Amazon Redshift 横串検索では、Amazon Redshift の分析機能を使用して、Amazon Aurora PostgreSQL および Amazon RDS for PostgreSQL データベースに保存されているデータを直接クエリできます。横串検索を試すことができる環境のセットアップの詳細については、「AWS CloudFormation で Amazon Redshift 横串検索の採用を加速する」を参照してください。
横串検索では、リアルタイムのデータ統合と簡素化された ETL 処理を行えます。Amazon Redshift でライブデータソースを直接接続して、リアルタイムのレポート作成と分析を行えるようになりました。以前は、PostgreSQL データベースから Amazon Simple Storage Service (Amazon S3) にデータを抽出し、COPY を使用して Amazon Redshift にロードするか、Amazon Redshift Spectrum を使用して Amazon S3 からクエリを実行する必要がありました。横串検索の利点の詳細については、「Amazon Redshift 横串検索を使用して、簡略化された ETL およびライブデータクエリソリューションを構築する」を参照してください。
この記事では、統合データセットが大きい場合、横串検索が大量のデータを取得する場合、または多くの Redshift ユーザーが統合データセットにアクセスしている場合に、横串検索のメリットを最大化するための 10 のベストプラクティスをご紹介します。これらの手法は、横串検索を一般的に使用する際には必要ありません。これらは、この興奮を覚えるような機能を最大限活用したい上級ユーザーを対象としています。
ベストプラクティスは 2 つのセクションに分かれています。1 つ目は Amazon Redshift クラスターに適用されるアドバイス、2 つ目は Aurora PostgreSQL および Amazon RDS for PostgreSQL 環境に適用されるアドバイスです。
この記事で示すサンプルコードは、CloudDataWarehouseBenchmark GitHub リポジトリ (TPC-H および TPC-DS に基づく) のデータとクエリを基にしています。
Amazon Redshift に適用されるベストプラクティス
横串検索を使用して Aurora インスタンスまたは Amazon RDS for PostgreSQL インスタンスにアクセスする場合、次のベストプラクティスを Amazon Redshift クラスターに適用できます。
1.ユースケースごとに個別の外部スキーマを使用する
個別のリモート PostgreSQL ユーザーを使用して、特定の Amazon Redshift ユースケースごとに個別の Amazon Redshift 外部スキーマを作成することをご検討ください。この方法により、外部データベースにアクセスできるユーザーとグループをより細かく制御できます。たとえば、広範なアクセス権限と別のスキーマを持つ関連する PostgreSQL ユーザーと、特定のリソースにアクセスが制限される中でアドホックレポートと分析を行う PostgreSQL ユーザーがいる中で、ETL の使用に外部スキーマが必要になることがあります。
次のサンプルコードでは、ETL とアドホックレポートで使用する 2 つの外部スキーマを作成します。各スキーマは、PostgreSQL データベース内の個別のユーザーの認証情報を含む異なる SECRET_ARN を使用します。
-- ETL usage - broad access
CREATE EXTERNAL SCHEMA IF NOT EXISTS apg_etl
FROM POSTGRES DATABASE 'tpch' SCHEMA 'public'
URI 'aurora-postgres-ro.cr7d8lhiupkf.us-west-2.rds.amazonaws.com' PORT 8192
IAM_ROLE 'arn:aws:iam::123456789012:role/apg-federation-role'
SECRET_ARN 'arn:aws:secretsmanager:us-west-2:123456789012:secret:apg-redshift-etl-secret-187Asd'
;
-- Ad-Hoc usage - limited access
CREATE EXTERNAL SCHEMA IF NOT EXISTS apg_adhoc
FROM POSTGRES DATABASE 'tpch' SCHEMA 'public'
URI 'aurora-postgres-ro.cr7d8lhiupkf.us-west-2.rds.amazonaws.com' PORT 8192
IAM_ROLE 'arn:aws:iam::123456789012:role/apg-federation-role'
SECRET_ARN 'arn:aws:secretsmanager:us-west-2:123456789012:secret:apg-redshift-adhoc-secret-187Asd'
;
2.クエリタイムアウトを使用して総ランタイムを制限する
外部スキーマにアクセスできるユーザーまたはグループにタイムアウトを設定することをご検討ください。ユーザークエリは、外部関係から非常に多くの行を意図せずに取得しようとし、長時間実行し続け、Amazon Redshift と PostgreSQL の両方でオープンリソースを保持することになる可能性があります。
ユーザーのクエリの合計実行時間を制限するために、すべてのユーザーのクエリに対して statement_timeout を設定できます。次のサンプルコードは、ETL ユーザーに 2 時間のタイムアウトを設定します。
-- Set ETL user timeout to 2 hours
ALTER USER etl_user SET statement_timeout TO 7200000;
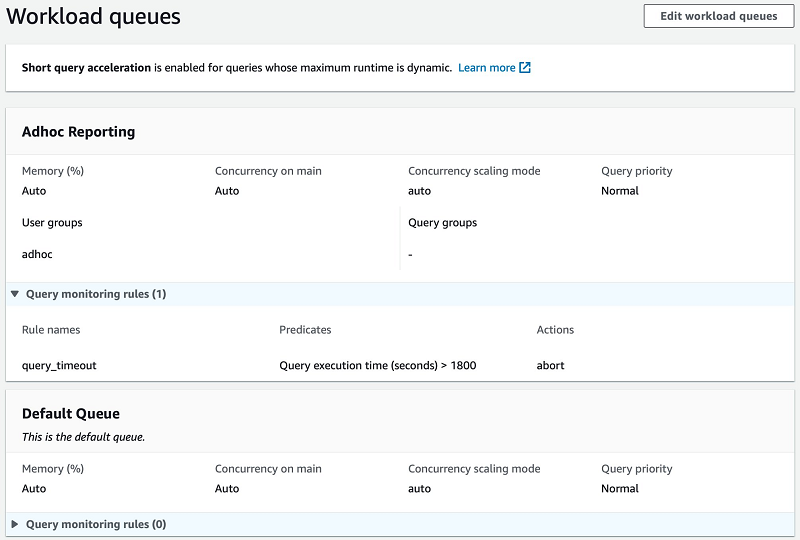
多くのユーザーが外部スキーマにアクセスできる場合、個々のユーザーごとに statement_timeout を定義するのは現実的でない場合があります。代わりに、query_execution_time メトリクスを使用して、WLM 設定でクエリ監視ルールを追加できます。次のスクリーンショットは、adhoc グループのユーザー用の Adhoc Reporting キューを備えた自動 WLM 設定と、1,800 秒 (30 分) を超えて実行されるクエリをキャンセルするルールを示しています。
3.Amazon Redshift クエリプランが効率的であることを確認する
横串検索の全体的なクエリプランとクエリメトリクスを確認して、Amazon Redshift が効率的に処理することを確認します。クエリプランの詳細については、「クエリプランの評価」を参照してください。
Amazon Redshift クエリ説明プランを確認する
SQL に EXPLAIN のプレフィックスを付けて SQL クライアントで実行することにより、クエリのプランを取得できます。次のサンプルコードは、サンプルクエリの explain 出力です。
<< REDSHIFT >> QUERY PLAN
-------------------------------------------------------------------------------------------------------------
XN Aggregate (cost=6396670427721.37..6396670427721.37 rows=1 width=32)
-> XN Hash Join DS_BCAST_INNER (cost=499986.50..6396670410690.30 rows=6812425 width=32)
Hash Cond: ("outer".l_partkey = ("inner".p_partkey)::bigint)
-> XN Seq Scan on lineitem (cost=0.00..2997629.29 rows=199841953 width=40)
Filter: ((l_shipdate < '1994-03-01'::date) AND (l_shipdate >= '1994-02-01'::date))
-> XN Hash (cost=449987.85..449987.85 rows=19999460 width=4)
-> XN PG Query Scan part (cost=0.00..449987.85 rows=19999460 width=4)
-> Remote PG Seq Scan apg_tpch_100g.part (cost=0.00..249993.25 rows=19999460 width=4)
Filter: ((p_type)::text ~~ 'PROMO%'::text)
演算子 XN PG Query Scan は、Amazon Redshift がクエリのこの部分について、統合 PostgreSQL データベースに対してクエリを実行することを示しています。これを、この記事では「サブ横串検索」と呼びます。クエリが複数の統合データソースを使用する場合、Amazon Redshift は各ソースに対してサブ横串検索を実行します。Amazon Redshift は、クラスター内のランダムに選択されたノードからサブ横串検索をそれぞれ実行します。
XN PG Query Scan 行の下に、Remote PG Seq Scan に続いて、Filter: 要素を含む行が表示されます。これらの 2 行は、Amazon Redshift が外部データにアクセスする方法と、サブ横串検索で使用する述語を定義しています。統合テーブル apg_tpch.part に対してサブ横串検索が実行されていることがわかります。
rows = 19999460 から、Amazon Redshift はクエリが PostgreSQL から最大 2000 万行を返すことができると見積もっていることもわかります。PostgreSQL にテーブルに関する統計情報を要求することで、この見積もりを作成します。
結合
各サブ横串検索はクラスター内の単一のノードから実行されるため、Amazon Redshift は結合分散戦略を選択して、サブ横串検索から返された行を残りのクラスターに送信して、クエリの結合を完了する必要があります。ブロードキャストまたは分散戦略の選択は、説明プランに示されています。DS_BCAST で始まる演算子は、データの完全なコピーをすべてのノードにブロードキャストします。DS_DIST で始まる演算子は、データの一部をクラスター内の各ノードに分散させます。
通常、小さな結果をブロードキャストし、大きな結果を分散させるのが最も効率的です。サブ横串検索が返す行数を適切に見積もると、プランナーは正しい結合分散戦略を選択します。ただし、プランナーの見積もりが正確ではない場合、大きすぎる結果をブロードキャストすることを選択することがあります。これにより、クエリの速度が低下する可能性があります。
結合の順序
結合では、小さい方の結果を内部関係として使用する必要があります。クエリが 2 つのテーブル (または 2 つのサブ横串検索) を結合する場合、Amazon Redshift は結合を実行する最適な方法を選択する必要があります。クエリプランナーは、クエリで宣言された順序で結合を実行しない場合があります。代わりに、結合される関係について持っている情報を使用して、さまざまな潜在的なプランの見積もりを作成します。予測されるコストが最も低いプラン (結合の順序を含む) を使用します。
最も一般的な結合であるハッシュ結合を使用すると、Amazon Redshift は内部テーブル (または結果) からハッシュテーブルを作成し、それを外部テーブルのすべての行と比較します。ハッシュテーブルがメモリに収まるように、最小の結果を内部データとして使用するのがよいでしょう。プランナーの見積もりがクエリの各ステップの結果の実際のサイズを反映していない場合、選択した順序で結合することは最適ではない可能性があります。
クエリ効率の向上
以下は、効率を改善するための高レベルのアドバイスです。詳細については、「クエリプランの分析」を参照してください。
- クエリの個別の部分のプランを調べます。クエリに複数の結合があるか、サブクエリを使用している場合は、各結合またはサブクエリの説明プランを確認して、クエリを簡素化することでメリットがあるかどうかを確認できます。たとえば、複数の結合を使用する場合、1 つの結合のみを使用する単純なクエリのプランを調べて、Amazon Redshift が独自にどのように結合を計画するかを確認できます。
- 外部結合の順序を調べ、内部結合を使用します。プランナーはどのような場合も外部結合を並べ替えることはできません。外部結合を内部結合に変換できる場合は、プランナーがより効率的な計画を使用できるようになります。
- 結合中最大の Amazon Redshift テーブルの分散キーを参照します。結合が分散キーを参照する場合、Amazon Redshift はクラスター全体で Redshift テーブルから行を移動することなく、各ノードで並列的に結合を完了できます。
- サブ横串検索の結果をテーブルに挿入します。Amazon Redshift は、データがローカルの一時テーブルまたは永続テーブルからのものである場合に最適な統計を示します。まれに、統合データを一時テーブルに最初に格納し、それを Amazon Redshift データと結合することが最も効率的な場合もあります。
4.述語がリモートクエリにプッシュダウンされていることを確認する
Amazon Redshift のクエリオプティマイザーは、PostgreSQL で実行されるサブ横串検索に述語条件をプッシュするのに非常に効果的です。重要または長時間実行される横串検索のクエリプランを確認して、Amazon Redshift が該当するすべての述語を各サブクエリに適用していることを確認します。
述語が CASE ステートメント内にあり、統合関係が CTE サブクエリ内にある次のサンプルクエリをご検討ください。
WITH cte
AS (SELECT p_type, l_extendedprice, l_discount, l_quantity
FROM public.lineitem
JOIN apg_tpch.part --<< PostgreSQL table
ON l_partkey = p_partkey
WHERE l_shipdate >= DATE '1994-02-01'
AND l_shipdate < (DATE '1994-02-01' + INTERVAL '1 month')
)
SELECT CASE WHEN p_type LIKE 'PROMO%' --<< PostgreSQL filter predicate pt1
THEN TRUE ELSE FALSE END AS is_promo
, AVG( ( l_extendedprice * l_discount) / l_quantity ) AS avg_promo_disc_val
FROM cte
WHERE is_promo IS TRUE --<< PostgreSQL filter predicate pt2
GROUP BY 1;
Amazon Redshift は、フィルターをリモート関係にプッシュすることで、サブ横串検索を効果的に最適化できます。次のプランをご覧ください。
<< REDSHIFT >> QUERY PLAN
-------------------------------------------------------------------------------------------------------------------
XN HashAggregate (cost=17596843176454.83..17596843176456.83 rows=200 width=87)
-> XN Hash Join DS_BCAST_INNER (cost=500000.00..17596843142391.79 rows=6812609 width=87)
Hash Cond: ("outer".l_partkey = ("inner".p_partkey)::bigint)
-> XN Seq Scan on lineitem (cost=0.00..2997629.29 rows=199841953 width=40)
Filter: ((l_shipdate < '1994-03-01'::date) AND (l_shipdate >= '1994-02-01'::date))
-> XN Hash (cost=450000.00..450000.00 rows=20000000 width=59)-- Federated subquery >>
-> XN PG Query Scan part (cost=0.00..450000.00 rows=20000000 width=59)
-> Remote PG Seq Scan apg_tpch.part (cost=0.00..250000.00 rows=20000000 width=59)
Filter: (CASE WHEN ((p_type)::text ~~ 'PROMO%'::text) THEN true ELSE false END IS TRUE)-- << Federated subquery
Redshift が必要に応じて述語をプッシュダウンできない場合、またはクエリが依然として大量のデータを返す場合、マテリアライズドビューと同期テーブルに関する次の 2 つのセクションのアドバイスの採用をご検討ください。クエリを簡単に書き換えて効果的なフィルタープッシュダウンを実現するには、頻繁にクエリされるデータを永続化することに関する最後のベストプラクティスのアドバイスの採用をご検討ください。
5.マテリアライズドビューを使用して、頻繁にアクセスされるデータをキャッシュする
Amazon Redshift は、外部スキーマの統合テーブルを参照するマテリアライズドビューの作成をサポートするようになりました。
頻繁に実行されるクエリをキャッシュする
マテリアライズドビューを使用して、Amazon Redshift クラスターで頻繁に実行されるクエリをキャッシュすることをご検討ください。多くのユーザーが同じ横串検索を定期的に実行する場合、クエリのリモートコンテンツを実行ごとに再度取得する必要があります。マテリアライズドビューでは、リモートデータベースから同じデータを取得せずに、Amazon Redshift クラスターから結果を取得できます。次に、リモートデータの変更率と重要度に応じて、マテリアライズドビューの更新が特定の時間に行われるようにスケジュールを立てられます。
次のサンプルコードは、統合ソーステーブルを使用するクエリからのマテリアライズドビューの作成、クエリ、および更新を示しています。
-- Create the materialized view
CREATE MATERIALIZED VIEW mv_store_quantities_by_quarter AS
SELECT ss_store_sk
, d_quarter_name
, COUNT(ss_quantity) AS count_quantity
, AVG(ss_quantity) AS avg_quantity
FROM public.store_sales
JOIN apg_tpcds.date_dim --<< federated table
ON d_date_sk = ss_sold_date_sk
GROUP BY ss_store_sk
ORDER BY ss_store_sk
;
--Query the materialized view
SELECT *
FROM mv_store_quanties_by_quarter
WHERE d_quarter_name = '1998Q1'
;
--Refresh the materialized view
REFRESH MATERIALIZED VIEW mv_store_quanties_by_quarter
;
多くのクエリで使用されるキャッシュテーブル
マテリアライズドビューを使用して、多くのクエリで使用されるテーブルをローカルにキャッシュすることもご検討ください。多くの異なるクエリが同じ統合テーブルを使用する場合、その統合テーブル用のマテリアライズドビューを作成して、代わりに他のクエリで参照できるようにする方がよい場合がよくあります。
次のサンプルコードは、単一の統合ソーステーブルでマテリアライズドビューを作成してクエリを実行するところを示しています。
-- Create the materialized view
CREATE MATERIALIZED VIEW mv_apg_part AS
SELECT * FROM apg_tpch_100g.part
;
--Query the materialized view
SELECT SUM(l_extendedprice * (1 - l_discount)) AS discounted_price
FROM public.lineitem, mv_apg_part
WHERE l_partkey = p_partkey
AND l_shipdate BETWEEN '1997-03-01' AND '1997-04-01'
;
この記事の執筆時点では、別のマテリアライズドビュー内でマテリアライズドビューを参照することはできません。キャッシュされたテーブルを使用する他のビューは、通常のビューである必要があります。
キャッシュと更新時間および頻度のバランスをとる
マテリアライズドビューは、更新スケジュールに比べてすばやく実行されるクエリに使用するのが最適です。たとえば、1 時間ごとに更新されるマテリアライズドビューは数分で実行され、毎日更新されるマテリアライズドビューは 1 時間未満で実行される必要があります。これを書いている時点では、外部テーブルを参照するマテリアライズドビューは増分更新の対象ではありません。REFRESH MATERIALIZED VIEW を実行して結果全体を再作成すると、完全更新が発生します。
マテリアライズドビューを使用してリモートアクセスを制限する
また、マテリアライズドビューを使用して、リモートデータベースに対して直接クエリを発行できるユーザーの数を減らすこともご検討ください。外部スキーマへのアクセス権限をマテリアライズドビューを更新するユーザーにのみ付与し、他の Amazon Redshift ユーザーにはマテリアライズドビューへのアクセス権限のみを付与できます。
機密情報を含むリモートの本番データベースからクエリを実行する場合は、この方法でアクセスの範囲を制限することがデータセキュリティの一般的なベストプラクティスです。
6.大きなリモートテーブルをローカルコピーに同期する
リモートテーブルのコピーを永続的な Amazon Redshift テーブルに保持することをご検討ください。リモートテーブルが大きく、マテリアライズドビューの完全な更新に時間がかかる場合は、同期プロセスを使用してローカルコピーを更新し続ける方が効果的です。
新しく追加されたリモートデータを同期する
大きなリモートテーブルに新しい行のみが追加され、更新も削除もされていない場合、リモートテーブルからコピーに定期的に新しい行を挿入することで、Amazon Redshift コピーを同期できます。GitHub のサンプルストアドプロシージャ sp_sync_get_new_rows を使用して、この同期プロセスを自動化できます。
このサンプルストアドプロシージャでは、プライマリキーとしてソーステーブルに自動増分 ID 列が必要です。Amazon Redshift テーブルで現在の最大値を見つけ、より高い ID 値を持つ統合テーブルのすべての行を取得して、Amazon Redshift テーブルに挿入します。
次のサンプルコードは、統合ソーステーブルから Amazon Redshift ターゲットテーブルへの同期を示しています。まず、次のように、4 行のソーステーブルを PostgreSQL データベースに作成します。
CREATE TABLE public.pg_source (
pk_col BIGINT GENERATED ALWAYS AS IDENTITY PRIMARY KEY
, data_col VARCHAR(20));
INSERT INTO public.pg_tbl (data_col)
VALUES ('aardvark'),('aardvarks'),('aardwolf'),('aardwolves')
;
Amazon Redshift クラスターに 2 行のターゲットテーブルを作成します。
CREATE TABLE public.rs_target (
pk_col BIGINT PRIMARY KEY
, data_col VARCHAR(20));
INSERT INTO public.rs_tbl
VALUES (1,'aardvark'), (2,'aardvarks')
;
Amazon Redshift ストアドプロシージャを呼び出してテーブルを同期します。
CALL sp_sync_get_new_rows(SYSDATE,'apg_tpch.pg_source','public.rs_target','pk_col','public.sp_logs',0);
-- INFO: SUCCESS - 2 new rows inserted into `target_table`.
SELECT * FROM public.rs_tbl;
-- pk_col | data_col
-- --------+------------
-- 1 | aardvark
-- 2 | aardvarks
-- 4 | aardwolves
-- 3 | aardwolf
リモートデータの変更をマージする
リモートテーブルの行を更新または挿入した後、変更された行と新しい行を定期的にリモートテーブルからコピーにマージすることにより、Amazon Redshift コピーを同期できます。この方法は、変更がテーブルで明確にマークされている場合に上手くいきます。これにより、新しい行または変更された行だけを簡単に取得できます。GitHub のサンプルストアドプロシージャ sp_sync_merge_changes を使用して、この同期プロセスを自動化できます。
このストアドプロシージャの例では、各行が最後に変更された日時を示す日付/時刻列がソースに必要です。この列を使用して、同期する必要がある変更を見つけ、変更された行を Amazon Redshift コピーで更新するか、Amazon Redshift コピーに新しい行を挿入します。ストアドプロシージャでは、テーブルにプライマリキーが宣言されている必要もあります。プライマリキーを使用して、データのローカルコピーで更新する行を特定します。
次のサンプルコードは、統合ソーステーブルから Amazon Redshift ターゲットテーブルへ更新するところを示しています。最初に、Amazon Redshift クラスターに 2 行のサンプルテーブルを作成します。
CREATE TABLE public.rs_tbl (
pk_col INTEGER PRIMARY KEY
, data_col VARCHAR(20)
, last_mod TIMESTAMP);
INSERT INTO public.rs_tbl
VALUES (1,'aardvark', SYSDATE), (2,'aardvarks', SYSDATE);
SELECT * FROM public.rs_tbl;
-- pk_col | data_col | last_mod
-- --------+------------+---------------------
-- 1 | aardvark | 2020-04-01 18:01:02
-- 2 | aardvarks | 2020-04-01 18:01:02
次のように、PostgreSQL データベースに 4 行のソーステーブルを作成します。
CREATE TABLE public.pg_tbl (` `
pk_col INTEGER GENERATED ALWAYS AS IDENTITY PRIMARY KEY
, data_col VARCHAR(20)
, last_mod TIMESTAMP);
INSERT INTO public.pg_tbl (data_col, last_mod)
VALUES ('aardvark', NOW()),('aardvarks', NOW()),('aardwolf', NOW()),('aardwolves', NOW());
Amazon Redshift ストアドプロシージャを呼び出してテーブルを同期します。
CALL sp_sync_merge_changes(SYSDATE,'apg_tpch.pg_tbl','public.rs_tbl','last_mod','public.sp_logs',0);
-- INFO: SUCCESS - 4 rows synced.
SELECT * FROM public.rs_tbl;
-- pk_col | data_col | last_mod
-- --------+------------+---------------------
-- 1 | aardvark | 2020-04-01 18:09:56
-- 2 | aardvarks | 2020-04-01 18:09:56
-- 4 | aardwolves | 2020-04-01 18:09:56
-- 3 | aardwolf | 2020-04-01 18:09:56
Aurora または Amazon RDS に適用するベストプラクティス
次のベストプラクティスは、Aurora または Amazon RDS for PostgreSQL インスタンスを Amazon Redshift 横串検索で使用する場合に適用されます。
7.リードレプリカを使用して、Aurora または RDS への影響を最小限に抑える
Aurora と Amazon RDS では、PostgreSQL インスタンスの 1 つ以上のリードレプリカを設定できます。この記事の執筆時点では、横串検索では統合データベースへの書き込みが許可されていないため、外部スキーマのターゲットとして読み取り専用のエンドポイントを使用する必要があります。これにより、Amazon Redshift が発行するサブ横串検索によるマスターデータベースインスタンスへの影響が最小限に抑えられます。これにより、多くの場合、多数の小規模な書き込みトランザクションがすばやく実行されます。
リードレプリカの詳細については、「DB クラスターへの Aurora レプリカの追加」と「Amazon RDS での PostgreSQL リードレプリカの使用」を参照してください。
次のサンプルコードでは、読み取り専用のエンドポイントを使用して外部スキーマを作成します。エンドポイントの URI 設定で -ro の名前を確認できます。
--In Amazon Redshift:
CREATE EXTERNAL SCHEMA IF NOT EXISTS apg_etl
FROM POSTGRES DATABASE 'tpch' SCHEMA 'public'
URI 'aurora-postgres-ro.cr7d8lhiupkf.us-west-2.rds.amazonaws.com' PORT 8192
IAM_ROLE 'arn:aws:iam::123456789012:role/apg-federation-role'
SECRET_ARN 'arn:aws:secretsmanager:us-west-2:123456789012:secret:apg-redshift-etl-secret-187Asd';
8.ユースケースごとに特定の制限付き PostgreSQL ユーザーを使用する
個別の外部スキーマに関する最初のベストプラクティスで述べたように、横串検索のユースケースごとに個別の PostgreSQL ユーザーを作成することをご検討ください。複数のユーザーがいると、特定のユースケースごとに必要なアクセス許可のみを付与できます。ユーザーごとに、アクセス認証情報を含む異なる SECRET_ARN が必要です。これは、Amazon Redshift 外部スキーマが使用します。次のコードを参照してください。
-- Create an ETL user who will have broad access
CREATE USER redshift_etl WITH PASSWORD '<<example>>';
-- Create an Ad-Hoc user who will have limited access
CREATE USER redshift_adhoc WITH PASSWORD '<<example>>';
ユーザータイムアウトを適用してクエリの実行時間を制限する
PostgreSQL ユーザーに statement_timeout を設定することをご検討ください。ユーザークエリは、誤って何百万もの行を外部リレーションから取得しようとし、長時間実行し続け、Amazon Redshift と PostgreSQL の両方でオープンリソースを保持することになる可能性があります。これを防ぐには、予想される使用法に従って、ユーザーごとに異なるタイムアウト値を指定します。次のサンプルコードでは、ETL ユーザーとアドホックレポートユーザーにタイムアウトを設定します。
-- Set ETL user timeout to 1 hour
ALTER USER redshift_etl SET statement_timeout TO 3600000;
-- Set Ad-Hoc user timeout to 15 minutes
ALTER USER redshift_adhoc SET statement_timeout TO 900000;
9.PostgreSQL テーブルに正しくインデックスが作成されていることを確認する
Amazon Redshift の統合クエリが効率的に実行されるように、PostgreSQL インデックスを追加または変更することをご検討ください。Amazon Redshift は、リモートデータベースに対して通常の SQL クエリを使用して、PostgreSQL からデータを取得します。インデックスを使用する場合、特にクエリがテーブルの小さな部分を返す場合には、クエリはしばしばより高速です。
lineitem テーブルに対する Amazon Redshift 横串検索の次のサンプルコードをご検討ください。
SELECT AVG( ( l_extendedprice * l_discount) / l_quantity ) AS avg_disc_val
FROM apg_tpch.lineitem
WHERE l_shipdate >= DATE '1994-02-01'
AND l_shipdate < (DATE '1994-02-01' + INTERVAL '1 day');
Amazon Redshift はこれを次のサブ横串検索に書き換えて、PostgreSQL で実行します。
SELECT pg_catalog."numeric"(l_discount)
, pg_catalog."numeric"(l_extendedprice)
, pg_catalog."numeric"(l_quantity)
FROM public.lineitem
WHERE (l_shipdate < '1994-02-02'::date)
AND (l_shipdate >= '1994-02-01'::date);
インデックスがない場合、PostgreSQL から次のプランを取得します。
<< POSTGRESQL >> QUERY PLAN [No Index]
--------------------------------------------------------------------------------------------
Gather (cost=1000.00..16223550.40 rows=232856 width=17)
Workers Planned: 2
-> Parallel Seq Scan on lineitem (cost=0.00..16199264.80 rows=97023 width=17)
Filter: ((l_shipdate < '1994-02-02'::date) AND (l_shipdate >= '1994-02-01'::date))
次のインデックスを追加すると、このクエリに必要なデータを正確にカバーできます。
CREATE INDEX lineitem_ix_covering
ON public.lineitem (l_shipdate, l_extendedprice, l_discount, l_quantity);
新しいインデックスが用意できると、次のプランが表示されます。
<< POSTGRESQL >> QUERY PLAN [With Covering Index]
------------------------------------------------------------------------------------------------
Bitmap Heap Scan on lineitem (cost=7007.35..839080.74 rows=232856 width=17)
Recheck Cond: ((l_shipdate < '1994-02-02'::date) AND (l_shipdate >= '1994-02-01'::date))
-> Bitmap Index Scan on lineitem_ix_covering (cost=0.00..6949.13 rows=232856 width=0)
Index Cond: ((l_shipdate < '1994-02-02'::date) AND (l_shipdate >= '1994-02-01'::date))
改訂されたプランでは、最大コストは元の 16223550 に対して 839080 になります。これは、19 分の 1 のコストです。コストの削減は、インデックスを使用するとクエリが高速になることを示唆していますが、これを確認するにはテストが必要です。
インデックスは慎重に検討する必要があります。PostgreSQL にインデックスを追加することの詳細なトレードオフ、利用可能な特定の PostgreSQL インデックスタイプ、およびインデックスの使用方法については、この記事では扱いません。
10.制限的な結合をリモートビューに置き換える
多くの分析クエリは結合を使用して、クエリが返す行を制限できます。たとえば、calender_quarter='2019Q4' などの述語を date_dim テーブルに適用し、大きなファクトテーブルに結合することができます。date_dim のフィルターは、ファクトテーブルから返される行を 1 桁減らします。ただし、この記事の執筆時点では、Amazon Redshift はそのような結合制限を統合関係にプッシュできません。
2 つの統合テーブル間の結合を使用した次のサンプルクエリをご検討ください。
SELECT ss_store_sk
,COUNT(ss_quantity) AS count_quantity
,AVG(ss_quantity) AS avg_quantity
FROM apg_tpcds.store_sales
JOIN apg_tpcds.date_dim
ON d_date_sk = ss_sold_date_sk
WHERE d_quarter_name = '1998Q1'
GROUP BY ss_store_sk
ORDER BY ss_store_sk
LIMIT 100;
Amazon Redshift でこのクエリを EXPLAIN すると、次のプランが表示されます。
<< REDSHIFT >> QUERY PLAN [Original]
----------------------------------------------------------------------------------------------------------------------------------
<< snip >>
-> XN PG Query Scan store_sales (cost=0.00..576019.84 rows=28800992 width=12)
-> Remote PG Seq Scan store_sales (cost=0.00..288009.92 rows=28800992 width=12)
-> XN Hash (cost=1643.60..1643.60 rows=73049 width=4)
-> XN PG Query Scan date_dim (cost=0.00..1643.60 rows=73049 width=4)
-> Remote PG Seq Scan date_dim (cost=0.00..913.11 rows=73049 width=4)
Filter: (d_quarter_name = '1998Q1'::bpchar)
クエリプランは、date_dim がフィルタリングされていることを示していますが、store_sales にはフィルターがありません。つまり、Amazon Redshift は store_sales からすべての行を取得してから、結合を使用して行をフィルタリングします。store_sales は非常に大きなテーブルであるため、このクエリを定期的に実行する場合は特に、この操作に時間がかかりすぎる可能性があります。
解決策として、この結合をカプセル化する次のビューを PostgreSQL で作成できます。
CREATE VIEW vw_store_sales_quarter
AS SELECT ss.*, dd.d_quarter_name ss_quarter_name
FROM store_sales ss
JOIN date_dim dd
ON ss.ss_sold_date_sk = dd.d_date_sk;
次のように、このビューを使用するように Amazon Redshift クエリを書き換えます。
SELECT ss_store_sk
,COUNT(ss_quantity) AS count_quantity
,AVG(ss_quantity) AS avg_quantity
FROM apg_tpcds_10g.vw_store_sales_date
WHERE ss_quarter_name = '1998Q1'
GROUP BY ss_store_sk
ORDER BY ss_store_sk
LIMIT 100;
Amazon Redshift でこの書き換えられたクエリを EXPLAIN すると、次のプランが表示されます。
<< REDSHIFT >> QUERY PLAN [Remote View]
----------------------------------------------------------------------------------------------------------------------------------
<< snip >>
-> XN HashAggregate (cost=30.00..31.00 rows=200 width=8)
-> XN PG Query Scan vw_store_sales_date (cost=0.00..22.50 rows=1000 width=8)
-> Remote PG Seq Scan vw_store_sales_date (cost=0.00..12.50 rows=1000 width=8)
Filter: (ss_quarter_name = '1998Q1'::bpchar)
Amazon Redshift は、フィルターをビューにプッシュします。結合の制限は PostgreSQL に適用され、Amazon Redshift に返される行がはるかに少なくなります。Remote PG Seq Scan が rows=1000 を表示していることに気付くかもしれません。これは、PostgreSQL がテーブル統計を提供できない場合にクエリオプティマイザーが使用するデフォルト値です。
まとめ
この記事では、Amazon Redshift 横串検索のパフォーマンスを最大化するのに役立つ 10 のベストプラクティスをご紹介しました。ユースケースはそれぞれ異なるため、これらの推奨事項を特定の状況にどのように適用できるかを慎重に評価してください。
AWS は引き続き Amazon Redshift 横串検索を強化および改善し、お客様のフィードバックを歓迎します。質問や提案がある場合は、コメント欄にフィードバックをお寄せください。Amazon Redshift クラスターの最適化についてさらにサポートが必要な場合は、AWS アカウントチームにお問い合わせください。
この記事を執筆するにあたり、AWS の同僚である Sriram Krishnamurthy、Entong Shen、Niranjan Kamat、Vuk Ercegovac、および Ippokratis Pandis から支援とサポートを受けたことに感謝申し上げます。
著者について
 Joe Harris は、AWS のシニア Redshift データベースエンジニアで、Redshift のパフォーマンスに焦点を当てています。 彼は 20 年間にわたり、さまざまなプラットフォームでデータを分析し、データウェアハウスを構築してきました。AWS に入社する前は、2013 年の開始日から Redshift のお客様であり、Redshift フォーラムの最大の貢献者でした。
Joe Harris は、AWS のシニア Redshift データベースエンジニアで、Redshift のパフォーマンスに焦点を当てています。 彼は 20 年間にわたり、さまざまなプラットフォームでデータを分析し、データウェアハウスを構築してきました。AWS に入社する前は、2013 年の開始日から Redshift のお客様であり、Redshift フォーラムの最大の貢献者でした。