Amazon Web Services ブログ
Apache MXNet Model Server が規模に応じたモデルサービングのために最適化されたコンテナイメージを追加
AWS は、本番ユースケースのためのモデルサービングのデプロイメントを効率化する Apache MXNet Model Server (MMS) v0.3 をリリースしました。このリリースには、GPU および CPU 上の深層学習ワークロード用に最適化された事前構築済みのコンテナイメージが含まれています。これによって、エンジニアはスケーラブルなサービングインフラストラクチャをセットアップできるようになります。Apache MXNet Model Server (MMS) と、規模に応じて深層学習モデルを提供する方法の詳細については、この先をお読みください!
Apache MXNet Model Server (MMS) とは?
MMS は、オープンソースのモデルサービングフレームワークで、規模に応じて深層学習モデルをデプロイするタスクをシンプル化するように設計されています。以下は MMS の主な利点の一部です。
- MXNet と ONNX のニューラルネットワークモデルを単一のモデルアーカイブにパッケージ化するためのツール。これは、モデルを提供するために必要なアーティファクトのすべてをカプセル化します。
- モデルアーカイブにパッケージ化されたカスタムコードを使用して推論実行パイプラインの各ステップをカスタマイズする機能。これは、初期化、前処理、および後処理の上書きを可能にします。
- 事前設定されたサービングスタック (REST API エンドポイントを含む) と推論エンジン。
- スケーラブルなモデルサービングのために事前構築および最適化されたコンテナイメージ。
- サービスとエンドポイントを監視するためのリアルタイムの運用メトリクス。
このブログ記事では、コンテナを使用して MMS を本番環境にデプロイする方法、クラスターを監視する方法、およびターゲットの需要に応じてスケールする方法を見て行きます。
コンテナでの MMS の実行
スケーラブルな本番用スタックのセットアップに進む前に、コンテナで MMS を実行する方法を確認しましょう。これを理解しておくことは、スケーラブルな本番クラスターのより複雑なセットアップについて考察するときに役立ちます。
この新リリースでは、事前構築され、最適化された MMS コンテナイメージが Docker Hub に発行されます。これらのイメージは、CPU ホスト (Amazon EC2 C5.2xlarge インスタンスタイプ) とマルチ GPU ホスト (Amazon EC2 P3.8xlarge インスタンスタイプ) 用に事前構築および最適化されているため、エンジニアがこれらのインスタンスタイプのために MMS を微調整する必要がありません。
では、オブジェクト分類のための畳み込みニューラルネットワークであるデフォルト SqueezeNet V1.1 に提供を行う、ローカルでコンテナ化された MMS を実行する方法について見て行きましょう。
まず、ローカルでコンテナを取得して実行するために必要となる Docker CLI をインストールします。インストールの詳細はこちらにあります。
次に、Docker Hub から事前構築された MMS CPU コンテナイメージを取得して実行します。
このコマンドは、ホストにコンテナイメージを取得して実行し、デフォルト設定ファイルで MMS を開始します。
MMS コンテナが実行されたら、MMS に対して推論リクエストを呼び出すことができます。イメージをダウンロードすることから始めます。
次に、推論リクエストを呼び出して、MMS にイメージを分類させます。
イメージを 85% の可能性で「Egyptian cat」として分類する JSON レスポンスが表示されるはずです。
コンテナを終了するには、以下のコマンドを実行します。
MMS コンテナのカスタマイズと MMS コンテナが提供するモデルの詳細については、MMS GitHub リポジトリのコンテナドキュメントを参照してください。
MMS クラスターのオーケストレーション、モニタリングおよびスケーリング
ハイスケールでミッションクリティカルな本番システムには、堅固で、モニタリングされたオーケストレーションが必要です。次に、モニタリングとロギング用に Amazon CloudWatch を活用しながら、そのようなクラスターと、MMS および Amazon ECS とのオーケストレーションを行う方法をお見せします。
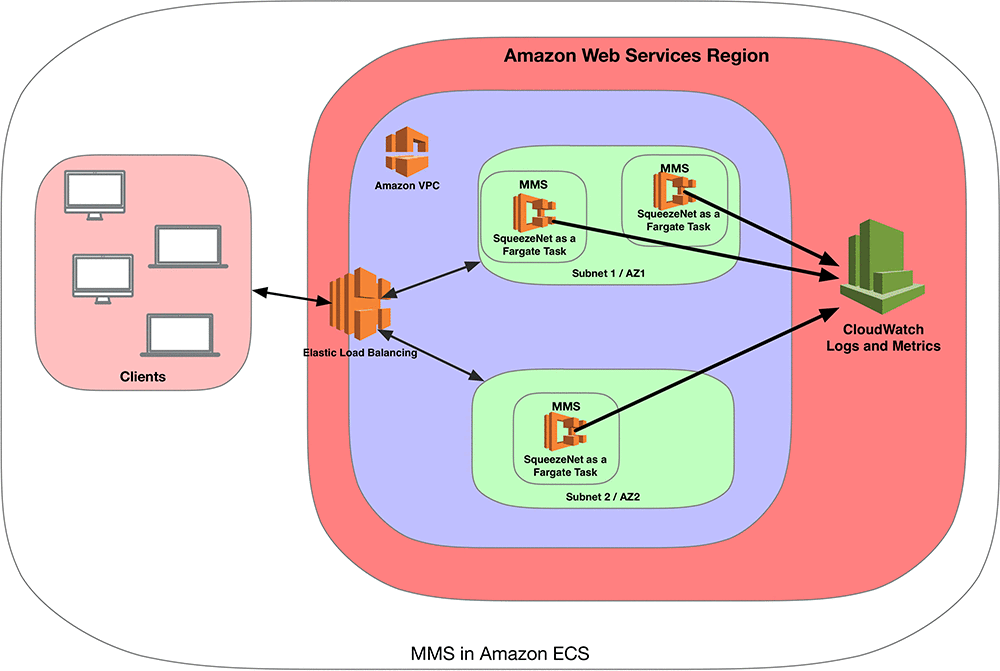
次の図は、Amazon ECS クラスターで MMS を実行するマネージド推論サービスを表すセットアップを説明するものです。ここでは、AWS リージョンのひとつに VPC を作成しました。この VPC は 2 つのアベイラビリティーゾーンで設定されており、サービスレベルの冗長性とセキュリティを提供します。これらのアベイラビリティーゾーンはそれぞれ、AWS Fargate タスクとして MMS を実行しています。AWS Fargate テクノロジーは、基盤となるサーバーを管理する必要なくコンテナを実行することを可能にします。これにより、シームレスにスケールし、MMS 用に使用された AWS Fargate タスクが費やすリソースのみの料金を支払うことができるようになります。このマネージド推論サービスは、ログとメトリクス、およびモニタリングのために Amazon CloudWatch とも統合されています。この VPC には、パブリック DNS 名を提供する Elastic Load Balancing サービスのロードバランサーが接続されています。クライアントはロードバランサーのパブリック DNS 名を使って、それぞれの推論リクエストを送信します。
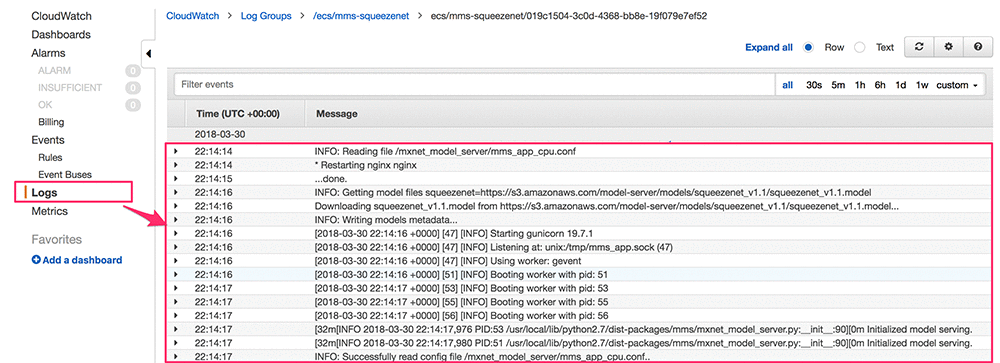
各 MMS Fargate タスクは、awslogs を logDriver として使って設定されています。これにより、サービス固有のログが CloudWatch にプッシュされます。 これらのログにアクセスするには、Amazon CloudWatch コンソールにログオンし、[ログ] タブで設定済みのロググループを見つけます。以下の CloudWatch のログページのスクリーンショットは、MMS サービスが正常に開始され、「SqueezeNet V1.1」に推論リクエストを提供する準備が整っていることを示しています。
同様に、MMS はサービス固有のメトリクスを CloudWatch に発行します。これをセットアップするには、Fargate タスク用に設定されたタスクロールにメトリックデータを発行するための関連 CloudWatch ポリシーがあることを確認する必要があります。これらのメトリクスは、クラスターの正常性とパフォーマンスに関するリアルタイムの通知を受けるためのアラームを作成するために使用できます。また、これらのメトリクスはクラスターの Auto Scaling をトリガーするためにも使用できます。
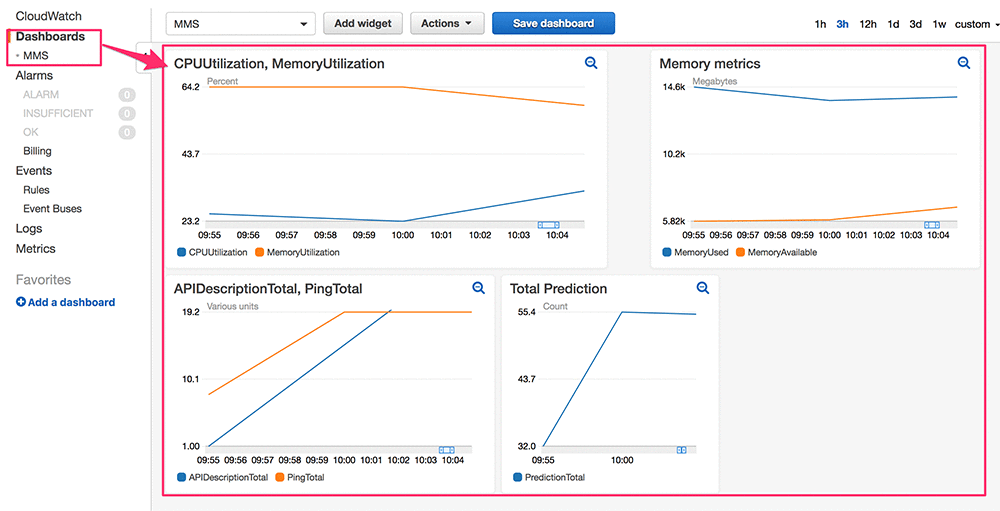
MMS によって発行されたリアルタイムの CloudWatch メトリクスの詳細については、Metrics on Model Server ドキュメントを参照してください。
MMS 本番セットアップの詳細については、MXNet Model Server ドキュメントを参照してください。
MMS のパフォーマンスとスケーラビリティ
前述したように、事前構築された MMS コンテナイメージは、特定のターゲットプラットフォーム用に事前設定および最適化されており、CPU イメージは Amazon EC2 C5.2xlarge インスタンスタイプ用に、GPU イメージは Amazon EC2 P3.8xlarge インスタンスタイプ用に最適化されています。これらのコンテナイメージには必要なドライバーとパッケージがインストールされており、最適化された線型代数ライブラリを活用し、かつ最適なワーカープロセス数、プロセスごとの GPU 割り当て、およびその他設定オプションで事前設定されています。ユースケースとハードウェアのためのコンテナ設定の微調整に関する詳細については、ドキュメント内の Advanced Settingsを参照してください。
ResNet-18 畳み込みニューラルネットワークに提供を行う事前構築された MMS コンテナイメージに対して実行された負荷テストは、単一の CPU インスタンスが毎秒 100 件を超えるリクエストを処理し、単一のマルチ GPU インスタンスが毎秒 650 件を超えるリクエストを処理することを示しています。エラー率はどちらもゼロです。
ここで説明したオーケストレーションされたコンテナクラスターセットアップでは、新しいタスクインスタンスをクラスター内で実行されているサービスに起動することによって、任意の規模のサービス需要に対応するためにクラスターを簡単にスケールアウトすることができます。
詳細と貢献
MMS の詳細については、SSD モデルのエクスポートとサービスを通じて順を追って説明する Single Shot Multi Object Detection (SSD) チュートリアルを参照してください。リポジトリの Model Zoo とドキュメントフォルダーで、多くのサンプルと資料を参照できます。
As we continue to develop MMS, we welcome community participation submitted as questions, requests, and contributions. MMS をすでに使用されている場合は、ぜひリポジトリの GitHub issues でご意見をお聞かせください。
では、使用を開始するために awslabs/mxnet-model-server に移動しましょう!
今回のブログの投稿者について
 Vamshidhar Dantu は AWS 深層学習のソフトウェア開発者です。スケーラブルで簡単にデプロイできる深層学習システムの構築に焦点を当てており、そのかたわらで、家族との時間とバドミントンを楽しんでいます。
Vamshidhar Dantu は AWS 深層学習のソフトウェア開発者です。スケーラブルで簡単にデプロイできる深層学習システムの構築に焦点を当てており、そのかたわらで、家族との時間とバドミントンを楽しんでいます。
 Ankit Khedia は AWS 深層学習のソフトウェアエンジニアです。Ankit は、容易な使用のために深層学習を開発者と研究者の手に委ねるシステムとアプリケーションの開発に関わる分野に重点的に携わっています。仕事以外では、水泳、旅行、ハイキングが好きです。
Ankit Khedia は AWS 深層学習のソフトウェアエンジニアです。Ankit は、容易な使用のために深層学習を開発者と研究者の手に委ねるシステムとアプリケーションの開発に関わる分野に重点的に携わっています。仕事以外では、水泳、旅行、ハイキングが好きです。
 Hagay Lupesko は AWS 深層学習のエンジニアリングリーダーです。開発者やサイエンティストがインテリジェントアプリケーションを構築できるようにする深層学習システムを担当しています。そのかたわらで、読書、ハイキング、家族との時間を楽しんでいます。
Hagay Lupesko は AWS 深層学習のエンジニアリングリーダーです。開発者やサイエンティストがインテリジェントアプリケーションを構築できるようにする深層学習システムを担当しています。そのかたわらで、読書、ハイキング、家族との時間を楽しんでいます。