Amazon Web Services ブログ
OracleDBからPostgreSQLへの移行
Knievel Co は、アマゾン ウェブ サービスのデータベースエンジニアです。
このブログ記事では、Oracle データベースを PostgreSQL に移行する方法の概要について説明します。データベース移行の2つの主要部分は、スキーマの変換とデータの複製です。)AWS スキーマ変換ツール (AWS SCT) と AWS Database Migration Service (AWS DMS) を使用して、これら 2 つの部分に取り組む方法について説明します。
SCT と DMSについて説明する前に、予備的な手順を実行する必要があります。これらは、すべての移行に役立つことが判明しています。移行を容易にする方法の 1 つは、移行の前に、通常更新フェーズと呼ばれるものを行うことです。このフェーズでは、Oracle データベース内のオブジェクトのインベントリを作成し、いくつかの決定を下します。
最初に、不要になったオブジェクトを削除します。オブジェクトの移行にかかる時間は誰も気にかけませんが、無駄にしないでください。また、不要になった履歴データを削除することもできます。一時的なテーブルや過去のメンテナンス時のテーブルのバックアップコピーなど、不要なデータを複製するために時間を無駄にすることはありません。次に、LOB、CLOB、LONG などに保存されているフラットファイルおよび長い文字列を Amazon S3 または Amazon Dynamo DB に移動します。このプロセスではクライアントソフトウェアの変更が必要となりますが、データベースが簡素化されサイズが削減されることで、システム全体がより効率的になります。最後に、PL/SQL パッケージとプロシージャを移動します。特にビジネスロジックを含むものをクライアントソフトウェアに戻してみます。これらのオブジェクトは、SCT が変換できない場合は手動で変更する必要があります。
次の手順は、異なるデータベースエンジン (この場合は Oracle から PostgreSQL へ) に移行するための手順です。別のプラットフォームに移動していない場合は、データベースを移動するためのより適切なネイティブツールやその他のテクニックがあります。
- ターゲットデータベースでスキーマを作成します。
- ターゲットデータベースの外部キーとセカンダリインデックスを削除し、トリガーを無効にします。
- データを複製するためのDMSタスクを設定します (全ロードと変更データキャプチャ (CDC))。
- 全ロードフェーズが完了したらタスクを停止し、外部キーとセカンダリインデックスを再作成します。
- DMS タスクを有効にします。
- ツールとソフトウェアを移行し、トリガーを有効にします。
ターゲットデータベースでスキーマを作成します。
移行するスキーマを確認して、移行を開始します。このケースでは、AWS スキーマ変換ツール (AWS SCT) を使用して分析を実行します。アプリケーションを起動するときは、ソースが Oracle でターゲットが PostgreSQL となる新しいプロジェクトを作成する必要があります。再接続したら、左側で移行するスキーマの名前を選択します。スキーマ名を右クリックし、[スキーマの変換] を選択します。次に、[View / Assessment Report View] を選択します。
AWS SCT 評価レポートは、Oracle データベースを PostgreSQL に変換するために必要な作業の高レベルな概要を示します。以下に示しているのは、評価レポートの具体的な例です。
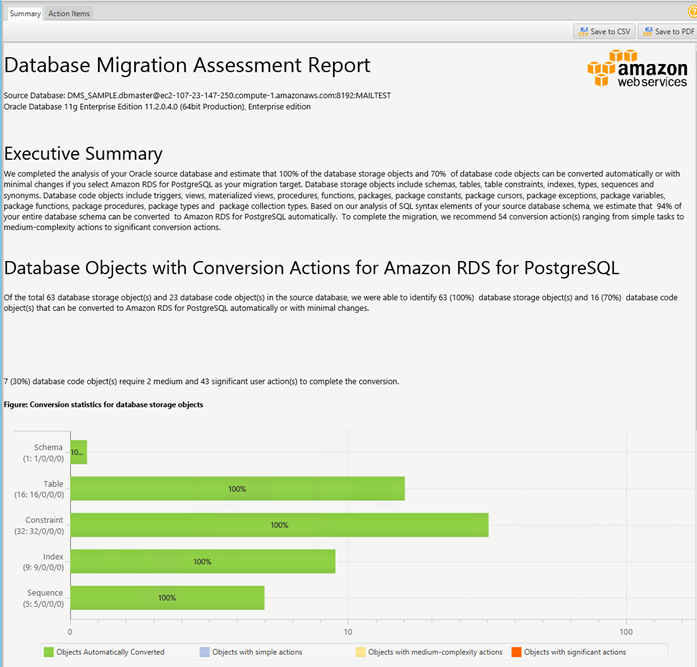
このレポートは、各オブジェクトタイプごとに手動で変換するために必要な手作業を示しています。一般的に、パッケージ、プロシージャ、関数には解決すべきいくつかの問題があります。AWS SCT では、これらのオブジェクトを修正する理由を説明し、その方法のヒントを示します。

スキーマが自動的に変換されない場合の、問題を解決するためのヒントを次に示します。
- ソースの Oracle データベースのオブジェクトを変更して、AWS SCT がそれらをターゲットの PostgreSQL に変換できるようにします。
- スキーマをそのまま変換し、AWT SCT によって生成されたスクリプトを手動で変更してから、それらをターゲットの PostgreSQL データベースに適用してみてください。
- 変換できないオブジェクトを無視して、機能を別の AWS サービスまたは同等のものに置き換えます。
スキーマの変換機能を改善すると、反復プロセスを経てレポートとスキーマを再生成できます。[Action Items] ビューには、変換プロセスを実行する際に生じる問題のリストが表示されます。変換されたスキーマの結果が満足のいくものであれば、それらをターゲットの PostgreSQL データベースに適用することができます。
ターゲットデータベースのスキーマを参照し、列のデータ型、オブジェクト名などを簡単ににチェックすることをお勧めします。ソースおよびターゲットのデータ型の詳細については、「AWS Database Migration Service リファレンス」を参照してください。 また、Oracle から PostgreSQL への変換であるため、オブジェクト名が Oracle では大文字で、PostgreSQL では小文字であることが問題となります。
外部キー制約とセカンダリインデックスを削除する。トリガーを無効にする
ターゲット上に必要なスキーマを揃えるするには、ソースから実際のデータを移行するためにスキーマを準備する必要があります。ここでは、AWS Database Migration Service (AWS DMS) を使用します。DMSには、全ロードと変更データキャプチャ (CDC) の 2 つのフェーズがあります。全ロードフェーズでは、テーブルは順不同でロードされます。したがって、ターゲットで制約を有効にすると、いくつかの外部キーで制約違反が発生します。また、全ロード時には表のレプリケーションが遅くなる可能性があるため、セカンダリインデックスを無効にする必要があります。これは、レコードがロードされるときにインデックスを維持する必要があるためです。
ターゲットの PostgreSQL データベースで、クエリを実行してデータベーステーブルの外部キー制約に DDL を生成し、出力を保存します。これを行うための多くのサンプルクエリをオンラインで見つけることができます。次のような情報が表示されます。これを実行すると、後で外部キー制約を再作成するための DDL が提供されます。
ALTER TABLE <テーブル名> ADD CONSTRAINT <制約名> FOREIGN KEY(キー列)REFERENCES <親テーブル名>(キー列)MATCH FULL;
同様に、DDL 生成クエリを実行して、ターゲットデータベース上のすべての外部キー制約を削除します。
ALTER TABLE <テーブル名> DROP CONSTRAINT <制約名>;
ここで、セカンダリインデックスについても同じことを行います。つまり、コマンドを作成し結果を生成してから、セカンダリインデックスを削除します。
次に、トリガーを無効にします。
ALTER TABLE <テーブル名> DISABLE TRIGGER ALL;
ID 列でシーケンスを使用する場合は、ターゲットでシーケンスを作成するときに、次の値をソースデータベースよりも高く設定することをお勧めします。十分なギャップを残して、移行カットオーバーの日付で値がソースのデータベースの値よりも高くなっていることを確認してください。このアプローチによって、移行後のシーケンス ID の競合が回避されます。
DMS タスクを設定してデータをレプリケートする
ターゲットの PostgreSQL データベースでスキーマの準備ができました。これでデータをレプリケートする準備が整いました。これは DMS が入る場所となります。DMS の素晴らしい点は、各テーブルのデータをレプリケートするのではなく、移行する準備ができるまで CDC モードでデータを最新の状態で保持することです。
ソース Oracle データベースの準備:
- Oracle ログインに必要な権限を確認します。
- DMS が Oracle ソースデータベースから変更を取得するために必要なサプリメンタルロギングを設定します。
- ソース Oracle データベースの準備の詳細については、DMS ドキュメントを参照してください。
AWS コンソールで DMS を起動します。最初に、レプリケーションインスタンスを作成する必要があります。レプリケーションインスタンスが DMS タスクを実行します。このインスタンスは、ソース Oracle データベースとターゲット PostgreSQL データベースの両方に接続する中間サーバーです。適切なサイズのサーバーを選択します。特に、複数のタスクの作成、多数のテーブルの移行、またはその両方を行う場合は、適切なサーバーを選択します。

次に、ソースデータベースのエンドポイントとターゲットデータベースのエンドポイントを作成します。Oracle データベースと PostgreSQL データベースの適切な接続情報をすべて入力します。各エンドポイントの作成が完了する前に、接続テストが成功した後で必ずスキーマの更新オプションを選択し、テストを実行 してください。
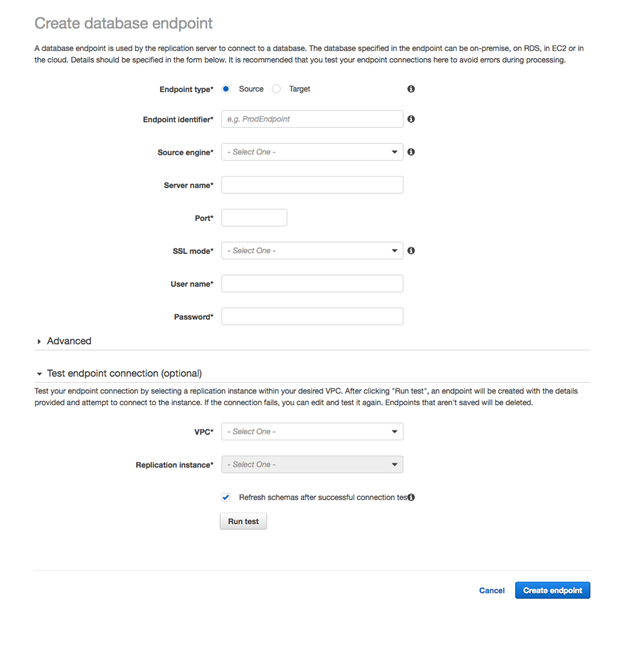
これで、タスクを作成する準備ができました。タスク名を入力し、作成したレプリケーションインスタンス、およびソースおよびターゲットエンドポイントを選択します。[移行タイプ] で、[既存データの移行と進行中の変更のレプリケート] を使用します。スキーマを事前に作成するためにAWS SCTを使用しているため、[ターゲットテーブル準備モード] で [何もしない] または [切り詰め] を選択します。
オプション [全ロードの完了後にタスクを停止する] で、[キャッシュされた変更の適用後に停止] を選択します。完全ロードが完了し、キャッシュされた変更が適用された後で、タスクを一時的に停止します。キャッシュされた変更は、テーブル全体のロードプロセスが実行されている間に発生し蓄積された変更です。これは、CDC が適用される直前のステップです。
できれば、ソース Oracle データベースを更新して、LOB を S3、DynamoDB、または別の同様のサービスに移動します。そうでない場合は、LOB を処理する方法についていくつかのオプションがあります。すべてのテーブルの LOB 全体をレプリケートする場合は、[レプリケーションに LOB 列を含める] で、[完全 LOB モード] を選択します。LOB を特定の長さまでレプリケートするのみの場合は、[制限付き LOB モード] を選択します。移行する LOB の長さは、[最大 LOB サイズ (KB)] テキストボックスで指定します。
最後に、[ログ作成の有効化] を選択して、タスクで発生したエラーや警告を確認し、問題のトラブルシューティングを行えるようにすることをお勧めします。[タスクの作成] を選択します。

次に、[テーブルマッピング] で移行するスキーマを選択し、[選択ルールの追加] を選択します。[JSON] タブを選択します。[JSON の編集を有効にする] チェックボックスを選択します。次に、次の JSON 文字列を入力し、スキーマ名 DMS_SAMPLE を使用するスキーマ名に置き換えます。
この JSON 文字列は、PostgreSQL の場合、スキーマ名、テーブル名、列名を小文字に変換します。
タスクが作成されると、自動的に開始されます。タスクを選択して[ステータス] タブをクリックすると、DMS コンソールを使用して進行状況を監視できます。全ロードが完了しキャッシュされた変更が適用されると、タスクは自動的に停止します。

全ロードフェーズが完了したらタスクを停止し、外部キーとセカンダリインデックスを再作成します。
テーブルのロードが完了しました。今度は、ログを確認してタスクにエラーがないことを確認するのがよいでしょう。
タスクの次のフェーズは、ソースデータベースで発生した順序で変更を適用する CDC です。このアプローチは、親テーブルがターゲットデータベース上の子テーブルの前に更新されるため、外部キーを再作成できることを意味します。
必要に応じて生成されたスクリプトを調整して、以前に削除された外部キーとセカンダリインデックスを再作成します。セカンダリインデックスはタスクのこのフェーズで重要となります。このフェーズは重要です。なぜなら、where 句を使用してソースデータベースに対して行われた更新は、ターゲットデータベース上のインデックスのルックアップでもあるからです。更新に欠落しているインデックスがある場合、これらの更新は全テーブルスキャンとして実行されます。
ソースからのデータを更新できるため、移行の切り替えまでトリガーを有効にしないでください。
DMS タスクを有効にする
これで外部キーとセカンダリインデックスが戻ったので、DMS タスクを有効にすることができます。DMS コンソールに移動して、[タスク] を選択します。リストでタスクを選択し、[開始/再開] を選択します。[開始] オプションを選択し、[タスクの開始] を選択します。

ツールとソフトウェアを移行し、トリガーを有効にします。
最後に、カットオーバーポイントがここにあります。ツールとソフトウェアの接続がソースデータベースへのアクセスを停止し、DMS タスクが最後のデータ変更をターゲットデータベースにレプリケートしたら、DMS コンソールで DMS タスクを停止します。次に、ターゲットデータベースでトリガーを有効にします。
ALTER TABLE <テーブル名> ENABLE TRIGGER ALL;
最後のステップは、アプリケーションを新しいターゲット PostgreSQL データベースに再配置して再起動することです。完了です。
役立つヒント
スキーマを変換しやすくするには、AWS SCT を使用して評価レポートを取得し、アクション項目を反復処理します。ターゲット PostgreSQL スキーマの最終バージョンに到達するまで、ターゲットスキーマを複数回生成する必要があります。
新しいスキーマのクエリが新しいプラットフォームで機能するようにするには、ターゲットシステムでアプリケーションをテストします。AWS SCT は、アプリケーションクエリを PostgreSQL に変換することもできます。詳細については、AWS SCT ドキュメントを参照してください。また、ターゲットシステムの負荷テストを実装して、ターゲットサーバーのサイズとデータベース設定が正しいことを確認します。
前に概要を説明した実際の移行手順を実践し、プロセスを合理化します。上記の手順は単なる出発点に過ぎず、各データベースは一意のものです。
詳細情報
また、次を検討することをお勧めします。
AWS SCT および AWS DMS のドキュメント
DMS のステップバイステップチュートリアル
DMS のベストプラクティス
GitHub の DMS サンプルデータベース
関連するブログ記事: SQL を使用して Oracle から PostgreSQL へユーザー、ロール、および許可をマップする