Amazon Web Services ブログ
Amazon SageMaker Ground Truth でラベル付けしたデータセットを使用して、モデルを簡単にトレーニングする
データサイエンティストや開発者は、Amazon SageMaker Ground Truth でラベル付けされたデータセットによって機械学習モデルを簡単にトレーニングすることができます。Amazon SageMaker のトレーニングは、AWS マネジメントコンソールと Amazon SageMaker Python SDK API の両方を通じた入力として拡張マニフェスト形式で作成されたラベル付きデータセットを受け入れるようになりました。
先月の AWS re:Invent の期間中に、人間のラベル付け作業者のパブリックワークフォースならびにプライベートワークフォースを支援する機械学習を使用して、ラベル作成コストを最大 70% 節約し、正確なトレーニングデータセットを構築できる Amazon SageMaker Ground Truth を開始しました。ラベル付きデータセットは、それぞれの入力データセットオブジェクトを、ラベルなどの追加のメタデータを使用してファイル内でインライン展開する拡張マニフェストファイル形式で作成されます。以前は、拡張されたデータセットでモデルをトレーニングするために、低レベルの AWS SDK API しか使用できませんでした。本日から、Amazon SageMaker コンソールですばやく簡単に数回クリックするか、ハイレベルの Amazon SageMaker Python SDK を使用して 1 行の API をコールすることで、そうしたトレーニングをすばやく簡単に実行できるようになります。
さらに、 モデルを Amazon SageMaker のパイプモードを使用してトレーニングすることができます。このモードは、Amazon Simple Storage Service (S3) から Amazon SageMaker にデータがストリーミングされる速度を大幅に高速化するので、トレーニングジョブが早く始まり、素早く完了し、 Amazon SageMaker での機械学習モデルのトレーニングにかかる全体的なコストを削減できます。
それでは、例を詳しく見てみましょう。この例では、3,548 枚の街角の画像からなる CBCL StreetScenes データセットを使用しています。以前のブログ記事で、Amazon SageMaker Ground Truth を使用して、画像内のすべての車に境界ボックスを描画するワークフォースを管理し、Amazon SageMaker の物体検出モデルをトレーニングするためにラベル付きデータセットを作成する方法の例を紹介しました。ここでは、Amazon SageMaker でそのようなモデルをトレーニングする方法を紹介します。
ステップ 1: ラベル付きデータセットを調べる
ラベル付きデータセットは、拡張マニフェストファイル形式で作成されます。拡張マニフェストファイルとは、JSON ライン形式のファイルです。これは、ファイル内の各行が完全な JSON オブジェクトであり、その後に改行セパレータが続くことを意味します。それぞれの JSON オブジェクトには、画像ファイルの Amazon S3 URI とそのラベルが含まれています。ラベルは、画像内のそれぞれの車の周囲の境界ボックスの座標です。以下は、4 台の車でラベル付けされた画像の拡張マニフェストファイルの JSON オブジェクトの例です。

SSDB00004.JPG
拡張マニフェストファイルの JSON オブジェクトは次のとおりです。見やすくするために表示をフォーマットしました。拡張マニフェストファイルでは、これは JSON オブジェクトとして 1 行に表示されます。
ここで source-ref は画像ファイルの Amazon S3 URI です。sthakur-groundtruth-demo (最初にマニフェストファイルを作成した Amazon SageMaker Ground Truth のラベル付けジョブの名前にちなんで名付けられました) はラベルのリストであることに注意してください。ラベルは、人間の作業者によってラベル付けされた 4 台の車の座標で構成されています。
ステップ 2: Amazon SageMaker トレーニングジョブの作成
次は、ステップ 1 の拡張マニフェストファイルを入力として使用する Amazon SageMaker 物体検出モデルをトレーニングします。
Amazon SageMaker コンソールを使用する
Amazon SageMaker コンソールの左側のナビゲーションペインで [Training jobs] を選択してから、[Create training job] を選択します。学習アルゴリズム、クラスターの仕様、ハイパーパラメーターなどのモデルのトレーニング設定を選択した後、トレーニングデータセットを取得するための入力データチャネルを入力するセクションまでスクロールダウンします。
AugmentedManifestFile として、「S3 data type」を選択します。ステップ 1 のマニフェストファイルの Amazon S3 での場所を指定します。また、物体検出アルゴリズムに使用させる、拡張マニフェストファイルからの JSON 属性の名前も指定します。ここでは、モデルをトレーニングするために、ステップ 1 で説明した source-ref と sthakur-groundtruth-demo の 2 つの属性しか必要としません。
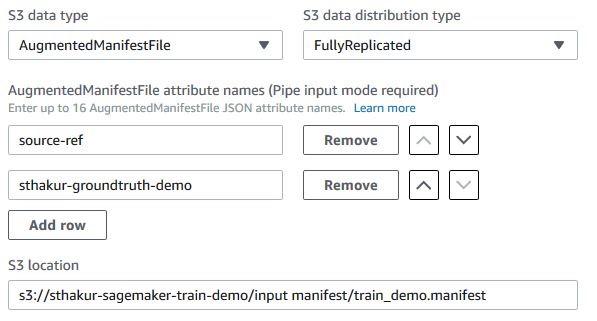
拡張マニフェストファイルの JSON オブジェクトは、Amazon SageMaker パイプモードを使用して順序付けられた方法でストリーミングされるため、入力データストリームでアルゴリズムが見つけると予想される属性名の順番を慎重に選択する必要があります。それぞれの属性名の横にある上下の矢印ボタンを使用して、順番を選択します。
ここではトレーニングデータセットを取得するための入力データチャネルを作成する方法を示していますが、物体検出アルゴリズムでは検証データセット用の入力データチャネルも必要です。検証データセットを準備する 1 つの方法は、ラベル付き画像のサブセットを保持し、検証セット用に別の拡張マニフェストファイルを作成することです。次に、新しい拡張マニフェストファイルの Amazon S3 URI を検証チャネルへの入力として使用して、このステップで説明したのとまったく同じ方法でチャネルを定義することができます。
Amazon SageMaker Python SDK の使用
Amazon SageMaker の Estimator を使用して、物体検出モデルをトレーニングします。
ここで、Pipe として input_mode を、AugmentedManifestFile として s3_data_type を選択し、SageMaker の estimator の fit ルーチンを使用してモデルをトレーニングする前に attribute_names のシーケンスを指定していることに注意してください。
拡張マニフェスト形式を使用することのその他の利点
Amazon SageMaker は、Amazon S3 に保存されたデータセットでのモデルのトレーニング用に常に従来のマニフェストファイルをサポートしてきました。マニフェストファイルは、モデルをトレーニングするために Amazon SageMaker にダウンロードする必要のあるデータオブジェクトの Amazon S3 キー名プレフィックスのリストを提供するだけです。
たとえば、これがマニフェストファイルです。
以下の Amazon S3 URI と一致します。
視覚認識アルゴリズムなどの学習アルゴリズムの入力データチャネルの指定でこうした従来の手法を使用すると、Amazon SageMaker で 2 つの入力データチャネルを指定する必要があります。入力データ (画像) 用とラベル用です。拡張マニフェストを使用すると、データとそのラベルを 1 つのマニフェストファイルに保存できるので、2 つのチャネルは不要になります。また、複数のチャネルにわたってラベルとデータオブジェクトを照合するアルゴリズムコードの不要な複雑さも排除できます。
たとえば、このマニフェストファイルは、S3 URI を JSON ライン形式に再構成し、ラベルをインラインで追加することによって、拡張マニフェストとして簡単に表現できます。
モデルのトレーニング中に、attribute_names=['source-ref','label'] と設定します。
さらに、拡張マニフェストファイルは Amazon SageMaker パイプモードを使用します。つまり、Amazon S3 から Amazon SageMaker のトレーニングインスタンスへのハイスループットのデータストリーミングの恩恵を受けることができます。ここに、パイプモードを使用してデータの消費を開始する学習アルゴリズムの変更点を説明するブログ記事があります。
さらに多くの例と開発者用サポートを利用して開始する
拡張マニフェストファイル形式のラベル付きデータセットを使用して、Amazon SageMaker でモデルをトレーニングする方法の例を示しました。また、ステップバイステップの AWS SDK 体験を提供するサンプルノートブックを試すこともできます。開発者ガイドで追加のサンプルを確認したり、開発者フォーラムに質問を投稿することもできます。
著者について
 Sumit Thakurは AWS Machine Learning プラットホームのシニアプロダクトマネージャーで、クラウドで顧客が容易にMachine learningできる製品を開発することが好きです。彼は、Amazon SageMaker と AWS Deep Learning AMI のプロダクトマネージャーです。余暇には、自然との触れ合いや SF テレビドラマの視聴を楽しんでいます。
Sumit Thakurは AWS Machine Learning プラットホームのシニアプロダクトマネージャーで、クラウドで顧客が容易にMachine learningできる製品を開発することが好きです。彼は、Amazon SageMaker と AWS Deep Learning AMI のプロダクトマネージャーです。余暇には、自然との触れ合いや SF テレビドラマの視聴を楽しんでいます。