Amazon Web Services ブログ
ByteDance が AWS Inferentia の利用により、推論におけるレイテンシの削減とスループットの向上とともに、最大で60%のコスト削減を実現
この記事は、 “ByteDance saves up to 60% on inference costs while reducing latency and increasing throughput using AWS Inferentia” を翻訳したものです。
このブログは、ByteDance の Minghui Yu と Jianzhe Xiao との共同執筆によって寄稿されました。
ByteDance は、さまざまな言語、文化、地域の人々に対して、情報や教育の提供を行い、楽しませ、刺激を与えるコンテンツプラットフォームを提供するテクノロジー企業です。ユーザーは豊富かつ直感的、また安全であることを理由に、私たちのコンテンツプラットフォームを信頼して楽しんでいます。このような体験は私たちの機械学習 (ML) バックエンドエンジンによって実現しており、それらの ML モデルはコンテンツモデレーションや、検索、レコメンド、広告、真新しいビジュアルエフェクトを提供します。
ByteDanceの AML (Applied Machine Learning) チームは私たちのビジネスにおいて、高いパフォーマンスと信頼性を保ち、かつスケーラブルな ML システムや end-to-end な ML サービスを提供しています。私たちは ML の推論システムのコストを、応答時間を増加することなく削減する方法を探していました。AWS が ML 推論専用の高性能チップである AWS Inferentia をリリースした際に、AWS のアカウントチームと連携し AWS Inferentia が私たちの最適化の目標を満たせるか検証しました。いくつかの PoC を行い、結果として T4 GPU ベースの EC2 G4dn インスタンスと比較して60%ものコスト削減と、最大25%の推論レイテンシーの削減が得られました。このコスト削減とパフォーマンス向上の結果から、私たちは本番環境のモデルを AWS Infrentia をベースとしたインスタンスである Amazon Elastic Compute Cloud (Amazon EC2) Inf1 にデプロイすることにしました。
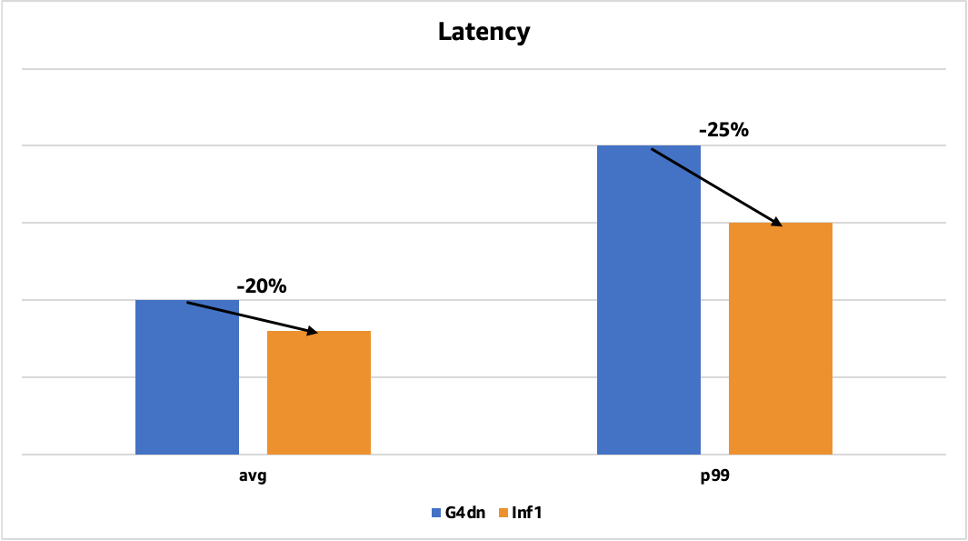
以下のグラフはレイテンシーの改善を示しており、以前取り扱った顔検出モデルを、TensorRT を用いてGPU にデプロイした場合との比較になります。平均のレイテンシーの削減率は 20% (50 ミリ秒から 40 ミリ秒)で、p99のレイテンシーの削減率は 25% (200ミリ秒から150ミリ秒) でした。
この記事では、AWS Inferentia を利用してレイテンシーの削減やスループットの向上を行いながら、コスト削減も実現した方法を紹介します。
高性能かつコスト効率の良い計算の探索
ByteDance AML チームは最先端の ML システムと、それらが必要とするヘテロジニアス・コンピューティングの研究に重点においています。私たちはさまざまなレコメンドシステムや自然言語処理 (NLP)、コンピュータービジョン (CV) のモデルのために大規模な学習や推論のシステムを構築しています。これらのモデルはとても複雑で、ByteDance が運営する複数のコンテンツプラットフォームから得られる膨大なデータを処理します。クラウドでもオンプレミス環境でも、これらのモデルのデプロイには膨大な GPU リソースが必要になります。そのためこれらの推論システムの計算コストは非常に高価になります。
私たちはスループットやレイテンシーに大きな影響を及ぼすことなくコストの削減をしたいと考えていました。また私たちはクラウドの柔軟性や、オンプレミスのセットアップよりもはるかに短いデリバリーのサイクルも求めていました。さらに、ML の高速化の新しい選択肢を模索していましたが、一方でシームレスな開発者体験も求めていました。
私たちは AWS から、AWS Inferentia ベースの EC2 Inf1 インスタンスが、クラウド上で最も低い推論単価かつ高性能な ML 推論を提供できるという情報を受けました。調べてみると、大量の画像、物体、音声、テキストデータに対して機械学習を行っている私たちのケースに適していることがわかりました。私たちのモデルの複雑さと日々の予測量を考えると、間違いなく私たちの目標にぴったりでした。さらに AWS Inferentia は巨大なオンチップメモリを有しているため、巨大なモデルをチップ外部のメモリに保存するのではなくキャッシュを利用することが可能です。Neuron コアと呼ばれる AWS Inferentia 内の処理エンジンはオンチップメモリに格納されたモデルへ高速にアクセスでき、オフチップメモリの帯域幅に制限されないため、推論にかかるレイテンシーを大幅に削減することができます。
いくつかの選択肢を評価した結果、 G4dn インスタンスやオンプレミスの NVIDIA T4 と比べてパフォーマンス / 価格の比率が優れているため、最終的に EC2 Inf1 インスタンスを選択しました。私たちは Inf1 のコストとパフォーマンスのメリットを引き出すために、 AWS と継続的な連携を行いました。
AWS Inferentia への推論ワークロードのデプロイ
AWS Neuron SDK を使用して AWS Inferentia を使い始めるには、モデルコードのコンパイルと Inf1 インスタンスへのデプロイの 2 つのフェーズが必要です。ML モデルを新しいインフラストラクチャに移行するときによくあることですが、いくつかの課題に直面しました。AWS による努力とサポートのおかげで、これらの課題を克服することができました。以下の章では、AWS Inferentia に推論ワークロードをデプロイした経験に基づいて、いくつかの役立つヒントや知見を紹介します。
OCR の Conformer モデル
私たちの光学的文字認識 (OCR) の Conformer モデルは画像内の文字を検出して読み取ります。私たちはレイテンシーが低い状態を保ちながら、さまざまなバッチサイズで高パフォーマンス (QPS) を得るために、いくつかの最適化を行いました。その中で重要である最適化は以下の通りです。
- コンパイラの最適化 – 通常、Inferentia は固定長の入力に対して最善のパフォーマンスを発揮するため、テキストデータが固定長ではないということが課題となっていました。これを解決するために、モデルを encoder と decoder の二つに分割することにしました。これらの二つのサブモデルを個別でコンパイルした後に、TorchScript を用いて一つのモデルにまとめました。for ループの制御フローを CPU 上で実行することで、 Inferentia 上で可変長のシーケンスに対応可能となりました。
- depthwise 畳み込みのパフォーマンス – 私たちの Conformer モデルで頻繁に使用される depthwise 畳み込み演算において、DMA のボトルネックが発生しました。私たちは DMA アクセスの性能ボトルネックを特定し解消するために AWS Neuron チームと緊密に連携しました。これにより、ボトルネックとなった演算のパフォーマンスが向上し、OCR モデルの全体的なパフォーマンスが向上しました。
私たちは Inferentia へのデプロイを最適化するため、二種類のモデルを作成しました。
- encoder/decoder の結合と展開 – 個別にコンパイルした encoderと decoder を使用する代わりに、encoder と完全に展開した decoder を一つのモデルにまとめ、一つの Neuron Executable File Format (NEFF)としてコンパイルしました。decoder を展開することで、CPU の操作を一切使わずに Inferentia 上で全ての decoder の制御フローを実行できます。この方法においては、各イテレーションで decoder はトークンに必要な計算リソースのみを使用することになります。また、入力のパディングによって必要となっていた余分な計算が削減されるため、パフォーマンスが向上します。さらに、decoder のイテレーション間で Inferentia から CPU へのデータ転送が必要ないため、I/O 時間が大幅に削減されます。このバージョンのモデルはアーリーストッピングをサポートしていません。
- 部分的に展開させた decoder – 完全に展開した状態で結合させたモデルと同様に、こちらのモデルでは、decoder の複数のイテレーションを展開し、1 回の実行としてコンパイルします (ただし encoder は含まれません)。例えば、配列の最大長が 75 の場合、decoder を 3 つのパーティションに分解して、トークンの 1-25、26-50、51 -75 部分を計算します。I/O という観点でも、encoder の出力を反復ごとに 1 回転送する必要がないため、大幅に高速となります。代わりに、出力は各 decoder のパーティションごとに 1 回だけ転送されます。この場合のモデルはアーリーストッピングをサポートしていますが、パーティションの境界でのみ可能です。パーティションの境界は、特定のアプリケーションごとに調整して、リクエストの大部分が 1 つのパーティションのみを実行するようにすることができます。
さらなるパフォーマンスの向上を目指し、私たちはメモリ使用量の削減やアクセス効率の改善を行いました。
- テンソルの重複排除とコピーの削減 – テンソルを再利用しメモリ空間の効率を上げることで、展開されたモデルのサイズと命令 / メモリアクセスの数を大幅に削減するコンパイラの最適化になります。
- 命令数の削減 – パディングされていない場合の decoder を使用することで、命令数を劇的に削減することができるコンパイラの最適化になります。
- マルチコア重複排除 – テンソルの重複排除に変わるランタイム最適化になります。このオプションによって、すべてのマルチコアのメモリ空間の効率が大幅に向上します。
ResNet50 による画像分類
ResNet50 は画像分類用の事前学習済みの深層学習モデルです。畳み込みニューラルネットワーク (CNN または ConvNet) は視覚画像の分析に最もよく使われます。Inferentia においてこのモデルのパフォーマンスを向上させるために、私たちは次の手法を使用しました。
- モデルの変換 – ByteDace のモデルは ONNX 形式で出力されますが、Inferentia では現在正式に対応していません。これらの ONNX モデルを処理するために、AWS Neuron チームはモデルを ONNX 形式から PyTorch モデルへと変換するスクリプトを提供し、これにより torch-neuron を使用して直接、Inferentia へのコンパイルが行えるようになりました。
- パフォーマンス最適化 – 私たちは AWS Neuron チームと緊密に連携して、ResNet50 のモデルのパフォーマンスを最適化するように、コンパイラの scheduling heuristic を調節しました。
コンテンツモデレーション用のマルチモーダルモデル
私たちのマルチモーダルな深層学習モデルは複数のモデルの組み合わせになっています。このモデルのサイズは比較的大きいため、Inferentia 上への読み込みの失敗を引き起こしていました。AWS Neuron チームはこの問題を重みの共有を行いデバイスの消費メモリを削減することで解決に成功しました。Neuron チームは、この重みの重複を排除する機能を Neuron libnrt ライブラリに実装し、さらに Neuron ツールを改善してメトリクスの適正化を行いました。重みの重複排除機能は、推論実行前に以下の環境変数を設定することで有効化されます。
NEURON_RT_MULTI_INSTANCE_SHARED_WEIGHTS=1
アップデートされた Neuron SDK によって、重複していたモデルによる全体のメモリ消費が削減され、マルチモーダルモデルをマルチコア上にデプロイすることが可能になりました。
より多くのモデルの AWS Inferentia への移行
ByteDance では、毎月約 20 億人のアクティブユーザーに快適なユーザー体験を提供するため、引き続き革新的な深層学習モデルを展開しています。事業規模が巨大であるため、私たちはコストの節約とパフォーマンス最適化の方法を常に模索しています。私たちは、引き続きモデルの AWS Inferentia への移行を行い、その高いパフォーマンスとコスト効率のメリットを享受していくつもりです。また、私たちは AWS に対して AWS Inferentia ベースのインスタンスタイプも増やしてほしいとも考えています。例えば前処理タスクのために vCPU を増やしたタイプなどです。今後、ByteDance は ML アプリケーションに最高の価格パフォーマンスを提供するために、AWS によるシリコンイノベーションがさらに増えることを期待しています。
AWS Inferentia が推論アプリケーションのパフォーマンスを最適化しながらコストを節約するのにどのように役立つかについて詳しく知りたい場合は、Amazon EC2 Inf1 インスタンス 製品ページをご覧ください。
このブログは、ソリューションアーキテクトの松崎が翻訳しました。原文はこちらをご覧ください。