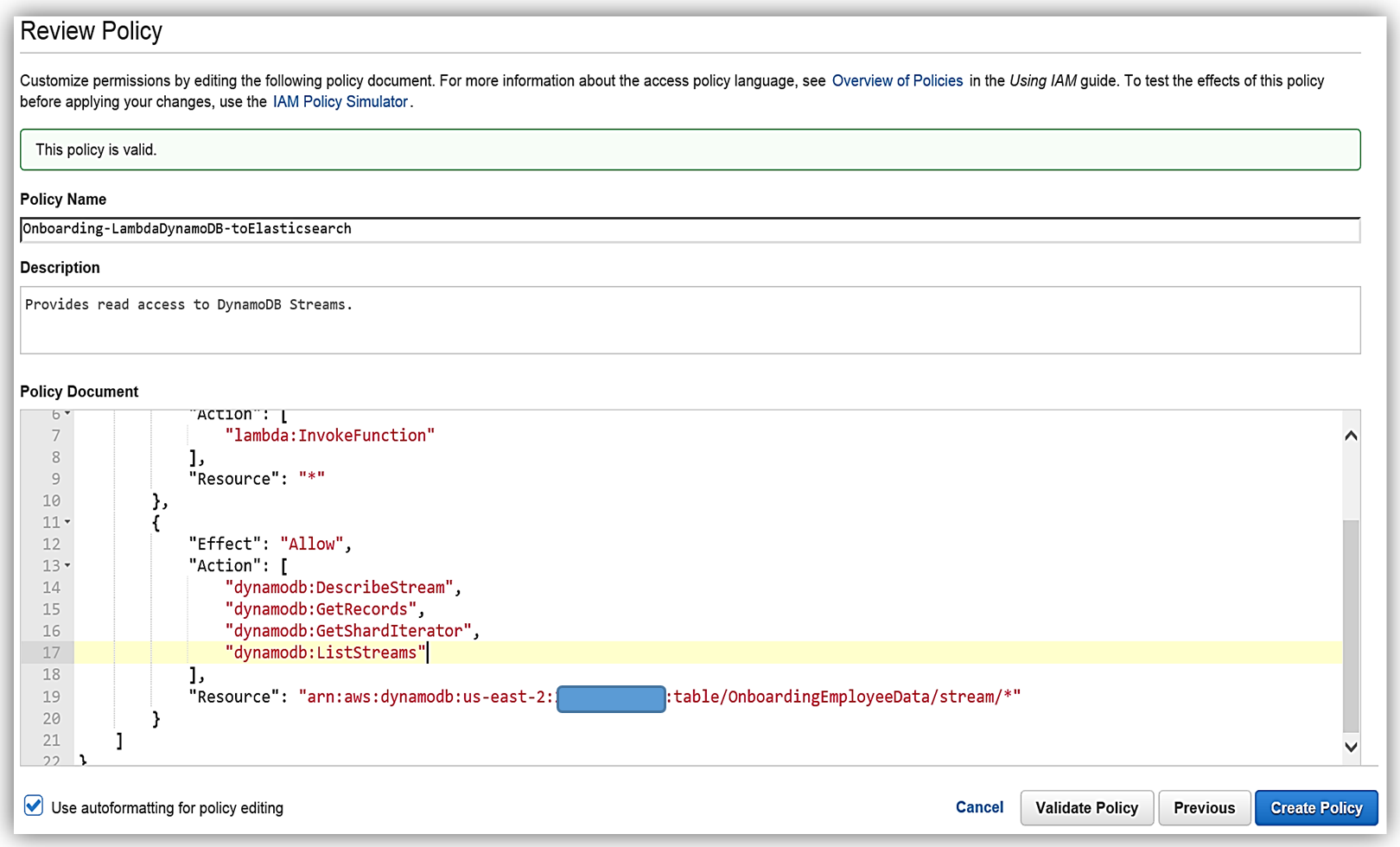
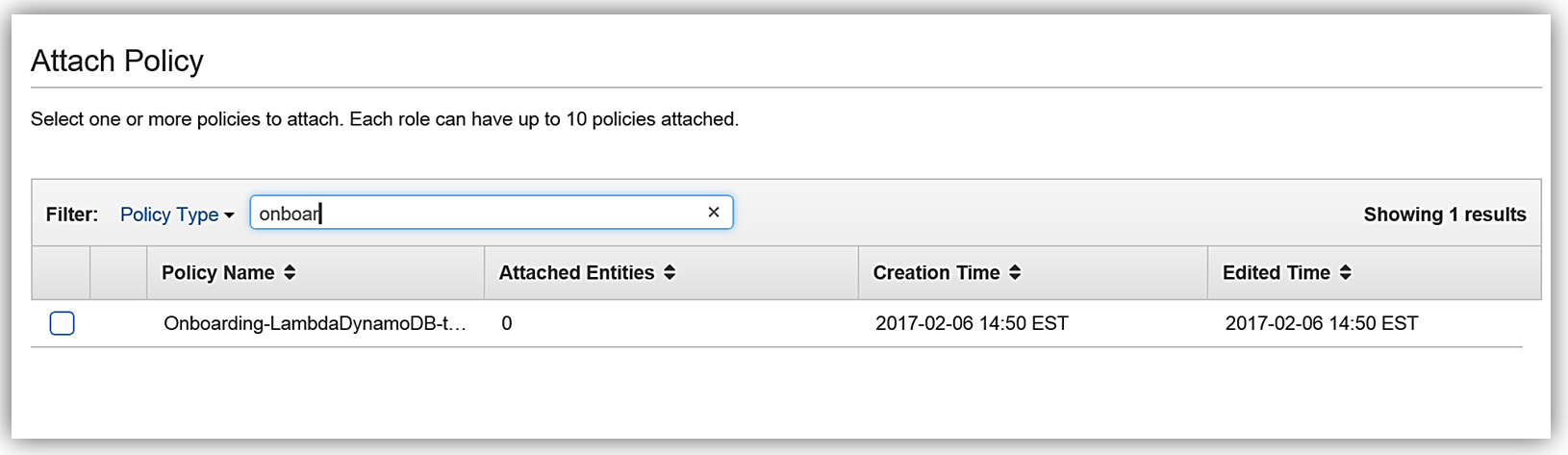
すると次にポリシーの確認画面に移ります。ここでは選択された管理ポリシーの詳細が表示されます。ここでは、このポリシーの名前を Onboarding-LambdaDynamoDB-toElasticsearch として、ソリューション用にポリシーのカスタマイズを行います。現在のポリシーでは、すべてのストリームがアクセス可能であることに注意します。推奨されるベストプラクティスは、最新のストリーム ARN を追加して、このポリシーで特定の DynamoDB ストリームのみがアクセスできるようにすることです。ポリシーを変更して、DynamoDB テーブル OnboardingEmployeeData に ARN を追加し、ポリシーを検証します。変更されたポリシーは次のようになります。
あとは、Amazon Elasticsearch Service のアクセス権限をポリシーに追加するだけです。Amazon Elasticsearch Service のアクセス権限のコアポリシーは次のとおりです。

このポリシーを使って、特定の Elasticsearch ドメインの ARN を、ポリシーのリソースとして追加します。これにより、ポリシーのセキュリティのベストプラクティスである、最小権限の原則を適用したポリシーを活用することができます。次のように Amazon Elasticsearch Service ドメインを追加して、ポリシーを検証して保存します。
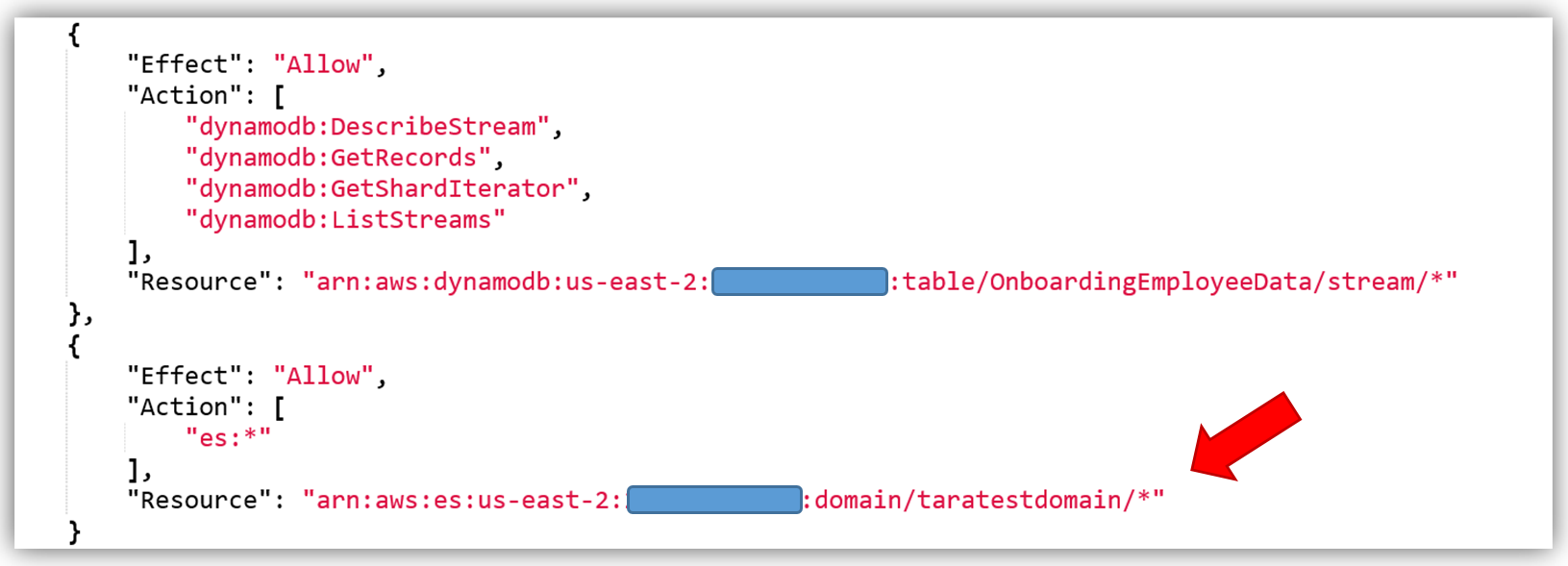
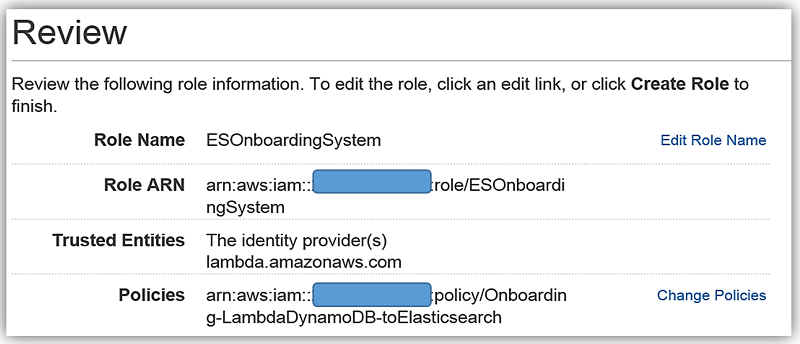
カスタムポリシーを作成する最も望ましい方法は、IAM Policy Simulator を使用するか、またはサービスドキュメントの AWS のサービスのアクセス権限の例を参照することです。AWS のサービスのサブセットのポリシーの例については、こちらを参照することもできます。最小権限の原則によるセキュリティのベストプラクティスを適用して、必要な ES のアクセス権限のみを追加してください。上記は単なる一例です。アクセスを許可するために Lambda 関数が使用するロールを作成し、そのロールに前述のポリシーをアタッチします。
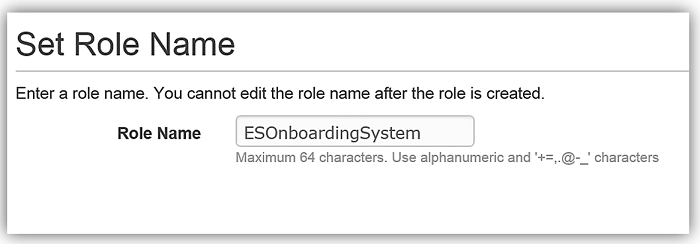
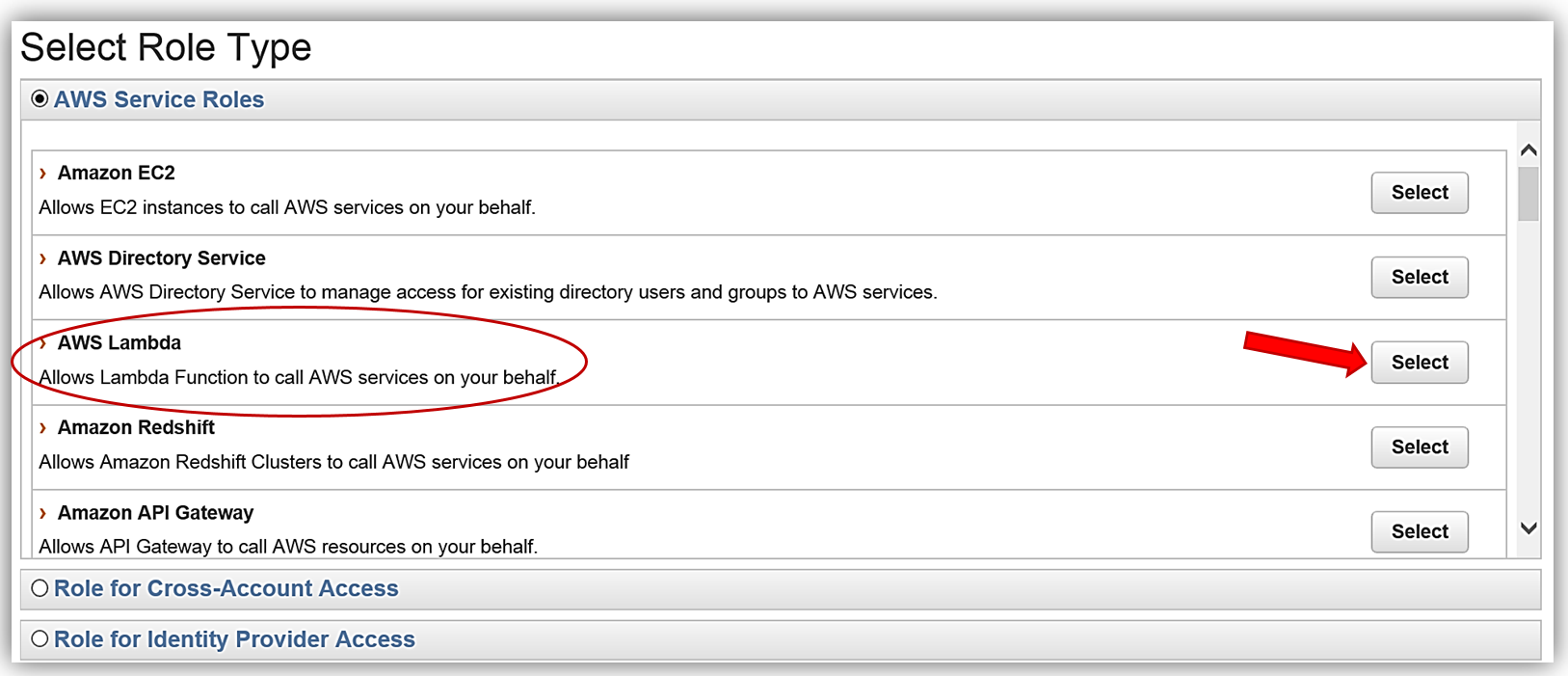
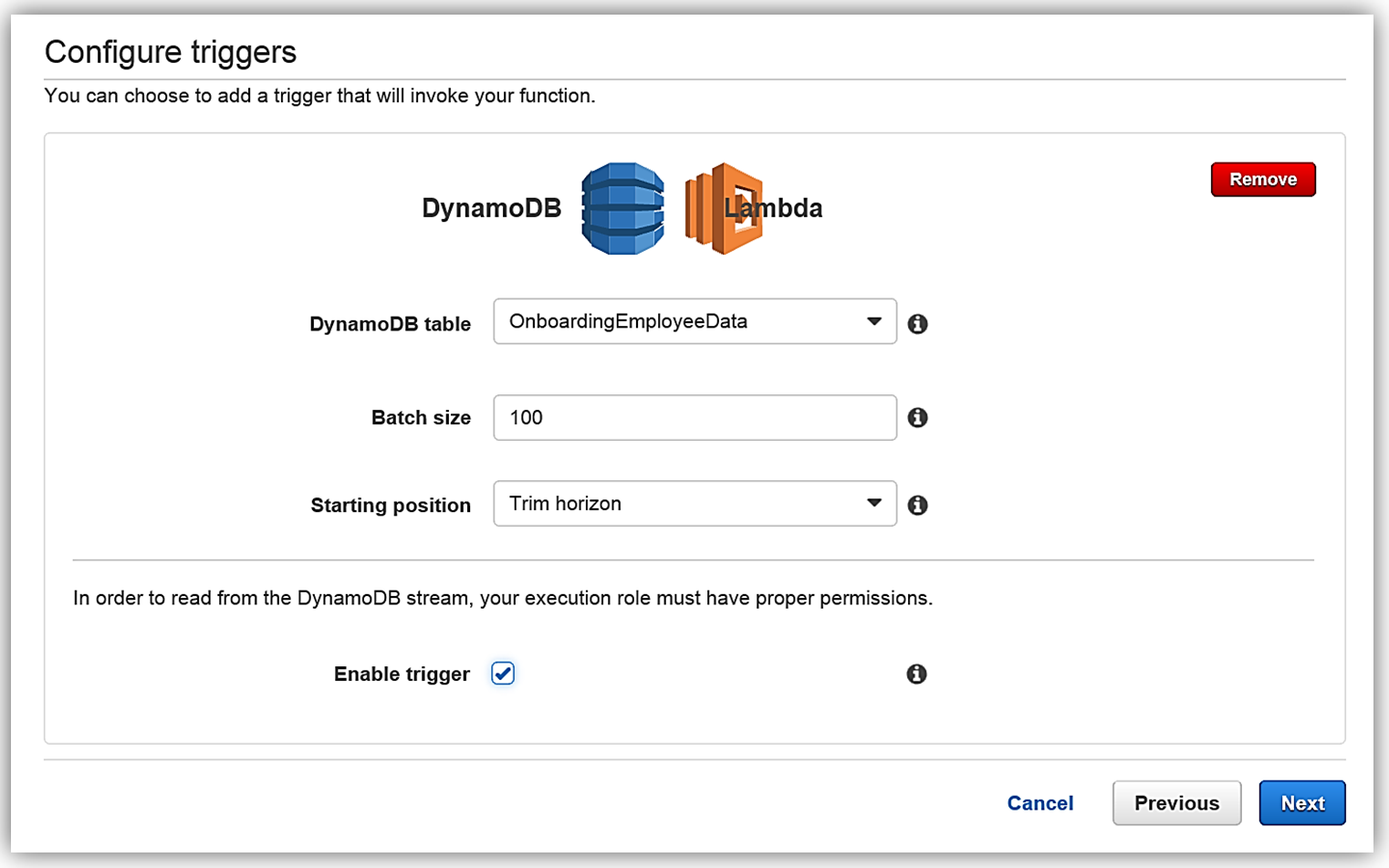
AWS Lambda: DynamoDB がトリガーする Lambda 関数 AWS Lambda は、アマゾン ウェブ サービスのサーバーレスコンピューティングサービスの中心となるものです。Lambda を使うと、サポートされた言語を使って、事実上あらゆる種類のアプリケーションやバックエンドサービスのコードを作成して実行できます。Lambda は、AWS のサービスまたは HTTP リクエストからのイベントに対応して、コードをトリガーします。Lambda はワークロードに基づいて動的にスケールします。コードの実行に対してのみ料金を支払います。DynamoDB ストリームが Lambda 関数をトリガーし、それによりインデックスが作成され、データが Elasticsearch に送信されます。もう 1 つの方法は、DynamoDB の Logstash プラグインを使用することです。ただし、Logstash プロセッサのいくつかは Elasticsearch 5.1 コアに組み込まれ、さらにパフォーマンスの最適化が向上されているため、今回は Lambda を使用して DynamoDB ストリームを処理し、Amazon Elasticsearch Service にデータをロードすることにします。では AWS Lambda コンソールを使って、Amazon Elasticsearch Service に従業員データをロードするための Lambda 関数を作成しましょう。コンソールでブランク関数設計図を選択して、新しい Lambda 関数を作成します。次に [Configure Trigger] ページに移ります。トリガーページで、Lambda をトリガーする AWS のサービスとして DynamoDB を選択し、トリガー関連オプションとして次のように入力します。
- テーブル: OnboardingEmployeeData
- バッチサイズ: 100 (デフォルト)
- 開始位置: 水平トリム
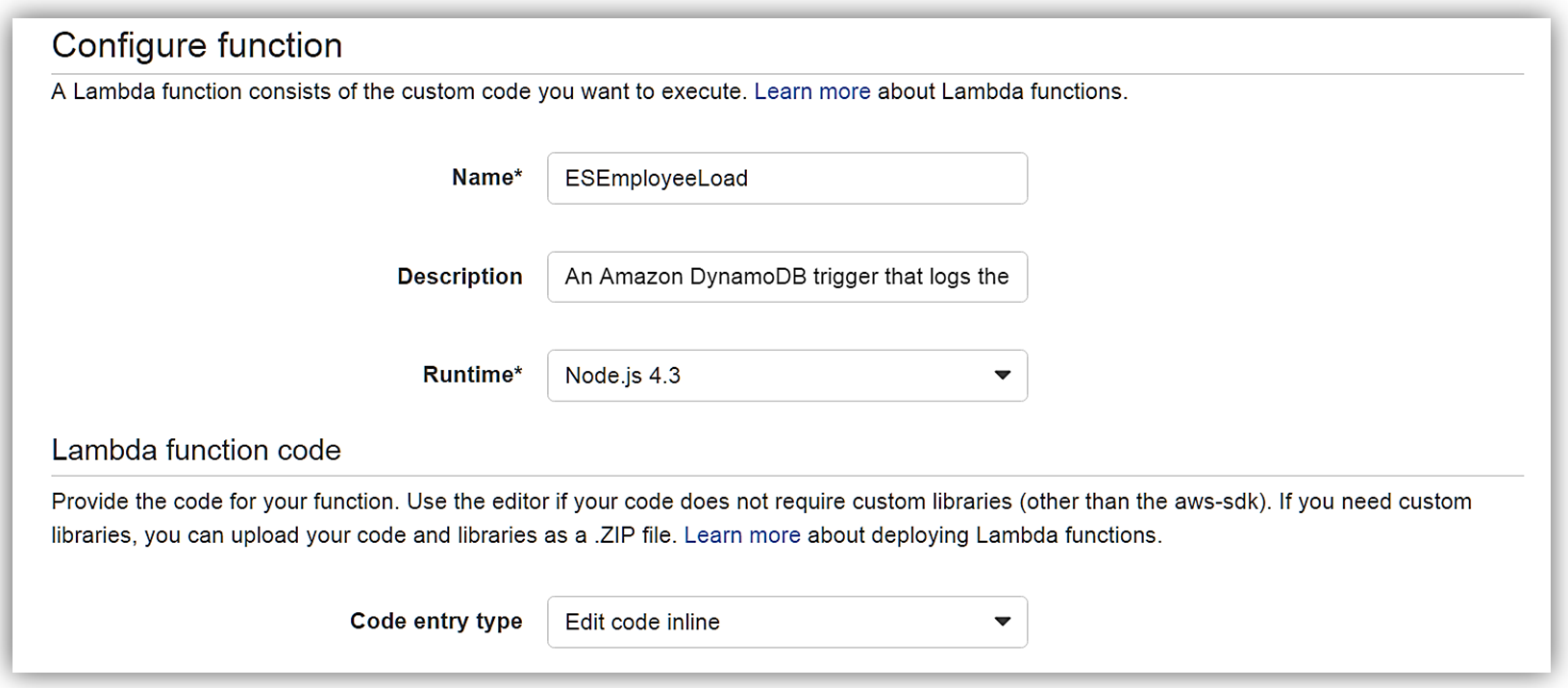
[Next] をクリックすると、関数の設定画面に移動します。関数の名前を ESEmployeeLoad とし、この関数を Node.4.3 で作成します。
Lambda 関数のコードは次のとおりです。
var AWS = require('aws-sdk');
var path = require('path');
//すべての ElasticSearch ドメイン情報のオブジェクト
var esDomain = {
region: process.env.RegionForES,
endpoint: process.env.EndpointForES,
index: process.env.IndexForES,
doctype: 'onboardingrecords'
};
//作成された ES ドメインエンドポイントからの AWS エンドポイント
var endpoint = new AWS.Endpoint(esDomain.endpoint);
//AWS 認証情報は環境から取得される
var creds = new AWS.EnvironmentCredentials('AWS');
console.log('Loading function');
exports.handler = (event, context, callback) => {
//console.log('Received event:', JSON.stringify(event, null, 2));
console.log(JSON.stringify(esDomain));
event.Records.forEach((record) => {
console.log(record.eventID);
console.log(record.eventName);
console.log('DynamoDB Record: %j', record.dynamodb);
var dbRecord = JSON.stringify(record.dynamodb);
postToES(dbRecord, context, callback);
});
};
function postToES(doc, context, lambdaCallback) {
var req = new AWS.HttpRequest(endpoint);
req.method = 'POST';
req.path = path.join('/', esDomain.index, esDomain.doctype);
req.region = esDomain.region;
req.headers['presigned-expires'] = false;
req.headers['Host'] = endpoint.host;
req.body = doc;
var signer = new AWS.Signers.V4(req , 'es'); // es: サービスコード
signer.addAuthorization(creds, new Date());
var send = new AWS.NodeHttpClient();
send.handleRequest(req, null, function(httpResp) {
var respBody = '';
httpResp.on('data', function (chunk) {
respBody += chunk;
});
httpResp.on('end', function (chunk) {
console.log('Response: ' + respBody);
lambdaCallback(null,'Lambda added document ' + doc);
});
}, function(err) {
console.log('Error: ' + err);
lambdaCallback('Lambda failed with error ' + err);
});
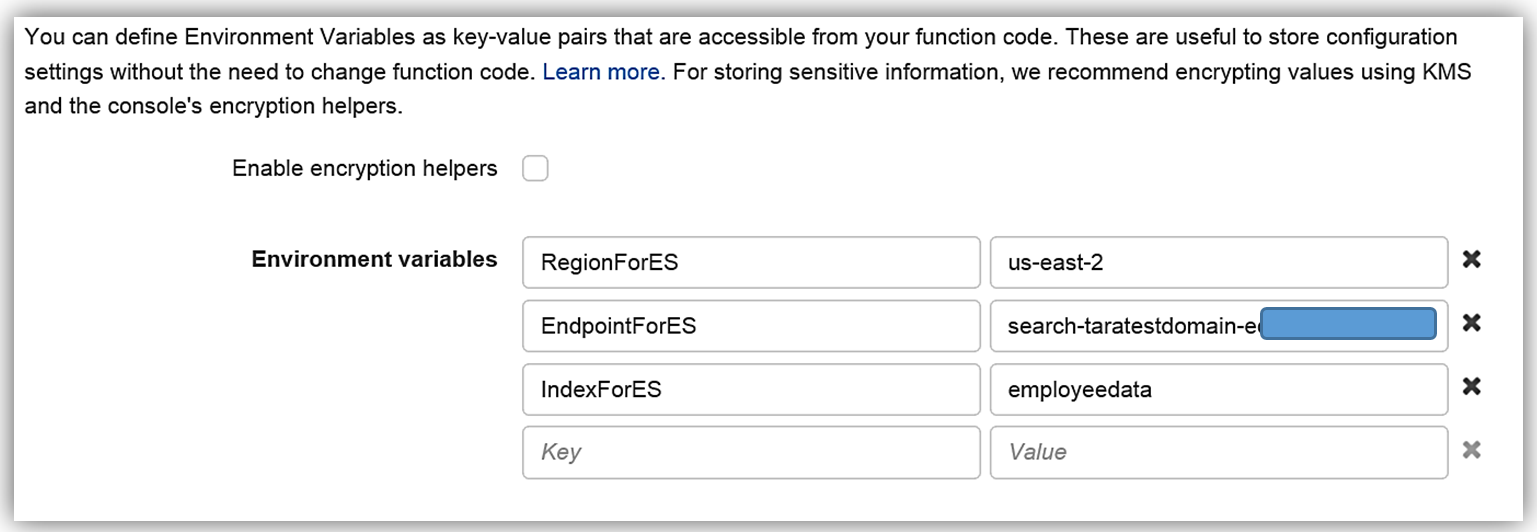
}Lambda 関数の環境変数は次のとおりです。
既存のロールのオプションで ESOnboardingSystem を選択します。これは先に作成した IAM ロールです。
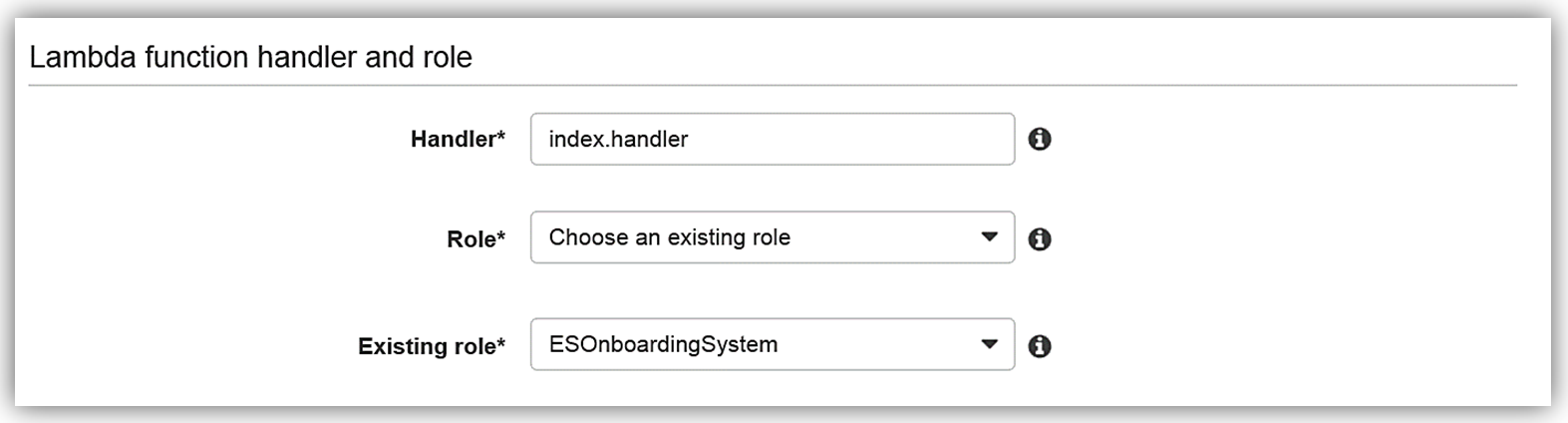
Lambda 関数のための IAM ロールのアクセス権限を完成したら、Lambda 関数の詳細を確認し、ESEmployeeLoad 関数の作成を完了します。
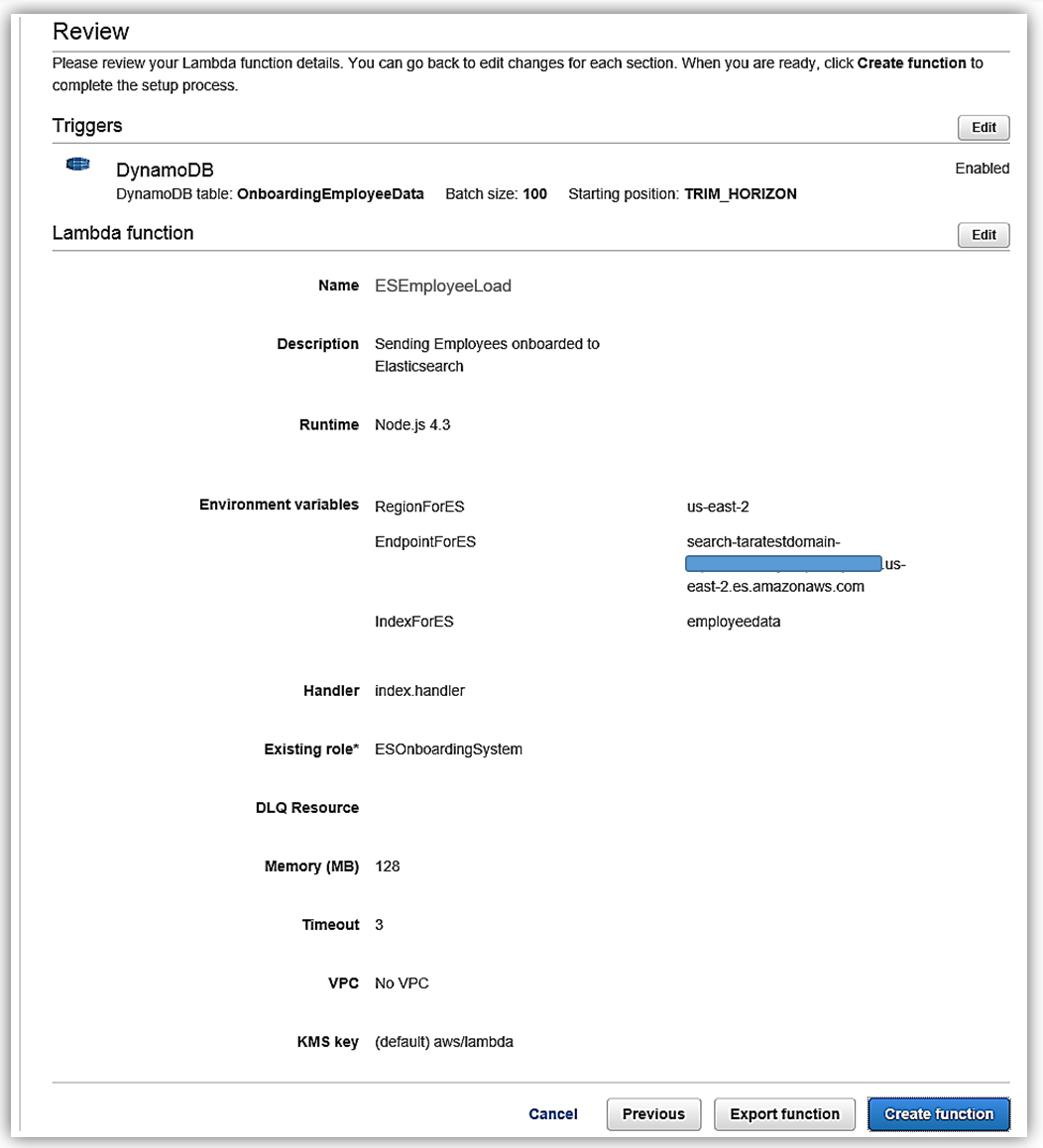
Elasticsearch との通信を行う Lambda 関数の構築プロセスは、これで完了です。では、データベースへのデータ変更のシミュレーションを行って、関数のテストを行いましょう。
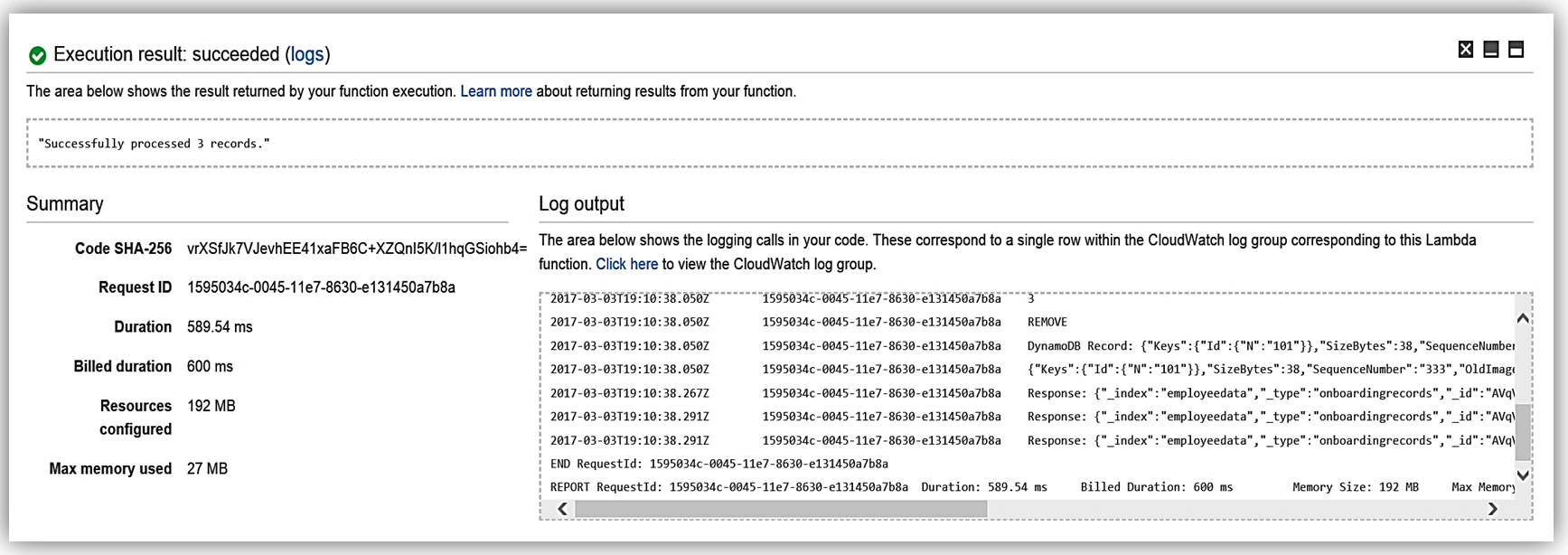
関数 ESEmployeeLoad は、オンボーディングシステムのデータベースでのデータの変更により実行されます。また、CloudWatch ログを確認することにより、Lambda 関数の Elasticsearch への処理を確認できます。さらに Lambda 関数を変更して新機能を利用したり、直接 Elasticsearch を使って新しい取り込みモードを利用することもできます。たとえば、従業員レコードドキュメントのパイプラインを実装することができます。

この関数を複製して、従業員レコードに合わせてバッジを更新する処理や、従業員データに対するその他のプリプロセッサを活用したりすることができます。たとえば、Elasticsearch ドキュメントのデータパラメーターに基づいてデータを検索する場合、検索 API を使用してデータセットからレコードを取得できます。


可能性は無限です。データのニーズに応じて創造性を発揮しながら、優れたパフォーマンスを確保できます。Amazon Elasticsearch Service: Kibana 5.1 Elasticsearch 5.1 を使用しているすべての Amazon Elasticsearch Service ドメインでは、オープンソースの可視化ツールの最新バージョンである Kibana 5.1 が備えられています。可視化と分析のための補完プラットフォームである Kibana も、Kibana 5.1 リリースで機能強化されました。Kibana を活用すると、さまざまなグラフ、テーブル、マップを使用して、Elasticsearch データの表示、検索、操作を行うことができます。さらに、Kibana は大量データの高度なデータ分析を実行できます。Kibana リリースの主な機能強化は次のとおりです。
- 可視化ツールの新しいデザイン: カラースキームの更新と表示画面活用の最大化
- Timelion: 時間ベースのクエリ DSL による可視化ツール
- コンソール: 従来 Sense と呼ばれていた機能がコア機能の一部となりました。以前と同様の設定を使って、Elasticsearch へのフリーフォームのリクエストを行うことができます
- フィールドスクリプト言語: Elasticsearch クラスターで新しいスクリプト言語 Painless を使うことが可能
- タグクラウドの可視化: 5.1 では、データの重要度による単語ベースのグラフィカルビューが追加されました
- グラフの拡張: 前回削除されたグラフが復活し、さらに X-Pack の高度なビューが追加されました
- Profiler の UI: ツリービューによる Profile API の拡張を提供
- レンダリングパフォーマンスの向上: パフォーマンスを向上させ、CPU 負荷を低減
まとめ ご覧いただいたように、このリリースでは Elasticsearch ソリューションの構築に役立つ、広範な機能強化や新機能を備えています。Amazon Elasticsearch Service では新たに、15 個の Elasticsearch API と 6 つのプラグインをサポートします。Amazon Elasticsearch Service は Elasticsearch 5.1 の次のオペレーションをサポートします。

Elasticsearch でサポートされるオペレーションの詳細については、「Amazon Elasticsearch 開発者ガイド」を参照してください。また Amazon Elasticsearch Service のウェブサイトを活用したり、AWS マネジメントコンソールにサインインして開始することもできます。- Tara