Amazon Web Services ブログ
Amazon SageMaker Ground Truth と自動化されたデータのラベル付けによる低コストでのデータのアノテーション
Amazon SageMaker Ground Truth を使うと、正確にラベル付けされた機械学習データセットを簡単に低価格で構築することができます。ラベル付けのコストを削減するために、Ground Truth の機械学習を使用して、人によるアノテーションが必要な「困難な」画像と、機械学習で自動的にラベル付けできる「簡単な」画像を選択します。この記事では、自動化されたデータのラベル付けの仕組みと、その結果の評価方法について説明します。
自動化されたデータのラベル付けを伴う物体検出ジョブを実行する
以前のブログ記事では、Julien Simon が AWS マネジメントコンソールを使ってデータのラベル付けジョブを実行する方法を説明しました。このプロセスをより細かく制御するには、API を使用できます。 その方法をご紹介するため、今回は鳥の画像 1,000 個に対して バウンディングボックスアノテーション を生成する API を使用した Amazon SageMaker Jupyter ノートブックを使用します。
注意: デモノートブックの実行コストは約 200 USD です。
デモノートブックにアクセスするには、ml.m4.xlarge インスタンスタイプを使用して Amazon SageMaker ノートブックインスタンスを開始します。インスタンスは、このステップバイステップチュートリアルに従ってセットアップできます。ステップ 3 では、IAM ロールの作成時に「任意の S3 バケット」にチェックを入れるようにしてください。 以下にあるように、Jupyter ノートブックを開いて [SageMaker Examples] タブを選択し、object_detection_tutorial.ipynb を起動します。
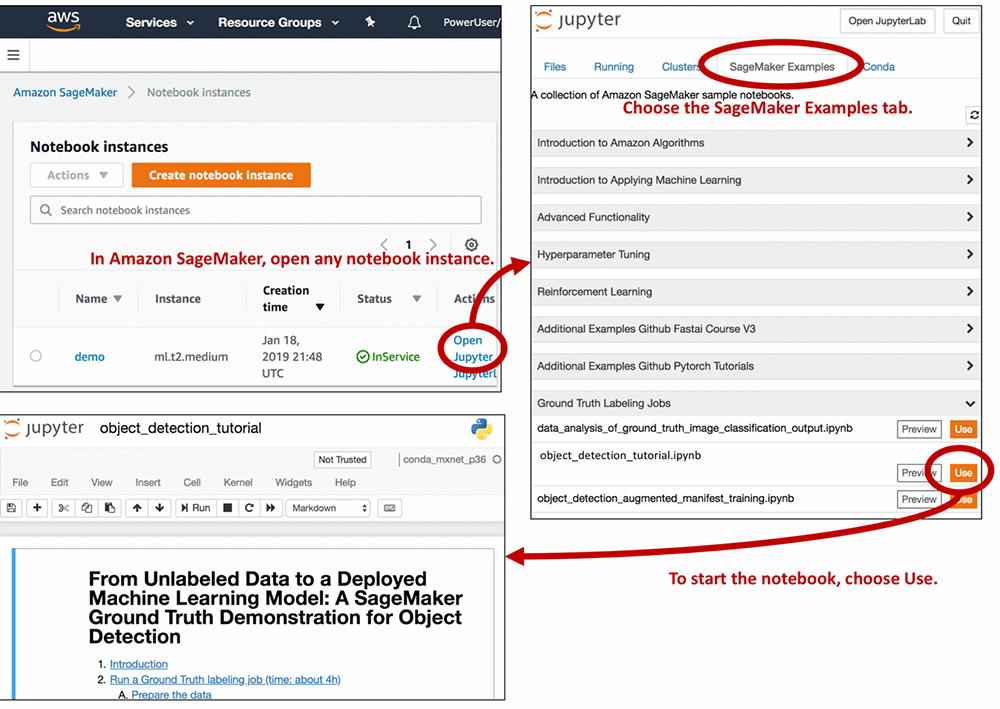
ノートブックの「Introduction」および「Run a Ground Truth labeling job」の各セクションにあるセルのすべてを実行します。セルには変更が必要なものもあるため、ノートブックの指示を注意深く読んでください。これらのセクションを実行すると、以下が行われます。
- 鳥の画像 1,000 個でのデータセットの作成
- 人間のアノテーターのための物体検出指示の作成
- 物体検出アノテーションジョブリクエストの作成
- アノテーションジョブリクエストの Ground Truth への送信
このジョブは約 4 時間かかるはずです。完了したら、「Analyze Ground Truth labeling job results」と「Compare Ground Truth results to standard labels」の各セクションにあるセルのすべてを実行します。これにより、プロット形式の情報が大量に生成されます。Ground Truth がデータにアノテーションを付ける方法を理解するため、一部のプロットを詳しく見てみましょう。
アクティブな学習と自動化されたデータのラベル付け
これらのプロットは、データセット全体のアノテーションに 5 回反復する必要があったことを示しています。Ground Truth は、各反復ごとに画像のバッチを Amazon Mechanical Turk アノテーターに送信しました。以下のグラフは、反復ごとに生成された画像 (プロットでは「ims」に短縮) の数と、これらの画像にあるバウンディングボックスの数を示しています。得られる結果は多少異なる場合があります。
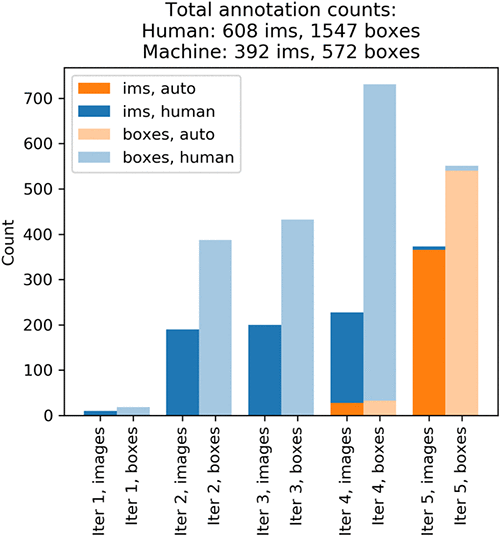
反復 1 では、Mechanical Turk の作業者がランダムに選択された 10 個の画像の小さなテストバッチにアノテーションを付けました。このバッチは、ラベル付けタスクのエンドツーエンド実行を検証します。反復 2 では、Mechanical Turk の作業者が別のランダムに選択された 190 個の画像にアノテーションを付けました。これが検証データセットです。このデータセットは、後ほど自動ラベルの生成のために教師あり機械学習アルゴリズムによって使用されます。反復 3 は、ランダムに選択された追加 200 個の画像について、人によってアノテーション付けされたラベルを取得することでトレーニングデータセットを作成しました。このプロセスの全体を通じて、Ground Truth は、単一アノテーターのバイアスを避けるために、人によってアノテーション付けされた複数のラベルからの各ラベルを統合します。詳細については、ノートブックと Amazon SageMaker 開発者ガイドを参照してください。
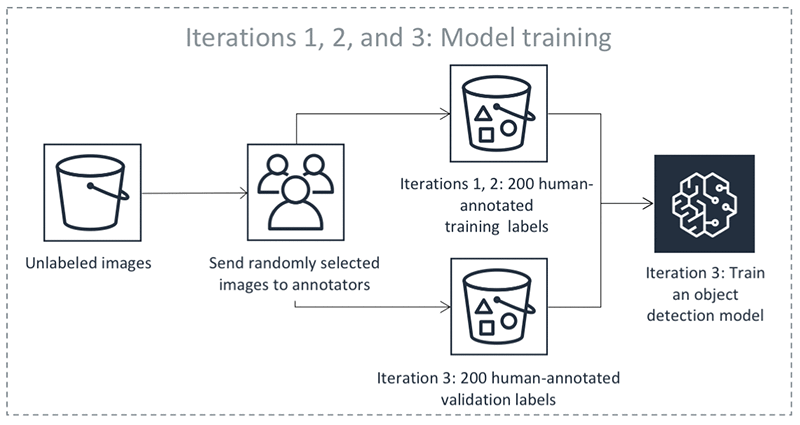
小型のトレーニングデータセットと検証データセットができたところで、後に自動ラベルを生成するアルゴリズムを Ground Truth が訓練する準備が整いました。以下の図は、そのプロセスを示しています。
自動化されたラベル付けには、人がアノテーションを付けたラベルと機械学習によって生成されたラベルの比較が関与するため、バウンディングボックス品質の評価基準を選択する必要があります。この実習には、mean Intersection over Union (mIoU) を使用します。0 の mIoU は、バウンディングボックスの 2 つのセット間に重複がないことを意味します。1 の mIoU は、バウンディングボックスの 2 つのセットが完全に重複することを意味します。ここでの目標は、対応する画像についても人によるアノテーションを取得した場合、人がアノテーションを付けたラベルなら mIoU が少なくとも 0.6 になるであろう自動ラベルを生成することです。これは、バウンディングボックス間における一致を示すためにコンピュータビジョンで一般的に使用されるしきい値である 0.5 よりも若干高い数値です (例えば、ここ にある「This is a break from tradition…」で始まる注記を参照してください)。
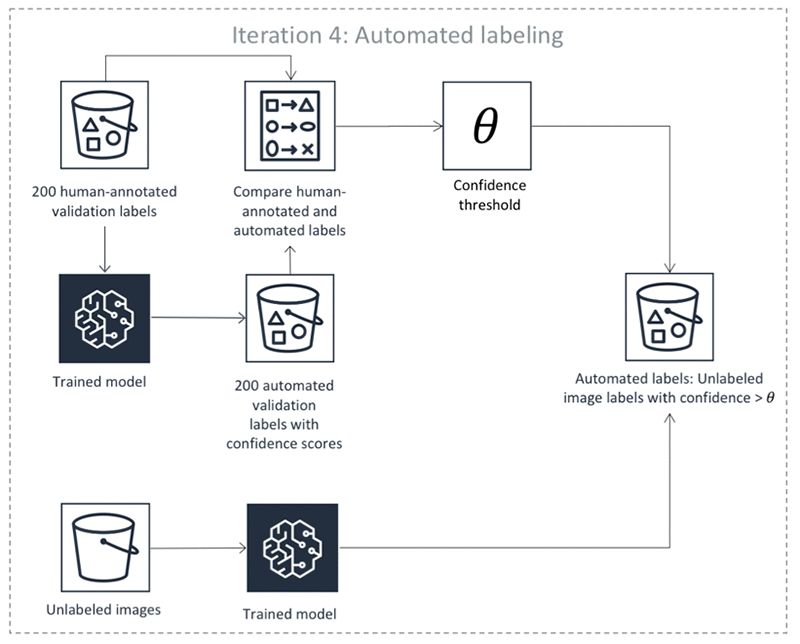
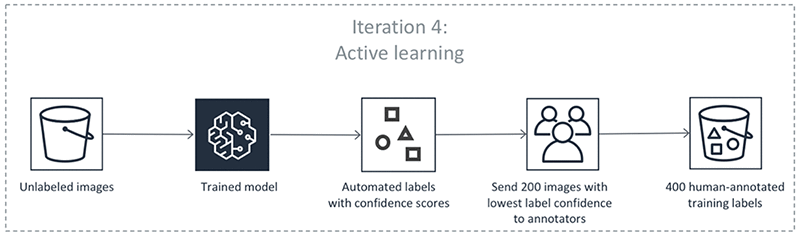
訓練された DL モデルと mIoU 評価基準の設定により、Ground Truth は反復 4 で最初の自動ラベルを生成できるようになりました。これには 4 つのステップがあります。
- 機械学習アルゴリズムを使用して、検証データセットにおけるバウンディングボックスとそれらの信頼度スコアを予測します。反復 1 と 2 のこのデータセットには、人がアノテーション付けしたラベルがあることに留意してください。アルゴリズムが各バウンディングボックスに 0 から 1 の信頼度スコアを割り当てます。特定の画像に対するこれらのスコアを平均化することにより、アルゴリズムは、その予測におけるアルゴリズムの確信レベルを示す画像信頼度スコアを得ます。
- どの画像信頼度しきい値についても、そのしきい値を超えるスコアを得た画像に対するアルゴリズムの予測が、人によるアノテーション付けが行われたラベルとどれほど良く一致しているかを計算することができます。しきい値を超えるラベルの mIoU が少なくとも 0.6 になるしきい値を見つけます。結果として得たしきい値を θ と呼びましょう。
- アルゴリズムを使用して、残りの ラベル付けされていないデータセット (600 画像が含まれます) におけるバウンディングボックスとそれらの信頼度スコアを予測します。
- 信頼度スコアが θ を超える、任意のラベル付けされていないデータセットの予測を取り上げます。ステップ 1 と 2 で、人がアノテーションを付けた検証データセットでは、これらの信頼度スコアが人によるラベルに良く一致する自動化されたアノテーションを示すようにしました。ここで、これらのアノテーションが、ラベル付けされていないデータに対して人間のアノテーターが付けるであろうアノテーションとも一致すると前提しましょう。Ground Truth は、これらのアノテーションを、アルゴリズムによって生成された自動ラベルとして保持します。高い信頼度スコアを持つ自動ラベルが付いた画像を人間のアノテーターに送信する必要はありません。
以下の図は、自動ラベル付けプロセスを表しています。
最初の図を見ると、反復 4 の黄色い棒は、アルゴリズムが 27 個の画像のみを自動的にラベル付けするために十分な確信を持っていたことを示しているのがわかります。より正確な予測を得るには、人間によってラベル付けされたより多くのデータが必要です。しかしこの後は、ユーザーがラベル付けする画像をランダムに選択するのではなく、機械学習モデルに人間のアノテーターに表示する画像を選択させます。
反復 4 では、トレーニングセットのサイズを 400 個に拡大するため、追加 200 個の画像にアノテーションを付けました。最初の図は、反復 1、2、および 3 において、1 画像ごとに約 2 個のバウンディングボックスを得たことを示します。反復 4 では、それが 1 画像ごとに約 3.5 個のボックスになっています! アルゴリズムは、予測されたオブジェクトを多数含む画像へのアノテーション付けは、人間に依頼することが最適だという答を出しました。反復 5 が開始される前に、ユーザーが 400 個のトレーニング画像と 200 個の検証画像を使ってアルゴリズムを再訓練しました。これで、1 回の Ground Truth アノテーションループが完了します。
Ground Truth のアクティブな学習のおかげで、機械学習モデルは素早く学習し、反復 5 では 365 個の画像が自動的にラベル付けされました! すると、ラベルが付けられていない画像は 8 点のみとなります。反復 5 は、これらの画像を人間のアノテーターに送信してタスクを完了します。では、アノテーションコストを反復ごとに見ていきましょう。
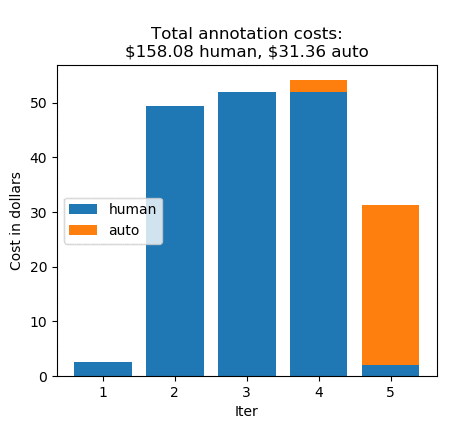
自動化されたデータのラベル付けなしでは、このアノテーションのコストが 0.26 USD × 1000、つまり 260 USD になります。その代わりに、今回は 608 個の人によるラベルに 158.08 USD、392 個の自動ラベルに 31.36 USD の合計 189.44 UDS を支払いました。これは 27% のコスト節約です。(料金の詳細については、Amazon SageMaker Ground Truth の料金ページを参照してください。)
人がアノテーション付けしたラベルと自動ラベルを比較する
自動ラベルは安価ですが、人がアノテーション付けしたラベルと比べるとどうなのでしょうか? 以下の mIoU グラフは、自動ラベルがオリジナルのアノテーションをどれだけ良く反映しているかを示したものです。
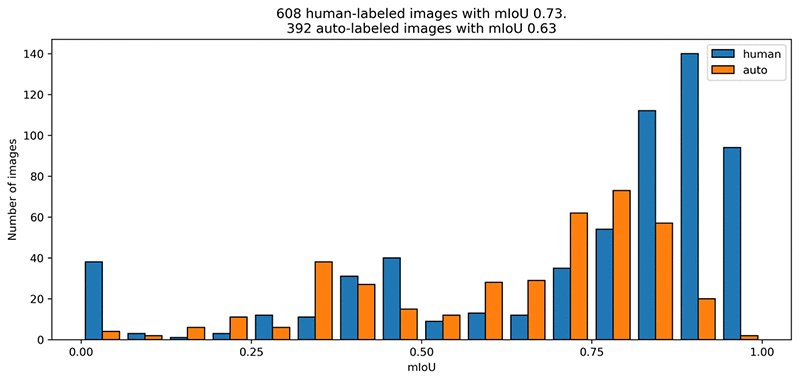
人間のラベラーによるパフォーマンスは、平均より若干良くなっています。自動的にラベル付けされた画像の平均 mIoU は 0.6 をわずかに超えています。これは、先ほど自動ラベラーに設定したラベル品質です。人がアノテーションを付けた画像と、自動的にラベル付けされた画像で、信頼度スコアが最も高い上位 5 の画像を見てみましょう。


結論
Ground Truth は、自動化されたデータのラベル付けによってバウンディングボックスアノテーションコストを 27% 削減しました。この数値は、データセットごとに異なります。画像分類 (人によるアノテーションが安価) では数値が下がり、セマンティックセグメンテーション (人によるアノテーションが高価) では数値が上がるかもしれません。
ぜひこの Jupyter ノートブックを使って実験したり、ノートブックを変更したりしてみてください。他の画像アノテーションタスクのデモもご覧ください。これらは、先ほど検証した Jupyter ノートブックと同じ方法で、どの SageMaker インスタンスからでもアクセスできます!
著者について
 Krzysztof Chalupka は Amazon ML Solutions Lab の応用科学者で、カリフォルニア工科大学から因果推論とコンピュータービジョンの博士号を得ています。Amazon では、コンピュータービジョンと深層学習が人の知能を高める方法を解明しています。仕事以外の時間は家族のために使っており、森、木工細工、そして本 (あらゆる形態の木) も大好きです。
Krzysztof Chalupka は Amazon ML Solutions Lab の応用科学者で、カリフォルニア工科大学から因果推論とコンピュータービジョンの博士号を得ています。Amazon では、コンピュータービジョンと深層学習が人の知能を高める方法を解明しています。仕事以外の時間は家族のために使っており、森、木工細工、そして本 (あらゆる形態の木) も大好きです。
 Tristan McKinney は Amazon ML Solutions Lab の応用科学者で、有効場理論とその高温超伝導体への応用について研究したカリフォルニア工科大学で理論物理学の博士号を取得したばかりです。Tristan の父親は米国陸軍の軍人であったため、子供の頃はドイツとアルバニアを含むあらゆる場所に住んでいました。余暇にはスキーとサッカーを楽しんでいます。
Tristan McKinney は Amazon ML Solutions Lab の応用科学者で、有効場理論とその高温超伝導体への応用について研究したカリフォルニア工科大学で理論物理学の博士号を取得したばかりです。Tristan の父親は米国陸軍の軍人であったため、子供の頃はドイツとアルバニアを含むあらゆる場所に住んでいました。余暇にはスキーとサッカーを楽しんでいます。
 Fedor Zhdanov は Amazon の機械学習サイエンティストで、社内、そして社外のお客様のための機械学習アルゴリズムとツールの開発に携わっています。
Fedor Zhdanov は Amazon の機械学習サイエンティストで、社内、そして社外のお客様のための機械学習アルゴリズムとツールの開発に携わっています。