Amazon Web Services ブログ
Amazon Elasticsearch Service の使用を開始する: T シャツサイズのドメイン
Elasticsearch および Amazon Elasticsearch Service (Amazon ES) に関するこの導入シリーズへようこそ。今回および今後のブログ記事では、AWS で Elasticsearch の使用を開始するために必要な基本情報を紹介します。
概要
Amazon Elasticsearch Service ドメインを初めて起動するときには、インスタンスタイプとインスタンス数の設定、専用マスターを使用するかどうかの決定、ゾーン認識の有効化、およびストレージの設定が必要です。このシリーズでは、インスタンス数の決定のためにストレージをガイドラインとして使用することについて説明してきましたが、他のパラメータについては説明したことがありませんでした。本記事では、ログ分析ワークロードの T シャツサイズに基づいて推奨事項を提供します。
ログ分析およびストリーミングのワークロードの特性
ストリーミングワークロードに Amazon ES を使用する場合、1 つ以上のソースから Amazon ES にデータを送信します。Amazon ES は定義した 1 つまたは複数のインデックスにお客様のデータ (より正確には、お客様のデータのインデックス) を保存します。さらに、データのタイムスライスと保持期間を定義して、ドメインでのライフサイクルを管理します。
次の図では、データのストリームを生成するデータソースが 1 つあります。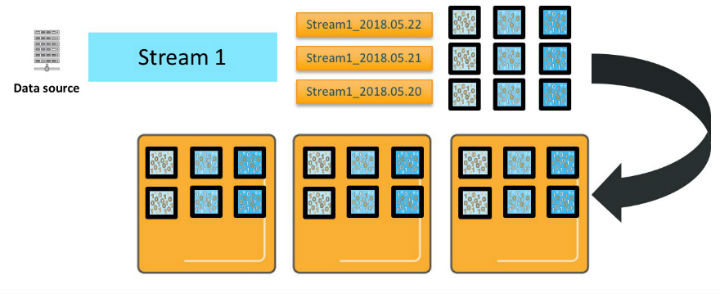
そのデータのストリームを Amazon ES に送信する際に、Stream1_2018.05.21、Stream1_2018.05.22 などの名前の 1 日ごとのインデックスを作成します。Stream1_ をインデックスパターンと呼びます。この図では、これらの各インデックスに対して 3 つのプライマリシャードを表示しています。シャードは、各プライマリシャードに 1 つあるレプリカと共に、3 つの Amazon ES データインスタンスにデプロイされます。(分かりやすいように、図には示していませんが、プライマリとレプリカが別のインスタンスにあるようにシャードがデプロイされます。)
Amazon Elasticsearch Service が更新処理を行うと、その更新は、新規または更新されたドキュメントを受信しているすべてのプライマリおよびレプリカに送信されます。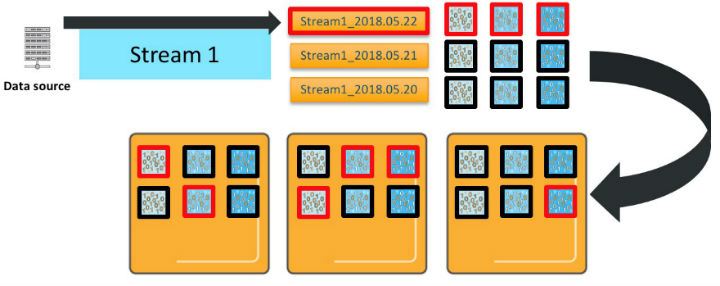
Elasticsearch による更新処理方法にはいくつかの重要な特性があります。第一に、各インデックスパターンは、プライマリ数 * レプリカ数 * 保持日数の合計シャードをデプロイします。第二に、このインデックスパターンに 3 つのインデックスがあっても、タイムスライスは、これらのインデックスの内の 1 つ、つまりそのインデックスパターンのアクティブなインデックスにのみ新規ドキュメントが送信されることを意味します。第三に、_bulk データを送信していてそれがランダムに分散されると仮定すると、そのインデックスのすべてのシャードが更新の受信および書き込みを行います。したがって、このインデックスパターンの場合、単一の _bulk リクエストの処理に 6 つの vCPU が必要です。
同様に、Elasticsearch は関連するインデックスのシャード全体にクエリを分散します。全 3 日にわたるこのインデックスパターンにクエリを実行する場合、18 のシャードを使用し、リクエストの処理に 18 の vCPU が必要です。
もっと多くのデータストリームとインデックスパターンを組み込む場合、図はさらに複雑になります。上図が示すように、追加の各データストリーム/インデックスパターンに対して、毎日のインデックスそれぞれにシャードをデプロイし、vCPU を使用してデプロイされたシャードに合わせてリクエストを処理します。複数のインデックスへの同時リクエストを作成する場合、関連するすべてのインデックスの各シャードがそれらのリクエストを処理する必要があります。
クラスターの容量
インデックスパターン数および同時リクエスト数が増加するので、クラスターのリソースをすぐに攻略できます。Elasticsearch には、リクエストをバッファしてこの同時需要を緩和する内部キューが含まれています。_cat/thread_pool API を使用することで、このキューを表示してその深さをモニタリングすることができます。
また、更新およびクエリを処理する時間がその更新およびクエリのコンテンツに応じて異なるという複雑な側面もあります。リクエストを受信すると、送信時の速度でキューに入力されます。そして、使用可能な vCPU、各リクエストにかかる時間、およびそのリクエストの処理時間によって決まる速度で出力します。リクエストが 1 秒ではなく 1 ミリ秒でクリアされれば、より多くのリクエストをインターリーブすることができます。このトピックに関する詳細な会話については、本記事では説明しません。_nodes/stats Elasticsearch API を使用して、お使いの CPU への平均負荷をモニタリングすることができます。
クエリの深さが増加していると表示された場合、「警告」エリアに移動していて、クラスターが負荷を処理しています。ただしそのまま続行すると、使用可能なキューを超え、CPU を追加するためのスケーリングが必要となる場合があります。負荷の増加が表示され始めた場合も、キューの深さの増加と相関関係があるので、「警告」エリアにいることになり、スケーリングを考慮する必要があります。
推奨事項
次の表は、ソースデータの量、必要なストレージ、ならびにアクティブなシャードおよび合計シャードに基づいてインスタンスを提案しています。すべてのサイズ設定の推奨事項と同様に、これらのガイドラインは開始点を表します。これを試して、お客様の Amazon ES ドメインをモニタリングし、必要に応じて調整してください。
| T シャツ
サイズ |
データ
(1 日あたり) |
必要なストレージ | アクティブなシャード
(最大) |
合計シャード
(最大) |
インスタンス |
|---|---|---|---|---|---|
| X スモール | 10 GB | 177 GB | 4
@ 50 GB |
300 | 2x M4/R4.large データ
3x m3.medium マスター |
| スモール | 100 GB | 1.7 TB | 8
@ 50 GB |
600 | 4x M4/R4.xlarge データ
3x m3.medium マスター |
| ミディアム | 500 GB | 8.5 TB | 30
@ 50 GB |
3000 | 6x I3.2xlarge データ
3x C4.large マスター |
| ラージ | 1 TB | 17.7 TB | 60
@ 50 GB |
3000 | 6x I3.4xlarge データ
3x C4.large マスター |
| X ラージ | 10 TB | 177.1 TB | 600
@ 50 GB |
5,000 | 30x I3.8xlarge データ
3x C4.2xlarge マスター |
| ヒュージ | 80 TB | 1.288 PB | 3400
@ 50 GB |
25,000 | 85x I3.16xlarge データ
3x C4.4xlarge マスター |
注意: この表は、多くの仮定に基づくガイドラインを表します。お客様のワークロードとは異なりますので、実際のニーズはこれらの推奨事項とは異なります。必ずデプロイ、モニタリング、および調整を行ってください。
最小の X スモールのユースケースで取り扱うデータの範囲は、単一データストリームから単一インデックスパターンへの 1 日あたり 10 GB 以下のデータです。スモールのユースケースで取り扱うデータの範囲は、1 日あたり 10 から 100 GB、ミディアムのユースケースでは、100 から 500 GB、などとなります。最大のヒュージでは、Amazon Elasticsearch Service は合計で 1 ペタバイトを超える保管データに対して、1 つまたは多数のインデックスパターン全体で 1 日あたり最大 80 TB のデータをサポートします。X ラージおよびヒュージサイズのワークロードの場合、制限の引き上げを要求して、ドメインごとのデータインスタンスを既定の 20 より増やす必要があります。
必要なストレージを算出するために、1 日ごとのデータを、ソースとインデックスの想定比率 1.1 と乗算し、レプリカが 1 つなので 2 倍し、保持期間が 7 日と想定して 7 と乗算しました。
必要なストレージ = ソースのバイト数 * 1.1 * 2 * 7 * 1.15
(この推奨例では、Elasticsearch の cluster.routing.allocation.disk.watermark.low にヒットしないようにするため、オーバーヘッド用にストレージを以前のガイダンスよりも 15% 増加しています。)
CPU のニーズを考慮するため、アクティブなシャードの最大数のターゲットの列、およびシャードの合計の最大数の列を追加しました。お客様のスループットおよびレイテンシーはワークロードによって大幅に異なりますが、スケールの初期点として、アクティブなシャード (最大) 列の値を使用する必要があります。この列の値は、推奨されるインスタンス全体でデプロイされる vCPU の数によって決定されます。最小サイズでは、アクティブなシャードと CPU の比率は 1:1 です。より大きなスケールでは、より多くの困難なクラスタータスクを可能にするために、インスタンスごとのシャードを少なくするように推奨しました。
スケールを計画する場合、最大のアクティブなシャードおよびそれに応じたスケールにインデックスパターンの数をマッピングすることができます。単一のインデックスパターンを実行する場合、更新処理用のアクティブなシャードの数はプライマリの数とレプリカの数の合計です。2 つ以上のインデックスパターンを実行する場合、アクティブなインデックス全体のアクティブなシャードの合計です。
アクティブなシャード列はシャードのサイズ設定の推奨でもあります。ディスクでそのサイズが指定されているインデックスに対してプライマリシャードの数を設定することで、シャードのサイズ設定をコントロールします。詳細については、シャード数の算出方法の記事を参照してください。シャードの最大サイズ 50 GB に関する Elastic の推奨事項に同意します。
合計シャードは、アクティブなインデックスおよび古いインデックスを含む、クラスター内に保存されたすべてのインデックスのすべてのプライマリシャードおよびレプリカシャードの合計にまつわるガイドラインとなります。これを使用して、保持時間および全体的なストレージ戦略を計画します。合計シャード列の値は、Java 仮想マシン (JVM) に割り当てられた基盤となる RAM の量によって決定されます。Elastic のガイダンスに従って、JVM に割り当てられる RAM を 1 GB あたり最大 25 シャードとすることを推奨します。
最後の列は、お客様の Amazon Elasticsearch Service ドメインにおけるデータおよびマスターインスタンスのインスタンス数およびインスタンスタイプを提案しています。最小のユースケース以外のすべてで、 I3 インスタンスを推奨します。0.39 USD/1 GB 時間のストレージ (us-east-1) では、コストでこのインスタンスに勝つことは困難です。その NVMe SSD、ディスクとネットワークの帯域幅、RAM サイズ、および CPU 数では、パフォーマンスでこれらのインスタンスに勝つことも困難です。例外は最小サイズの場合で、より小さな EBS ボリュームを使用し、ストレージのニーズを最適化して、コストを減らすことができます。
結論
本記事のガイドラインを開始点として使用します。ワークロードは独自の方法で動作し、個別にスケールします。常にモニタリングを行い、適切にスケールします。同時に、これまでに説明してきたこれらの推奨事項の構築方法を使用して希望の補間および設定を行い、適切に開始することができます。
著者について
 Jon Handler (@_searchgeek) は、検索テクノロジーに特化した AWS ソリューションアーキテクトです。 AWS を使用する際にソリューションの価値を向上させる手助けとなるために、当社の顧客と協力してデータベースプロジェクト上の指導や技術支援を行っています。
Jon Handler (@_searchgeek) は、検索テクノロジーに特化した AWS ソリューションアーキテクトです。 AWS を使用する際にソリューションの価値を向上させる手助けとなるために、当社の顧客と協力してデータベースプロジェクト上の指導や技術支援を行っています。