Amazon Web Services ブログ
AWS Glue データカタログを使用して、Amazon EMR で実行中の Presto に対して表のメタデータを容易に管理する
Amazon EMR は多くのカスタマーに、Apache Spark、Apache HBase、Presto、およびApache Flink などの一般的な分散型フレームワークを使用して、ビッグデータ処理あぷロケーションを素早く、コスト効率良く構築するようにエンパワメントします。Amazon EMR の分析アプリケーションを作成している組織の場合、自動化された形式でデータ資産を整理する必要がますます大きくなります。データベースは指数関数的に成長する傾向があるため、カタログ作成ツールを使用することは、データ探索を自動化し、データ資産を整理するために重要です。
AWS Glue データカタログは、この重要な機能を備えており、中央レポジトリのデータストアに関してメタデータを自動的に探索してカタログ作成できます。Amazon EMR 5.8.0 以降、カスタマーは Amazon EMR で実行中の Apache Hive と Spark SQL アプリケーションにメタデータストアとして AWS Glue データカタログを使用してきました。Amazon EMR 5.10.0 から、AWS Glue を使用してデータセットをカタログ化し、Hue (Hadoop User Experience) と Apache Zeppelin UI から Amazon EMR で Presto を使用してクエリを実行できます。
Amazon EMR 上で Prestoを実行するにはどのようなシナリオが必要か、Amazon Athena(Presto を hood の下でクエリとして使用する)を選択するのはいつかを迷うことがあるかもしれません。大量のデータをクエリし、さまざまなニーズとユースケースにたいおうするために、両方とも素晴らしいツールであることを理解することが重要です。
Amazon Athena は、サーバーをセットアップしたり、管理したりする必要なく、Amazon S3 のデータの対話形式のクエリを実行するための最も容易な方法を提供します。Presto はAmazon EMR で実行され、必要に応じて、データソースをフェデレーションする機能を備え、構成方法とクエリの実行においてより柔軟性があります。たとえば、Presto CLI または JDBC/ODBC ドライバーなどのクライアントに LDAP 認証を必要とするユースケースがある場合があります。または、MySQL/Amazon Redshift/Apache Cassandra および Hive のような異なるシステム間でデータを結合することが必要なワークフローがある場合があります。これらの例では、Amazon EMR で実行中の Presto は、クラスタの開始時に希望のデータベースコネクターに加えて、LDAP 認証を有効にするように構成できるため、使用する適切なツールです。
ここで、Presto のメタデータ管理が AWS Glue で機能する様子を見てみましょう。
AWS Glue クローラを使用して、データセットを探索します
AWS Glue データカタログは、データセットのロケーション、スキーマ、ランタイムメトリクスの参照です。この参照メタデータを作成するために、AWS Glue はお使いのデータセットをクロールする必要があります。この演習では、AWS Glue クローラを使用して、NYC taxi rides データセットのデータカタログの表を自動記入します。
クローラを追加するためには、以下の手順に従ってください。
- AWS マネジメントコンソールにサインインし、AWS Glue コンソールを開きます。ナビゲーションペインで [クローラ] を選択します。次に、[クローラの追加] を選択します。
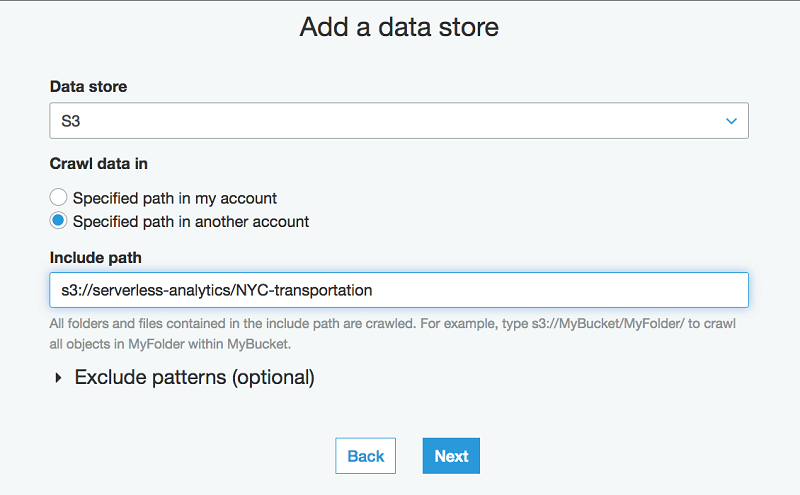
- [データストアの追加] ページで、NYC taxi rides データセットの場所を指定します。
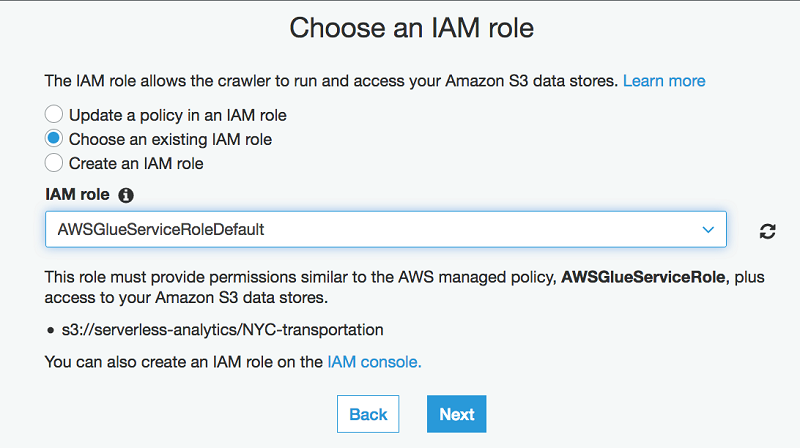
- 次の手順で、既存の IAM ロールがある場合はそれを選択するか、新しいロールを作成します。次に、[次へ] を選択します。
- スケジューリングページで、[頻度] については、[オンデマンドで実行] を選択します。
- [クローラの出力の構成] ページで、[データベースの追加] を選択します。データベース名として blog-db を指定します。(好きな名前を指定できますが、クエリを実行するときは正しいデータベース名を選択してください。)
- デフォルト値を使用して残りの手順に従って、クローラを作成します。

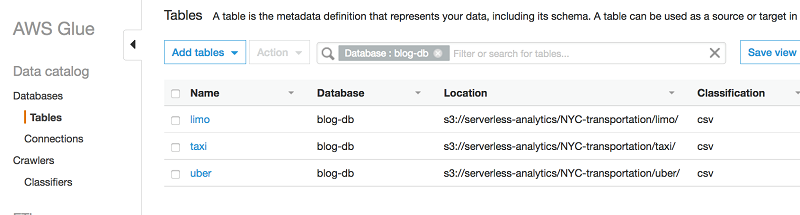
- クローラが準備完了状態を表示しているとき、データベースに移動します (次のスクリーンショットで示されているように、データベースのリストから blog-db を選択するか、フィルターとしてそれを指定して検索します)。 次に、[表] を選択します。以下のとおり、クローラにより作成された 3 つの表を確認できます。
- (オプション) 探索されたデータは、CSV ファイルで分類されます。オプションでクエリの応答時間を短くするために、このデータを Parquet 形式に変換できます。
Amazon EMR クラスタの開始
探索され、整理されたデータセットを使用して、ここでは、AWS Glue データカタログを使用するために Amazon EMR クラスタで Presto を開始するためのさまざまなオプションを見ていくことができます。
オプション 1: Amazon EMR コンソールから
- [Amazon EMR コンソール] で [クラスタの作成] を選択します。
- クラスタの作成 – クイックオプション で、EMR リリース 10.0 またはそれ以降を選択します。
- アプリケーションとして Presto を選択します。
- AWS Glue データカタログの設定 の下で、[Presto の表のメタデータのメタデータに使用] を選択します。
オプション 2: AWS CLI から
- 以下に示されるとおりに分類の構成を作成し、それを JSON ファイル (presto-emr-config.json) として保存します。
- Create the cluster using the AWS CLI as follows:
Amazon EMR の Presto でのクエリの実行
Presto で Amazon EMR クラスタをセットアップした後で、AWS Glue データカタログがデフォルトの「hive」カタログを通して選択できます。Hive と Glue メタストアの間で変更するためには、手作業で hive.properties を入力して、Presto サーバーを再起動する必要があります。SSH を使用して、EMR クラスタでマスタノードに接続して、クエリを対話形式で実行し始めるために Presto CLI を実行します。
数行をサンプルとして示すために、簡単なクエリで始めます。
このクエリは次のいくつかのサンプル行を示します。

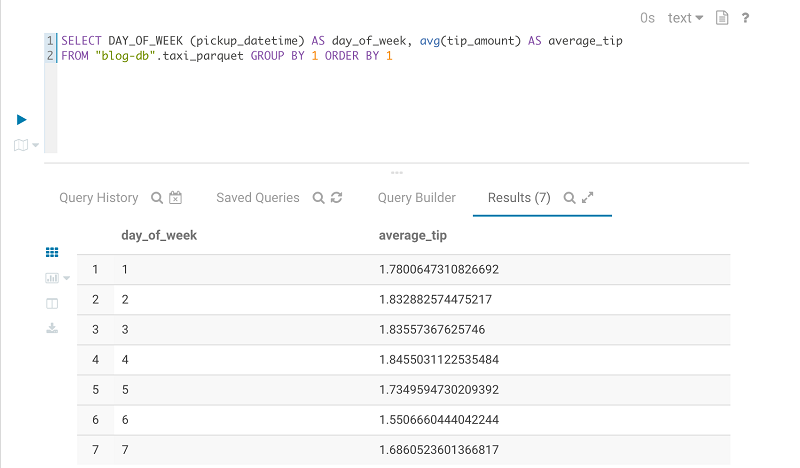
タクシーデータセットの Parquet バージョンで 1 日の毎時間、1 か月の毎日に平均料金のトリップをクエリします。
以下の画像は、結果を示します。

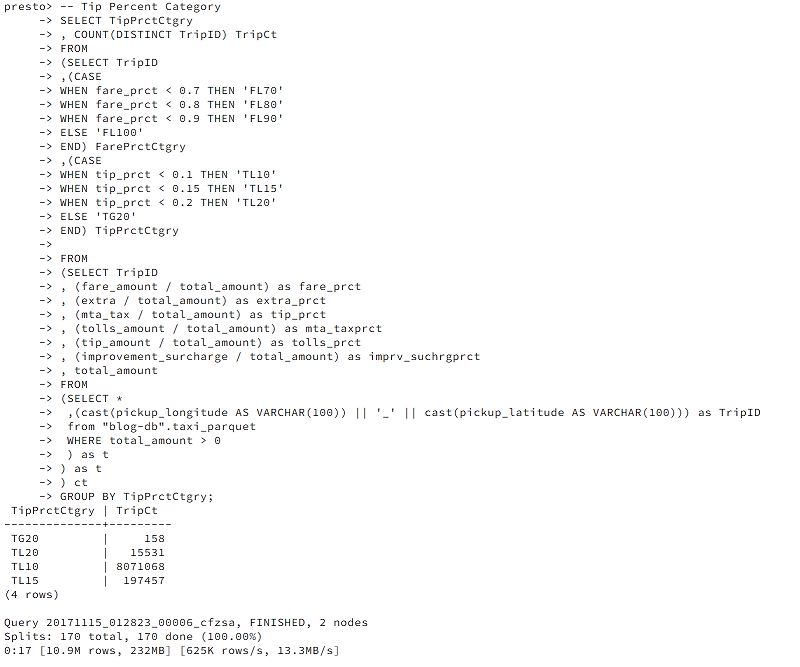
さらに興味深いことは、次のように、10%、15%、またはそれ以上のパーセンテージの範囲でチップを与えた旅行の回数を計算することができます。
結果は次のようになります。
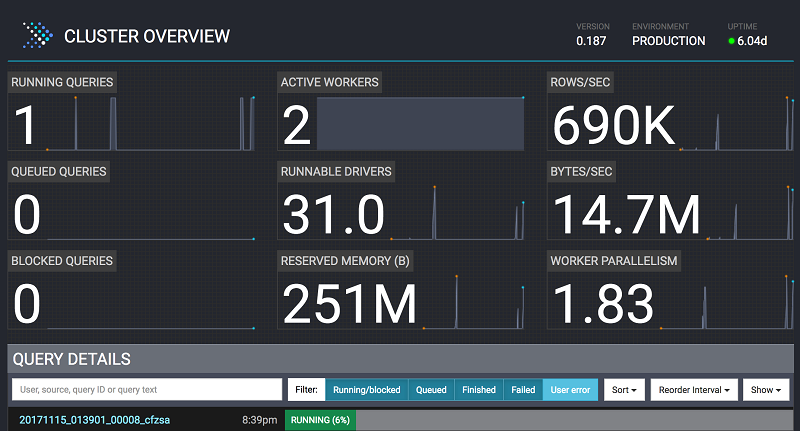
前述のクエリが実行されている間、Amazon EMR の Presto の Web インターフェイス(<http://master-public-dns-name:8889/)に移動します。ここで、アクティブなワーカーノード、1 秒間に読み込まれる行数、予約されているメモリ、および並行性などのクエリメトリックを見ることができます。
Hue の Presto エディターでのクエリの実行
Amazon EMR の開始で Hue をインストールした場合、Hue の Presto エディターでクエリを実行することもできます。Amazon EMR クラスタコンソールで、[Web 接続の有効化] を選択し、Hue と Zeppelin の Web インターフェイスにアクセスするための指示に従います。

Web 接続が有効になった後で、Hue リンクを選択して、Web インターフェイスを開きます。ログイン画面で、あなたが初めてログインした管理者である場合、ユーザー名とパスワードを入力して、Hue スーパーユーザーアカウントを作成します。次に、[アカウントの作成] を選択します。そうしない場合は、ユーザー名とパスワードを入力して、[アカウントの作成] を選択するか、管理者が指定する資格情報を入力します。

メニューから Presto エディターを選択します。Presto クエリを AWS Glue データカタログの表に対して実行できます。
結論
Amazon EMR のアプリケーションの共有データカタログを持つことで、探索、ガバナンス、監査機能、コラボレーションなど、組織が今日直面しているデータ関連の課題が軽減されます。この記事では、AWS Glue データカタログが Amazon EMR の Presto の表のメタデータの探索可能性と管理性にどのように対応しているかを調べました。さあ、やってみましょう。このソリューションを試してみてのご感想をぜひシェアしてください!
![]()
その他の参考資料
この記事が役に立った場合は、「Custom Log Presto Query Events on Amazon EMR for Auditing and Performance Insights」および「Build a Multi-Tenant Amazon EMR Cluster with Kerberos, Microsoft Active Directory Integration and EMRFS Authorization」を参照してください。

著者について
 Radhika Ravirala はアマゾン ウェブ サービスのソリューションアーキテクトで、そこで彼女はお客様の AWS プラットフォームでの分散型ビッグデータアプリケーションの作成を支援しています。クラウドに関わる前に、彼女はシリコンバレーのテクノロジー企業でソフトウェアエンジニア件デザイナーとして働きました。彼女はサンノゼ州立大学のコンピューターサイエンスの修士号を保持しています。
Radhika Ravirala はアマゾン ウェブ サービスのソリューションアーキテクトで、そこで彼女はお客様の AWS プラットフォームでの分散型ビッグデータアプリケーションの作成を支援しています。クラウドに関わる前に、彼女はシリコンバレーのテクノロジー企業でソフトウェアエンジニア件デザイナーとして働きました。彼女はサンノゼ州立大学のコンピューターサイエンスの修士号を保持しています。