Amazon Web Services ブログ
Amazon EMR、AWS Glue、Amazon QuickSight を使用して自動データプロファイリングおよびレポートソリューションを構築する
典型的な分析パイプラインでは、データレイクにデータをインポートした後に通常実行する最初のタスクの 1 つは、データプロファイリングと高レベルのデータ品質分析です。これにより、データセットのコンテンツをチェックします。このようにして、テーブル名、列名とそのタイプなどの情報を含む基本的なメタデータを充実させることができます。
データプロファイリングの結果は、データセットに予期した情報が含まれているかどうか、およびそれらを分析パイプラインのダウンストリームでどのように使用するかを決定するのに役立ちます。さらに、これらの結果は、オプションのデータセマンティクス分析ステージへの入力情報の 1 つとして使用できます。
最新のデータレイクには膨大な量のさまざまなタイプのデータがあり、構造化されていない手動のデータプロファイリングとデータセマンティクスの分析は非現実的で時間がかかります。この記事では、AWS Glue データカタログメタデータの拡張として、データプロファイリングリポジトリの自動作成プロセスを実装する方法と、レポートシステムについて説明します。レポートシステムは、分析パイプラインの設計プロセスを支援するもので、信頼性の高いツールを提供することでさらに分析を行えるようにします。
この記事では、AWS Glue データカタログのアプリケーションデータプロファイラーについて詳しく説明し、実装例をステップバイステップで示します。
概要とアーキテクチャ
次の図は、このソリューションのアーキテクチャを示しています。
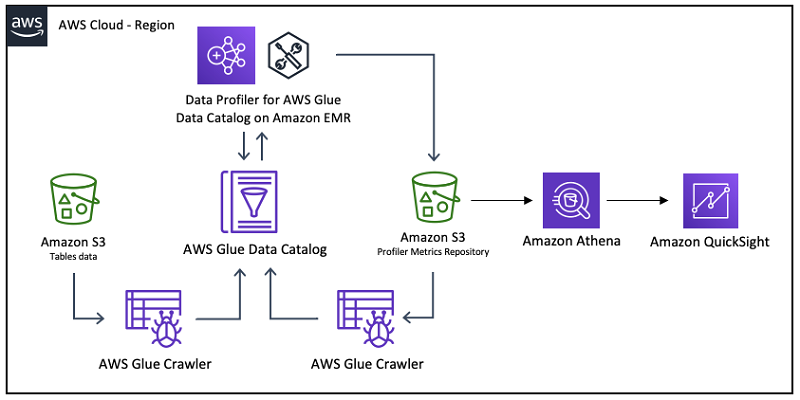
AWS Glue データカタログのデータプロファイラーは、Apache Spark Scala アプリケーションです。これにより、Amazon Deequ ライブラリのプロファイリング機能を使用して、データカタログ内のデータベースで定義されたすべてのテーブルをプロファイリングし、その結果をデータカタログと Amazon S3 バケットにパーティション化された Parquet 形式で保存します。Amazon Athena や Amazon QuickSight などの他の分析サービスを使用して、データをクエリして視覚化できます。
Amazon Deequ データライブラリの詳細については、「Deequ を使用した大規模なテストデータ品質」、または GitHub リポジトリのソースコードをご覧ください。
メタデータは、「データに関するデータ」と定義できます。テーブルのメタデータには、テーブル名とその他の属性、列の名前とタイプ、データを含むファイルの物理的な場所などの情報が含まれています。データカタログは AWS のメタデータリポジトリであり、Athena、Amazon EMR、Amazon Redshift などの他の AWS のサービスで使用できます。
データベース内のテーブルのメタデータを作成または更新した後 (テーブルへの新しいデータの追加など)、AWS Glue クローラを使用して、または手動でアプリケーションを実行して各テーブルをプロファイルできます。結果は、テーブルのメタデータの新しいバージョンとしてデータカタログに保存されます。保存された結果は、AWS Lake Formation コンソールからインタラクティブに表示したり、AWS Glue の AWS CLI からプログラムでクエリしたりできます。
Data Profiler の詳細については、GitHub リポジトリを参照してください。
Deequ ライブラリは、ネストされたデータ (JSON など) を含むテーブルをサポートしていません。ネストされたデータを含むテーブルでアプリケーションを実行する場合は、プロファイリングの前に、そのデータをネスト解除/フラット化するか、リレーショナル化する必要があります。このタスクに役立つ変換の詳細については、AWS Glue Scala DynamicFrame APIs または AWS Glue PySpark Transforms Reference を参照してください。
次のテーブルは、アプリケーションが列データ型のテキストと数値について計算するプロファイリングメトリクスを示しています。テキスト列の一部のプロファイリングメトリクスの計算はコストがかかる可能性があり、デフォルトでは無効になっています。これを有効にするには、compExp 入力パラメータを true に設定します (次のセクションを参照)。
| メトリクス | 説明 | データタイプ |
| ApproxCountDistinct | HyperLogLogPlusPlus スケッチを使用して計算された、個別値の概数。 |
テキスト / 数値 |
| Completeness | 列内の null 以外の値の割合。 | テキスト / 数値 |
| Distinctness | すべての列の値に対する列の個別値の割合。個別値は少なくとも 1 回は出現します。例: [a, a, b] は 2 つの個別値 a と b を含んでいるため、その区別は 2/3 になります。 | テキスト / 数値 |
| MaxLength | 列の最大長。 | テキスト |
| MinLength | 列の最小の長さ。 | テキスト |
| CountDistinct | 個別値の正確な数。 | テキスト |
| Entropy | エントロピーは、考えられるすべてのイベント (列の値) を考慮したときの、イベント (列の値) に含まれる情報レベルの尺度です。これは NATS (情報量の自然単位) で測定されます。観測値を (value_count/total_count) * log(value_count/total_count) の負の合計として、エントロピーを推定します。例: [a, b, b, c, c] は、カウント [1, 2, 2] の 3 つの個別値を持ちます。エントロピーは (-1/5*log(1/5)-2/5*log(2/5)-2/5*log(2/5)) = 1.055 になります。 | テキスト |
| Histogram | テーブルの列の値の概要。指定された列の値をグループ化し、その特定の値を持つ行の数とこの値の割合を計算します。 | テキスト |
| UniqueValueRatio | 列のすべての個別値に対する固有値の割合。固有値は 1 回だけ出現します。個別値は少なくとも 1 回は出現します。例: [a, a, b] は 1 つの固有値 b と 2 つの個別値 a と b を含んでいるため、固有値の割合は 1/2 になります。 | テキスト |
| Uniqueness | 列のすべての値に対する固有値の割合。固有値は 1 回だけ出現します。例: [a, a, b] は 1 つの固有値 b を含んでいるため、一意性は 1/3 です。 | テキスト |
| ApproxQuantiles | 分布の近似分位数。 | 数値 |
| Maximum | 列の最大値。 | 数値 |
| Mean | 列の平均値。 | 数値 |
| Minimum | 列の最小値。 | 数値 |
| StandardDeviation | 列の標準偏差値。 | 数値 |
| Sum | 列の合計。 | 数値 |
アプリケーションの説明
アプリケーションは、一時的または永続的な EMR クラスター (最小バージョンの仕様については、この記事の「EMR クラスターの作成」セクションを参照) で spark-submit を介して実行できます。その際、Spark をインストールして設定し、データカタログ設定オプションの [Spark テーブルメタデータに使用] を有効にします。
次のサンプルコードでアプリケーションを実行します。
次のテーブルは、アプリケーションが受け入れる入力パラメータをまとめたものです。
| 名前 | タイプ | 必須 | デフォルト | 説明 |
--dbName (-d) |
文字列 | はい | 該当なし | データカタログデータベース名。データベースは、アプリケーションを実行するのと同じアカウントが所有するカタログで定義する必要があります。 |
--region (-r) |
文字列 | はい | 該当なし | データカタログデータベースが定義されている AWS リージョンエンドポイント。例: us-west-1 または us-east-1。詳細については、「リージョンのエンドポイント」をご覧ください。 |
--compExp (-c) |
ブール値 | いいえ | false | true の場合、アプリケーションはテキスト列で「高価な」プロファイリングアナライザーも実行します。これらは、CountDistinct、Entropy、Histogram、UniqueValueRatio と Uniqueness です。false の場合、ApproxCountDistinct、Completeness、Distinctness、MaxLength、MinLength のデフォルトのアナライザーのみが実行されます。数値列のすべてのアナライザーは常に実行されます。 |
--statsPrefix (-p) |
文字列 | いいえ | DQP | データカタログの統計名の前に付加される文字列。アプリケーションは、2 本のアンダースコア (__) も追加します。これは、アプリケーションによって計算されたメトリクスを識別するのに役立ちます。 |
--s3BucketPrefix (-s) |
文字列 | いいえ | blank | 形式は s3Buckename/prefix でなければなりません。指定した場合、アプリケーションは、プレフィックス db_name=…/table_name=… にメトリクスを持つ Parquet ファイルを書き込みます。 |
--profileUnsupportedTypes (-u) |
ブール値 | いいえ | false | デフォルトでは、Amazon Deequ ライブラリはテキスト列と数値列のみをサポートしています。このパラメータが true に設定されている場合、アプリケーションはブール値型および日付型の列もプロファイルします。 |
--noOfBins (-b) |
整数 | いいえ | 10 | -compExp (-c) が true の場合、文字列列のヒストグラムアナライザーのために作成する最大値の数を設定します。 |
--quantiles (-q) |
整数 | いいえ | 10 | 数値列の ApproxQuantiles アナライザーのために計算する分位数の数を設定します。 |
環境の設定
次のチュートリアルは、 3 つのテーブルでデータカタログデータベースを作成して入力する方法を示しています。これは、月次更新でプロセスをシミュレートします。この記事では、2019 年 2 月 2 日、2019 年 3 月 2 日、および 2019 年 4 月 2 日の 3 度の月次実行をシミュレートします。
テーブルを作成し、テーブルを月次更新した後、アプリケーションを実行して、データカタログと Amazon S3 リポジトリ内の各テーブルのプロファイリング情報を生成および更新します。この記事では、AWS CLI と Athena を使用してデータをクエリし、シンプルな Amazon QuickSight ダッシュボードを作成する方法の例も示します。
この記事では、AWS の Registry of Open Data にあるニューヨーク市タクシーおよびリムジン委員会 (TLC) の走行記録データを使用します。特に、テーブル yellow_tripdata、fhv_tripdata、および green_tripdata を使用します。
次の手順では、環境を設定する方法について説明します。
EMR クラスターの作成
最初のステップは、EMR クラスターを作成することです。クラスタマスターノードに接続し、spark-submit を介してコードを実行します。クラスターのバージョンが少なくとも 5.28.0 で、少なくとも Hadoop と Spark がインストールされていること、およびデータカタログを Spark のテーブルメタデータとして使用していることを確認します。

マスターノードは SSH 経由でもアクセスできる必要があります。手順については、「SSH を使用してマスターノードに接続する」を参照してください。
アプリケーションのダウンロード
ソースコードをアプリケーション GitHub リポジトリからダウンロードし、すべての依存関係を持つ uber jar を作成できます。次のコマンドで Scala Build Tool (sbt) を使用して、アプリケーションをすべての依存関係を持つ uber jar として作成できます (必要に応じてメモリ値を調整します)。
デフォルトでは、.jar ファイルは、プロジェクトのルートディレクトリに相対する次のパスに作成されます。
./target/scala-2.11/data-profiler-for-aws-glue-data-catalog-assembly-1.0.jar
.jar ファイルが利用可能になったら、EMR クラスターのマスターノードにコピーします。ファイルをマスターノードコードにコピーする 1 つの方法に、ファイルが作成されたクライアントから Amazon S3 にファイルをコピーし、Amazon S3 からマスターノードにダウンロードする方法があります。
この記事では、マスターノードの /home/hadoop ディレクトリにファイルをコピーします。/home/hadoop/data-profiler-for-aws-glue-data-catalog-assembly-1.0.jar が完全なパスです。
S3 バケットのセットアップと初期データのコピー
S3 バケットを使用して、プロファイリングするデータを保存します。この記事では、バケット名は以下です。
s3://aws-big-data-blog-samples/
アカウントに一意の名前でバケットを作成し、そこにデータを保存する必要があります。バケットが作成されて使えるようになったら、AWS CLI を使用して、s3:// nyc-tlc / バケットから 2019 年 1 月の最初のファイルセットをコピーします (それにより、2019 年 2 月 2 日のシミュレーションを実行します)。次のコードを参照してください。
データを宛先バケットにコピーした後、2 番目のバケットを作成して、アプリケーションで作成したプロファイリングメトリクスを含むファイルを保存します。既存のバケットのプレフィックスに指標を書き込むことができるため、この手順はオプションです。次のコードを参照してください。
これで、データカタログにデータベースとテーブルのメタデータを作成する準備ができました。
データカタログにメタデータを作成する
最初のステップは、AWS Glue でデータベースを作成することです。AWS CLI を使用してデータベースを作成できます。次のコードを参照してください。
または、AWS Glue コンソールで、[データベース]、[データベースの追加] の順に選択します。

データベースを作成したら、新しい AWS Glue クローラを作成して、前のステップでコピーしたファイル内のデータのスキーマを推測します。次の手順を実行します。
- AWS Glue コンソールで、[クローラ] を選択します。
- [クローラの追加]] を選択します。
- [クローラ名] には、「
nyc-tlc-db-raw」と入力します。 - [次へ] をクリックします。

- [データストアの選択] では、[S3] を選択します。
- [クロールするデータの場所] では、[自分のアカウントで指定されたパス] を選択します。
- [インクルードパス] には、以前にデータをコピーした S3 バケットとプレフィックスを入力します。
- [次へ] をクリックします。

- [IAM ロールの選択] セクションで、[既存の IAM ロールを選択] をクリックします。
- S3 バケットへのアクセスを提供し、データカタログへの書き込みを許可する IAM ロールを選択するか、このクローラの作成中に新しいロールを作成します。
- [次へ] をクリックします。

- 前に作成したデータベースを選択して、テーブルのメタデータを保存します。
- クローラのプロパティを確認し、[完了] を選択します。

準備ができたらクローラを実行できます。データベースに 3 つの新しいテーブルを作成します。次のスクリーンショットは、クローラが完了したときに受け取る更新通知を示しています。
- これで、Lake Formation コンソールを使用して、テーブルが正しいことを確認できます。テーブル
 の次のスクリーンショットを参照してください。テーブルの 1 つを選択すると、テーブルのバージョンが 0 になりました。次のスクリーンショットを参照してください。
の次のスクリーンショットを参照してください。テーブルの 1 つを選択すると、テーブルのバージョンが 0 になりました。次のスクリーンショットを参照してください。 AWS CLI を使用して同じチェックを実行することもできます。次のコードを参照してください。
AWS CLI を使用して同じチェックを実行することもできます。次のコードを参照してください。
- テーブルのメタデータのパラメータをチェックして、クローラが生成した値を確認します。次のコードを参照してください。
- 同じテーブルの 3 つの列のメタデータ属性を確認します。この記事では、データタイプが異なるため次の列を選択していますが、他のどの列に対してもこのチェックを行えます。次のコードでは、列で現在使用できる属性は「
Name」と「Type」だけです。
Lake Formation コンソールで同じ情報を表示できます。次のスクリーンショットを参照してください。


これで、アプリケーションを実行する準備ができました。
最初のアプリケーションの実行
SSH 経由で EMR クラスターマスターノードに接続し、次のコードを使用してアプリケーションを実行します (必要に応じて入力パラメータ、特に s3BucketPrefix パラメータの値を変更します)。
データカタログのメタデータのプロファイリング情報
アプリケーションが完了したら、Lake Formation コンソールでテーブルのメタデータを再確認し、新しいテーブルバージョンが作成されたことを確認できます。次のスクリーンショットを参照してください。

AWS CLI でも同じ情報を確認できます。次のコードを参照してください。
テーブルのメタデータを確認し、アプリケーションが生成したプロファイリング情報が正常に保存されたことを確認します。次のコードではパラメータ「DQP__Size」が生成されました。これには、Deequ ライブラリで計算されたテーブル内のレコード数が含まれています。
同様に、以前にチェックした列のメタデータに、アプリケーションが生成したプロファイリング情報が含まれていることを確認できます。これは、各列の「Parameters」オブジェクトに格納されます。新しい各属性は、statsPrefix 入力パラメータで指定された文字列「DQP」で始まります。次のコードを参照してください。
「DQP__name-xx」という名前のパラメータは、数値列に対する ApproxQuantiles Deequ アナライザーの結果です。分位数は、アプリケーションの –quantiles (-q) 入力パラメータを介して設定されます。次のコードを参照してください。
Amazon S3 のプロファイリング情報
これで、プロファイリング情報が s3BucketPrefix アプリケーション入力パラメータで指定した S3 バケットに Parquet 形式で保存されたことを確認することもできます。次のスクリーンショットは、Amazon S3 コンソールを介したバケットを示しています。

データは、Apache Hive パーティションと互換性のあるプレフィックスを用いて保存されます。これは、Athena などの分析サービスを使用するときにパフォーマンスとコストを最適化するのに役立ちます。パーティションは、db_name および table_name で定義されています。次のスクリーンショットは、table_name=trip_data_yellow の詳細を示しています。

アプリケーションを実行するたびに、物理テーブルごとにメトリクステーブルにデータを追加する 1 つの Parquet ファイルが生成されます。
テーブルの月次更新後の 2 回目の実行
テーブルの月次更新後にアプリケーションを実行するには、以下の手順を実行します。
- 2019 年 2 月の新しいファイルをコピーして、3 月 2 日のシステムの月次更新をシミュレートします。次のコードを参照してください。
nyc-tlc-db-rawクローラを実行して、テーブルメタデータを更新し、新しいファイルを含めます。次のスクリーンショットは、3 つのテーブルが正常に更新されたことを示しています。
- クローラが 3 番目のバージョンのテーブルを作成したことを確認します。次のコードを参照してください。
- アプリケーションを再実行して、新しいプロファイリングメタデータを生成し、以前と同じコードを入力します。クリーンな情報を保持するために、メタデータに新しいプロファイリング情報を保存する前に、アプリケーションは、「
statsPrefix」で指定された文字列で始まるすべてのカスタム属性を削除します。次のコードを参照してください。正常に実行された後、テーブルの新しいバージョンが作成されました。次のコードを参照してください。
DQP__Size属性の値を確認してください。その値が変更されました。次のコードを参照してください。- 前に表示した列の 1 つをチェックして、更新されたプロファイリングプロパティ値を確認します。次のコードを参照してください。
テーブルの月次更新後の 3 回目の実行
アプリケーションの 3 回目の実行には、次の手順を実行します。
- 2019 年 3 月の新しいファイルをコピーして、4 月 2 日のシステムの月次更新をシミュレートします。次のコードを参照してください。
nyc-tlc-db-rawクローラを実行して、テーブルメタデータを更新し、新しいファイルを含めます。これで、テーブルメタデータに 5 つのバージョンができました。次のコードを参照してください。- アプリケーションを再実行して、プロファイリング情報を更新します。次のコードを参照してください。
DQP__Sizeパラメータをチェックして、新しく更新された値を確認します。次のコードを参照してください。- 前に表示した列の 1 つをチェックして、プロファイリングプロパティの値を更新します。次のコードを参照してください。
Lake Formation コンソールで同じ値を表示および管理できます。次の [列の編集] セクションのスクリーンショットをご覧ください。

Athena と Amazon QuickSight を使用したデータプロファイリングレポート
前述のように、アプリケーションはプロファイリング情報を Parquet 形式で S3 バケットに保存し、プレフィックスを db_name および table_name パーティションに保存できます。次のコードを参照してください。
アプリケーションは、実行ごとに 1 つの Parquet ファイルを生成します。
プロファイラーメトリクスデータのメタデータの作成
プロファイラーメトリクスデータのメタデータを作成するには、次の手順を実行します。
- Lake Formation コンソールで、
deequprofilerdbという名前の新しいデータベースを作成して、メタデータを含めます。
- AWS Glue コンソールで、
deequ-profiler-metricsという名前の新しいクローラを作成して、Amazon S3 に保存されているプロファイリング情報のスキーマを推測します。
次のスクリーンショットは、新しいクローラのプロパティを示しています。

クローラを実行した後、deequ_profiler_metrics という名前の 1 つのテーブルがデータベースに作成されました。テーブルには次の列があります。
| 名前 | データタイプ | パーティション | 説明 |
インスタンス |
文字列 | 「name」列の統計が参照する列名。エンティティが「Dataset」の場合、「*」に設定します。 |
|
エンティティ |
文字列 | 統計が参照するエンティティ。有効な値は「Column」と「Dataset」です。 |
|
名前 |
文字列 | 計算に使用される Deequ Analyzer から派生したメトリクス名。 | |
値 |
ダブル | メトリクスの値。 | |
タイプ |
文字列 | エンティティが「Column」の場合は列のデータ型、それ以外の場合は空白。 |
|
db_name_embed |
文字列 | データベース名。パーティション「db_name」と同じ値。 |
|
table_name_embed |
文字列 | テーブル名。パーティション「table_name」と同じ値。 |
|
profiler_run_dt |
日付 | プロファイラーアプリケーションが実行された日付。 | |
profiler_run_ts |
タイムスタンプ | プロファイルアプリケーションが実行された日時。実行識別子としても使用できます。 | |
db_name |
文字列 | 1 | データベース名。 |
table_name |
文字列 | 2 | テーブル名。 |
Athena によるレポート
Athena を使用して、データベース内の列の統計をチェックするクエリを実行して、2019 年 3 月に行った実行を確認できます。次のコードを参照してください。
次のスクリーンショットに、このクエリが返す結果を示します。

Amazon QuickSight によるレポート
アプリケーションが生成したプロファイリングメトリクスデータに基づいて、Amazon QuickSight にダッシュボードを作成するには、次の手順を実行します。
- データソースとして Athena を使用して、
deequ_profiler_metricsという新しい QuickSight データセットを作成します。
- [テーブルの選択] セクションで、前に作成したプロファイリングメトリクステーブルを選択します。
- データを SPICE にインポートします。

データセットを作成した後、それを表示してそのプロパティを編集できます。この記事では、プロパティは変更しません。

これで、視覚化とダッシュボードを作成する準備が整いました。
このセクションの次の画像は、コントロールによる簡単な分析を示しています。これにより、データベース、プロファイルされたテーブル、エンティティ、列、およびプロファイリングメトリクスの選択が可能になります。
| コントロール名 | マップされた列 |
| データベース | db_name |
| テーブル | table_name |
| エンティティ | エンティティ |
| 列 | インスタンス |
| プロファイリングメトリクス | 名前 |
コントロールの追加の詳細については、「パラメータ、オンスクリーンコントロール、URL アクションでインパクトがある Amazon QuickSight ダッシュボードを作成する」を参照してください。
たとえば、特定のテーブルの Size メトリクスを選択して、月ごとのロード後にテーブルで使用できるレコード数を確認できます。次のスクリーンショットを参照してください。

同様に、同じ分析を用いて、ある列について特定のメトリクスが時間の経過とともにどのように変化するかを確認できます。次のスクリーンショットは、月ごとのロード後に fare_amount 列の平均値が変化することを示しています。

任意の列で計算された任意のメトリクスを選択できるため、非常に柔軟なプロファイリングデータレポートシステムになります。

まとめ
この記事では、データカタログに含まれるメタデータを拡張する方法を示しました。それには、EMR クラスターで実行されている Amazon Deequ ライブラリに基づいて Apache Spark アプリケーションで計算されたプロファイリング情報を使用しました。
AWS CLI を使用してデータカタログをクエリできます。Athena と Amazon QuickSight を使用してレポートシステムを構築し、Amazon S3 に保存されているデータをクエリして視覚化することもできます。
Amazon Search の Sebastian Schelter と AWS の Sven Hansen と Vincent Gromakowski の助力とサポートに感謝します。
著者について
 Francesco Marelli は、アマゾン ウェブ サービスのシニアソリューションアーキテクトです。 彼はロンドンで 10 年間働いた後、イタリア、スイス、および欧州、中東、アフリカの他の国で仕事をしてきました。主にエンタープライズおよび FSI の顧客向けに、分析、データ管理、ビッグデータシステムの設計と実装を行うことを専門としています。Francesco は、システム統合と、ウェブアプリケーションの設計や実装においても豊富な経験を持っています。彼は専門知識の共有、レコード盤の収集、そしてベースの演奏を楽しんでいます。
Francesco Marelli は、アマゾン ウェブ サービスのシニアソリューションアーキテクトです。 彼はロンドンで 10 年間働いた後、イタリア、スイス、および欧州、中東、アフリカの他の国で仕事をしてきました。主にエンタープライズおよび FSI の顧客向けに、分析、データ管理、ビッグデータシステムの設計と実装を行うことを専門としています。Francesco は、システム統合と、ウェブアプリケーションの設計や実装においても豊富な経験を持っています。彼は専門知識の共有、レコード盤の収集、そしてベースの演奏を楽しんでいます。