Amazon Web Services ブログ
Amazon Neptune を使った投資相関性のグラフ表示
Amazon Neptune を使い投資相関性のグラフを保存しクエリすると、新たな視野で関連性を分析できます。EDGAR (Electronic Data Gathering Analysis and Retrieval) は、米国証券取引委員会 (SEC) が提供するパブリックなオンラインデータベースです。この EDGAR は、法律により SEC への書類提出が義務付けられた法人向けに、データ収集、評価、インデックス付、受理、書類転送などを自動で処理するものです。これらの法人には、登録投資アドバイザー、銀行、保険会社、ヘッジファンドなどや、これらの顧客向けに投資を裁量するその他のグループなど、投資管理を行う企業が含まれます。
こういった関連の書類には、次に挙げるような多種のデータナゲットが記載されます。
- その債権を公共で販売したことのある、株式会社や事業に関するデータ。
- 以下を含む役員報酬:
- その企業の年ごとの委任勧誘状。
- その企業のフォーム 10-K 年次報告書。
- その企業が有価証券を公開で販売するために提出した有価証券発行届出書。
- 米国内で、1 億 USD 以上の試算を長期にわたり保有および管理している企業内の投資マネージャーからの、投資ポジションレベルに関する公開書類。このマネージャーが保持するポートフォリオ内にある、すべての米国内公開済みの株式有価証券を含み、保有率、対象企業の符丁 (ティッカーシンボル)、株式発行者名などを詳細に記載する。
これらのデータナゲットは、各事業体からの提出ごとに、個別な事象として保持されます。ただ、EDGAR では、これらすべてのイベントを 1 つに結び付け、関連性やパターンを表示することはできません。
今回の記事では、EDGAR からの資料を Neptune 内で結合および処理し、その関連性を明らかにしながら、他のイベントでも繰り返し利用可能なモデルを作成するための方法をご紹介します。
データベースオプション
現代の技術者には、データ処理に関する多くの選択肢が与えられています。次の表に、一般的なデータカテゴリーとユースケースのいくつかを示します。
| リレーショナル | キーと値 | ドキュメント | インメモリー | グラフ | 時系列 | |
| 参照整合性 | 高スループット | 任意の属性での、ドキュメント保存と高速アクセスによるクエリ | ミリ秒のレイテンシーでのキーによるクエリ | 各データの関連性の素早く簡単な生成とその間の移動 | 時間的に連続したデータの収集、保存、および処理 | |
| ACID トランザクション | 低レイテンシー
読み出しと書き込み |
|||||
| スキーマオンライト | 無制限のスケーリング | |||||
| 一般的なユースケース | リフトアンドシフト
ERP、CRM、金融 |
リアルタイムでの入札、ショッピングカート、ソーシャルプロダクトカタログ、顧客嗜好 | コンテンツ管理
パーソナライゼーション、モバイル |
スコアボード、リアルタイム分析
キャッシング |
不正検出
ソーシャルネットワーク レコメンデーションエンジン |
IoT アプリケーション
イベントトラッキング |
この記事では、Amazon DynamoDB と Neptune という 2 つのデータベースを使用して、データベースワークロードを処理していきます。データロードの処理では、DynamoDB が調整役を務めます。DynamoDB は、1 桁のミリ秒のパフォーマンスを実現する、キーと値型のドキュメントデータベースです。これは、マルチリージョンかつマルチマスターであり、セキュリティ、バックアップ、リストアの機能が組み込まれ、またメモリ内キャッシュも備えた、高い耐久性を持つフルマネージド型データベースです。こういった特性は、 insert/select オペレーションでの高速アクセスからの要件を満たし、また、ストリーミング機能による AWS Lambda 関数のトリガーにも対応しています。
Neptune は高パフォーマンスなグラフデータベースで、高速かつ信頼性の高い完全マネージド型であり、密に接続されたデータセット同士を処理できます。数十億におよぶ関係性を保存し、そのグラフを 1 桁ミリ秒のレイテンシーでクエリするため最適化された、専用データベースです。Neptune では、普及したグラフモデルである Property Graph と W3C の Resource Description Framework (RDF) をサポートしており、それら向けのクエリ言語である、Apache TinkerPop Gremlin と SPARQL にも対応しています。
SPARQL Protocol と RDF Query Language は、RDF で保存されたデータの取得と操作を行うための、RDF クエリ言語 (データベース向けのセマンティッククエリ言語) です。
Gremlin は、Apache TinkerPop のグラフ横断言語です。これは機能的なデータフロー言語で、アプリケーション内にあるプロパティグラフ上での複雑な横断 (もしくはクエリ) を、簡潔に記述することができます。Gremlin 内で記述する、すべての横断は、いくつかの (入れ子になる場合もある) ステップによるシーケンスで構成されます。各ステップは、データストリーム上のアトミックオペレーションとして働きます。
この情報は、ノード (データエンティティ) 、エッジ (関連) 、プロパティ として解釈される主要要素として、詳細に分解することができます。
次の図は、2 つのノードを持つ Neptune モデルを示しています。
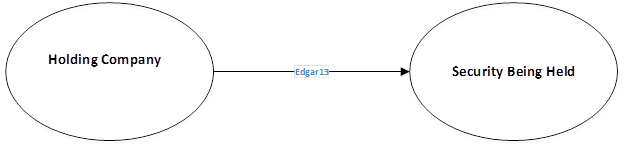
この中のノードの 1 つは有価証券そのものを表し、もう 1 つはそれを保有する企業を示しています。この関係性は、証券保有の属性を示すEDGAR フォームと同じです。
SEC EDGAR レポジトリでは、各企業の経営陣が提出した投資ポジションに関する公開書類が保存されており、それぞれの企業での株式保有率の増減、あるいは受け取り分が示されています。この情報は、次のような 3 ノードモデルに拡張できます。

ここには、証券を保有する企業、その証券自体、そして利益が上がっている保有分が表示されています。この基本的なモデルには、個別証券の動き、譲渡分、そして内部的な活動が、大枠で反映されています。
これには、ソーシャルメディア、新規ノード、業界内のイベントなどを追加し、モデルをさらに拡張できます。次の図では、5 ノードモデルを示しています。
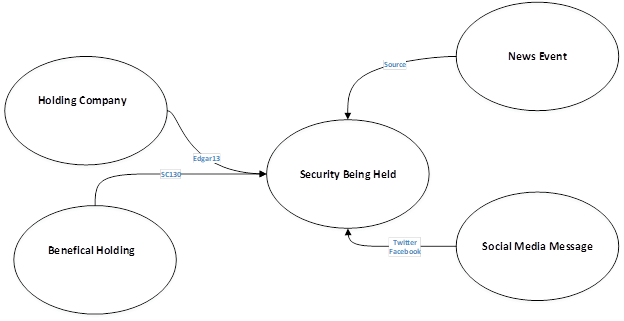
ここには、証券の保有企業、証券自体、利益をあげている保有分、ソーシャルメディア、そしてニュースイベントに関するノードが含まれています。これらノード間の相関は、EDGAR からの資料、ニュースソース、あるいはソーシャルメディアの発信者から得たものです。
このグラフの図式では、各データエレメント内の接続と、その交差状況から得られる情報を見て、何が分かるかを表しています。この情報からは、証券の大まかなポジションと、その証券の大手保有者である複数企業の間で共通に存在する、下層的な保有関係についてを知ることができます。
EDGAR データの利用
証券の保有状況を示す SEC EDGAR のデータを公開させるには、プロセスを実装する必要があります。今回の記事では、個別事業者における保有状況のみを扱っていきます。このシステムは、Lambda、Amazon SQS、DynamoDB、Neptune を使い実現しています。1 つのステップ関数が、全体のプロセスをトリガーします。次の図は、そのプロセスを示しています。
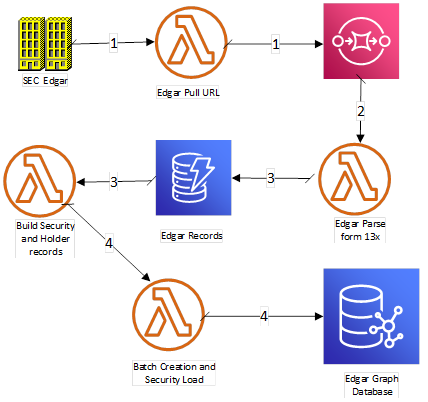
EDGAR のサイトに AWS Lambda 関数がアタッチされているのがわかります。ステップ 1 では、特定の年次の調査したい四半期から、このサービスがマスターインデックスを取得します。マスターインデックスには、証券保有関係のドキュメントに関するすべての URL が包含されています。この情報は解析された後に SQS キューの中に挿入されます。
ステップ 2 では、Amazon SQS キューにレコードが入力され、これにより、必要なボリューム量に合わせスケーリングする Lambda 関数がトリガーされます。この Lambda 関数は、各 EDGAR ドキュメントを解析し、証券を保有する企業と保有されている証券に関するデータが抽出されます。これらの個別レコードは、DynamoDB テーブル (今回、このテーブルは Edgarrecord となっています) 内に AWS Lambda により挿入されます。
ステップ 3 では、Amazon DynamoDB が テーブル Edgarrecord に対しストリーミングを行います。同時に、AWS Lambda 関数をトリガーして、各レコードの処理と、Neptune 内の各エッジとノードにフォーマットを合わせた、新しいレコードの作成を行います。
このステップの関数には、SQS キューと DynamoDB ストリーム上の全処理が完了したことを確認するための、AWS Lambda 関数が 1 つ含まれています。ステップ 4 では、上記の確認完了により最終的な Lambda 関数がトリガーされます。これにより、DynamoDB テーブルの全レコードが処理され、Neptune データベースがロードされます。
その結果、SEC の情報を基にしたグラフデータベースが得られます。これには、各証券の関係と、その大手保有者である法人との相関関係が記録されています。次の図に、この手法で作成することができる、グラフデータベースの概観を示します。
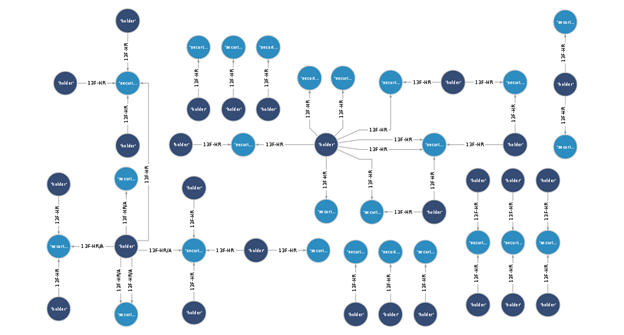
データベースに全データがロードされたら、Gremlin クエリ―を使い、その中を調べることができます。これらのクエリの詳細については、GitHub リポジトリをご参照ください。ここにあるノートブックのサンプルデータには、現在もしくは過去のものに関しても SEC EDGAR が保持する関係性は一切反映されていません。
データロードの際に作成される頂点の数は、次のコードにより指定することができます。
作成されるエッジの数は、次のコードにより指定します。
頂点上のエッジの数を指定するには、次のコードを入力します。
まとめ
SEC EDGAR データベースには、豊富な金融情報が保存されています。Neptune のグラフモデルを使うことによりその関係性が収録でき、共通性に基づきマッピングすることで、SEC EDGAR を使っている事業者間にある相関性についての洞察を得ることができます。
パブリックなデータからモデルを作成するのは、ブロックを積み上げるのと一緒です。これを拡張することで、事象同士のつながり、証券に関するマーケットでのイベントや経済的な出来事を表示できるようになります。Amazon Neptune GitHub レポジトリ には、サンプルデータを同梱したノートブックをご用意しています。
著者について

Lawrence Verdi はアマゾン ウェブ サービスのシニアパートナーソリューションアーキテクトです。