Amazon Web Services ブログ
Amazon SageMaker Ground Truth: データラベリングを高速化するための事前トレーニング済みモデルの使用
Amazon SageMaker Ground Truth を使用すると、機械学習用の高精度なトレーニングデータセットをすばやく構築することができます。SageMaker Ground Truth を使用すると、パブリックおよびプライベートでラベル付けを行う人間の作業者への簡単なアクセスと、一般的なラベル付けタスクのための組み込みのワークフローとインターフェースが提供されます。さらに、SageMaker Ground Truth は自動データラベル付けを使用してラベル付けのコストを最大 70% 削減します。自動データラベル付けは、人間がラベルを付けたデータから Ground Truth をトレーニングし、サービスが独自にデータにラベルを付けることを学習することによって機能します。以前のブログ記事では、自動化されたデータのラベル付けのしくみと、その結果の評価方法について説明しました。
SageMaker Ground Truth はラベリングジョブの間にお客様のためにモデルをトレーニングし、そしてラベリングジョブが終わった後にこれらのモデルを使用できるようになることはご存知でしたでしょうか? このブログ記事では、前のラベリングジョブからトレーニングされたモデルを使用して次のラベリングジョブを「スタートダッシュ」する方法について説明します。これは高度な機能で、SageMaker の Ground Truth API を通じてのみ利用できます。
| このブログ記事について | |
| 読む時間 | 30 分 |
| 完了するまでの時間 | 8 時間 |
| 完了するためのコスト | 600 USD 未満 |
| 学習レベル | 中級 (200) |
| AWS のサービス | Amazon SageMaker、Amazon SageMaker GroundTruth |
この記事は、以下の以前の記事を基にしているので、最初にその記事を確認することをお勧めします。
このブログの一部として、以下で説明するように、3 つの異なるラベリングジョブを作成します。
- 「自動ラベリング」機能を有効にした初期ラベリングジョブ。このラベリングジョブの最後に、サンプルデータセットに対して高い精度の予測を行うことができるトレーニング済みの機械学習モデルを準備します。
- 最初のラベリングジョブと同じデータセットから描画された異なる画像セットを使用した後続のラベリングジョブ。このラベリングジョブでは、最初のラベリングジョブの出力として作成された機械学習モデルを、ラベリングプロセスを加速するために指定します。
- 2 回目のラベリングジョブの繰り返し。ただし、事前トレーニング済みの機械学習モデルは使用しません。事前にトレーニングされたモデルを使用することの利点を実証するために、このラベリングジョブを試金石として使います。
ここでは、API を使ってデータセットの境界ボックスラベルを作成する Amazon SageMaker Jupyter ノートブックを使用します。
デモノートブックにアクセスするには、ml.m4.xlarge インスタンスタイプを使用して Amazon SageMaker ノートブックインスタンスを開始します。インスタンスは、このステップバイステップチュートリアルに従ってセットアップできます。ステップ 3 では、IAM ロールの作成時に「任意の S3 バケット」にチェックを入れるようにしてください。 Jupyter ノートブックを開いて [SageMaker Examples] タブを選択し、object_detection_pretrained_model.ipynb を起動します。
データセットを準備する
ラベリングジョブを作成するために使用するデータセットを準備しましょう。このデータセットから 1250 枚の画像を 2 セット作成します。最初のラベリングジョブには最初のバッチを使用し、その後の 2 つのジョブ (1 つは事前トレーニング済みモデルを使用したジョブ、もう 1 つはそれを使用しないジョブ) にはもう 1 つのバッチを使用します。
次に、デモノートブックの「データセットの準備」の下にあるすべてのセルを実行します。これらのセルを実行すると、次の手順を行います。
- データセットリポジトリから 2500 枚の画像の完全なコレクションを取得します。
- データセットをそれぞれ 1250 枚の画像の 2 つのバッチに分割します。
アクティブラーニングを使用して初期ラベリングジョブを作成する
それでは、最初のジョブを実行しましょう。ノートブックの「反復 #1: 最初のラベリングジョブの作成」の見出しの下にあるすべてのセルを実行します。セルには変更が必要なものもあるため、ノートブックの指示を注意深く読んでください。これらのセクションを実行すると、次の手順を行います。
- 最初のラベリングジョブで使用するために、前のステップの 1250 枚の最初のセットを準備します。
- オブジェクト検出ラベリングジョブのラベリング指示を作成します。
- オブジェクト検出ラベリングジョブリクエストを作成します。
- ラベリングリクエストを SageMaker Ground Truth に送信します。
ジョブは約 4 時間かかるはずです。完了したら、「初期のアクティブラーニングラベリングジョブの結果の分析」セクションにあるすべてのセルを実行します。これらのセクションでは、自分が行ったラベリングジョブを理解するのに役立つ豊富な情報が得られます。特に、合計コストは 217.18 USD で、そのうちの 78%がパブリックワークチームによる手動ラベリングのコストによるものであることがわかります。自動ラベリングを使用しているため、この段階でもある程度のコストが削減されていることは特筆に値します。自動ラベリングがなければ、ラベリングコストは 235 USD になっていたでしょう。一般的に、(何千ものオブジェクトを注文する) より大きなデータセットでは自動ラベリングをさらに活かすことができます。このブログの残りの部分では、事前トレーニング済みモデルを使用して、この小さな 1,250 オブジェクトのデータセットでも自動ラベリングのパフォーマンスを向上させることを目指します。
前回のブログ記事「Amazon SageMaker Ground Truth と自動化されたデータのラベル付けによる低コストでのデータのアノテーション」では、ラベリングジョブのバッチ的な性質について説明しました。このブログ記事でも、ラベリングジョブのバッチごとの統計を参照しています。以下のプロットは、モデルが 4 回目の反復まで画像の自動ラベリングを開始しなかったことを示しています。 結局、ML モデルはデータセット全体のほぼ半分に注釈を付けることができました。次のステップでは、事前トレーニング済みモデルを使用することで機械でラベル付けされたデータの割合を増やし、その結果全体的なコストを削減できるかを見ます。
次のステップに進む前に、「ジョブの完了を待つ」というタイトルのセルが「完了」のジョブステータスを返すことを確認してください。
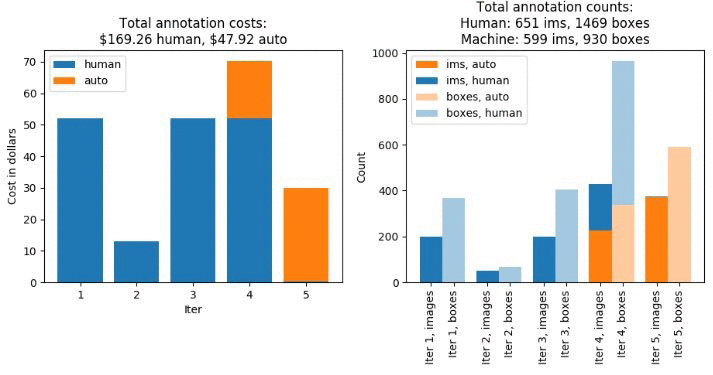
図 1。初期ラベリングジョブのラベリングコストとメトリクス。
事前トレーニング済みモデルを使用して 2 番目のラベリングジョブを作成する
最初のラベリングジョブが完了したので、次に 2 番目のラベリングジョブを準備します。元のラベリングジョブリクエストの多くを再利用しますが、事前にトレーニングされた機械学習モデルを指定する必要があります。最初のジョブの中でトレーニングされた最終的な機械学習モデルの Amazon ARN を取得するために、元のラベリングジョブをクエリできます。
ラベリングジョブリクエストの InitialActiveLearningModelArn パラメータにこれを使用します。
デモノートブックで、「反復 #2: 事前トレーニング済みモデルを使ったラベリングジョブ」の見出しの下にあるすべてのセルを実行します。これらのセクションを実行すると、次の手順を行います。
- 前のラベリングジョブでトレーニングされたモデルが指定されているオブジェクト検出ラベリングジョブリクエストを作成します。
- ラベリングジョブのリクエストを Ground Truth に送信します。
ジョブは約 4 時間かかるはずです。完了したら、「事前トレーニング済みモデルの結果を使用したアクティブラーニングラベリングジョブの分析」セクションのすべてのセルを実行します。これにより、前のラベリングジョブの後に見たものと同様の豊富な情報が得られます。機械でラベル付けされたデータセットオブジェクトの数に、いくつか重要な違いがあることにもうお気づきでしょう。 特に、機械学習モデルは 3 回目の反復でデータのラベル付けを開始できます。開始すると、データセットの残りのほぼ全体に注釈を付けます。 手動でラベル付けすることに関連するコストが以前よりはるかに低くなっていることに注目してください。自動ラベル付けに関連するコストは増加していますが、この増加は手動ラベル付けのコストが減少したのに比べると小規模です。その結果、このラベリングジョブの総コスト (146.80 USD) は、最初のラベリングジョブよりも 33%低くなります。
次のステップに進む前に、「ジョブの完了を待つ」というタイトルのセルが「完了」のジョブステータスを返すことを確認してください。
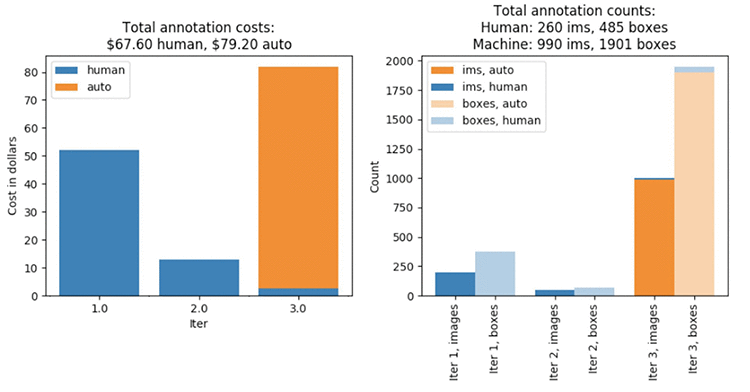
図 2。事前にトレーニングされたモデルを使用した、2 番目のラベリングジョブのラベリングコストとメトリクス。
事前トレーニング済みモデルなしで 2 番目のラベリングジョブを繰り返す
前のラベリングジョブでは、最初のデータセットと比べて、機械でラベル付けしたデータセットオブジェクトの実行時間と数が大幅に改善されたことを見ました。けれども、どれだけの違いが基礎となるデータの違いによるものかと自然と疑問に思うことでしょう。両方のデータセットは同じラベルを持ち、同じより大きなデータセットからサンプリングされていますが、比較試験ではより公平な評価が得られるでしょう。そのために、2 つ目のラベリングジョブをすべて同じ設定で繰り返しますが、事前トレーニング済みモデルは削除します。デモノートブックでは、「事前トレーニング済みモデルなしのラベリングジョブ」のすべてのセルを実行します。これらのセクションを実行すると、次の手順を行います。
- 2 番目のラベリングジョブからのラベリングジョブリクエストを、事前トレーニング済みモデルの削除と重ねて行います。
- ラベリングジョブリクエストを Ground Truth に送信します
ジョブは約 4 時間かかるはずです。完了したら、「反復 #3: 事前トレーニング済みモデルなしの 2 番目のデータサブセット」の見出しの下にあるすべてのセルを実行します。これにより前のステップで生成されたものに似たプロットが再度作成されます。けれども、これらの数値は、2 番目のラベリングジョブよりも最初のラベリングジョブの結果により近くなるはずです。全体的なコストは 189.64 USD で、ジョブが完了するまでに 5 回の反復が必要だったことに注目してください。これは、このデータのラベル付けに役立つように事前トレーニング済みモデルを使用した場合と比べて 29%高くなっています。
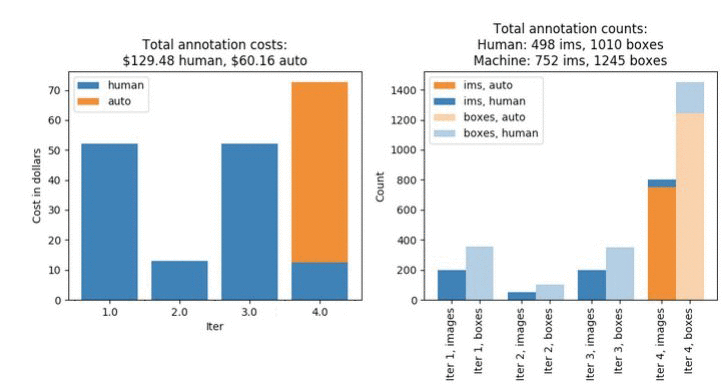
図 3。3 番目のラベリングジョブのラベリングコストとメトリクス。これは、事前にトレーニングされたモデルの利点を生かすことなく、2 番目のラベリングジョブと同じデータセットを使用しています。
結果を比較する
ラベリングジョブをすべて実行したので、結果をより徹底的に比較できます。まず、以下に示す左側のプロットについて考えます。事前トレーニング済みモデルを使用したラベリングジョブの合計経過実行時間は、事前トレーニング済みモデルを使用しないジョブに必要な時間の半分以下です。下の右側のプロットでは、この時間の短縮が、自動的にラベル付けされたデータの大部分と密接に関連していることもわかります。事前トレーニング済みモデルを使用したラベリングジョブが非常に速いのは、機械学習モデルが多くの作業を実行するためです。これは手動ラベリングよりもはるかに効率的です。
これらの結果には、ある程度の変動が予想されることに注意してください。これらのラベリングジョブが行われたときに利用できるワーカーのプールによってもたらされるわずかな変量効果、それに機械学習モデルのトレーニングなどで見られる小さな変動などのため、これら 3 つのラベリングジョブを繰り返し試行することで、数字がわずかに異なる可能性があります。ただし、実験 #2 で見られるコストと時間の大幅節約は、主に事前トレーニング済みモデルを使用したことによります。

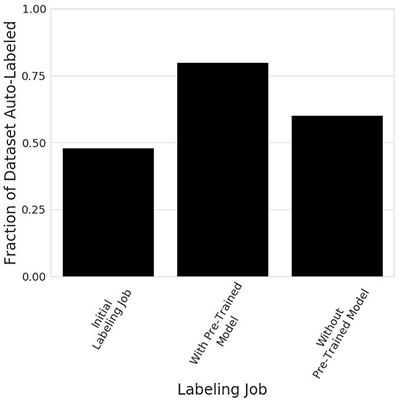
図 4。3 つのラベリングジョブ間のラベリング時間と自動ラベリング効率の比較。
最後に、下のプロットは、ラベリング時間の短縮と機械学習モデルによって注釈が付けられたデータの割合の増加により、合計ラベリングコストが測定可能な程度に削減されたことを示しています。この例では、2 番目のデータセットにラベル付けを行うときに、事前トレーニング済みモデルを使用すると、事前トレーニング済みモデルを使用しなかった制御シナリオと比べて 23%コストが削減されたことがわかります。189.64 USD だったのが 146.80 USD になりました。
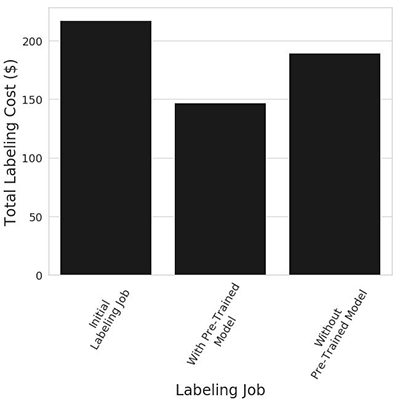
図 5。3 つのラベリングジョブ間の合計ラベリングコスト。
結論
この演習で取り上げたことを振り返ってみましょう。
- Open Images データセットから 2500 枚の鳥の画像からなるデータセットを集めました。
- このデータセットを 2 つに分割しました。
- 1250 枚の画像の最初のサブセットに対してオブジェクト検出ラベリングジョブを作成し、データセットの約 48%が機械でラベル付けされていることを確認しました。
- 2 番目のサブセットに 2 番目のラベリングジョブを作成し、最初のラベリングジョブ中にトレーニングされた機械学習モデルを指定しました。今回は、データセットの約 80%が機械でラベル付けされていることがわかりました。
- 最後のベンチマークとして、トレーニング済みモデルを指定せずに 2 番目のラベリングジョブを再実行しました。そしてデータセットの約 60%が機械でラベル付けされていることがわかりました。
- 結局、事前トレーニング済みモデルを使用すると、ラベルの取得に必要な時間が 50%短縮され、合計ラベリングコストが 23%削減されました。これはコンテキストに大きく依存し、結果はアプリケーションによって異なります。けれども、この例に示されているワークフローは、後続のラベリングジョブに事前トレーニング済みモデルを使用する価値があることを示しています。
このドメイン (例:鳥のオブジェクト検出) でラベルのない新しいデータセットを取得する場合、別のラベリングジョブを設定し、2 番目のラベリングジョブでトレーニングされたモデルを指定することができます。したがって、事前トレーニング済みの機械学習モデルを使用すると、ラベリングジョブを連続して実行でき、各ジョブは前のジョブで得られた予測能力から向上します。 事前トレーニング済みモデル機能では、「ジョブチェーニング」機能 (https://aws.amazon.com/blogs/aws/amazon-sagemaker-ground-truth-keeps-simplifying-labeling-workflows/ で説明されています)、 または付属のサンプルノートブックで示したように、Amazon SageMaker Ground Truth API を使用する必要があることを覚えておいてください。
著者について
 Prateek Jindal は AWS AI のソフトウェア開発エンジニアです。彼は機械学習の世界で複雑なデータラベリング問題を解決することに取り組んでいて、お客様のためにスケーラブルな分散ソリューションを構築することに強い興味を持っています。余暇には料理をするのが大好きで、新しいレストランを試し、ジム通いをしています。
Prateek Jindal は AWS AI のソフトウェア開発エンジニアです。彼は機械学習の世界で複雑なデータラベリング問題を解決することに取り組んでいて、お客様のためにスケーラブルな分散ソリューションを構築することに強い興味を持っています。余暇には料理をするのが大好きで、新しいレストランを試し、ジム通いをしています。
 Jonathan Buck は Amazon のソフトウェアエンジニアです。彼は機械学習を普及させるためのインパクトのあるソフトウェアサービスと製品の構築に焦点を当てています。
Jonathan Buck は Amazon のソフトウェアエンジニアです。彼は機械学習を普及させるためのインパクトのあるソフトウェアサービスと製品の構築に焦点を当てています。