Amazon Web Services ブログ
Amazon Comprehend、AWS Glue、Amazon Athena を使用して感情分析をスケールする方法
現代の消費者は、ソーシャルメディア、ブログ、レビュープラットフォームを通じて企業や製品に満足感や不満を表明することがよくあります。感情分析は、企業が顧客の意見やニーズをよりよく理解し、情報に基づいてビジネスの意思決定を行うのに役立ちます。Amazon は、複数のカテゴリと言語で 1 億 3,000 万件以上の製品レビューを含むデータセットを公開しました。このデータセットを、今回のユースケースで使用します。
この記事では、Amazon S3 から未処理の Amazon 製品レビューを取り出し、データセットをクリーンアップし、各レビューから感情を抽出し、Amazon S3 に出力を書き戻すサーバーレスのデータ処理パイプラインを構築する方法を学びます。次に、最終結果を探索して視覚化します。クラウドベースの機械学習 API や他の選択した API を使用してデータを充実させる方法を強調したいと考えています。柔軟性は、パイプラインに組み込まれています。
Amazon Comprehend は機械学習を使用して、テキストにある洞察や関係を見つけます。私たちのユースケースでは、Amazon Comprehend を使用して、顧客の製品レビューから感情を判断します。使いやすい API を使用しても、意味のある洞察を得るには、未処理のデータセットをクリーンアップしてテキストをレビューする必要があります。この目的のために、Apache Spark のパワーを活用する完全マネージド型でサーバーレスの ETL (抽出、変換、ロード) サービスである AWS Glue を使用します。最後に、Amazon Athena と Amazon QuickSight を使用してデータをクエリし、視覚化します。
データパイプラインのアーキテクチャ
私たちのユースケースはシンプルですが、複雑なシナリオに合わせて簡単に拡張することができます。未処理データから始めて、すべてを一気に充実させたいと考えています。この場合、バッチ ETL プロセスが理想的です。
次の図は、私たちの処理パイプラインのアーキテクチャを示しています。

Apache Parquet 形式で Amazon S3 から未処理の Amazon 製品レビューのデータセットを読み取る (1) Glue ETL ジョブの実行から開始します。ETL は、レビューの行ごとに Comprehend API (2) を呼び出して、感情を抽出します。ETL ジョブの出力は、これも Apache Parquet 形式であるファイルのセットで Amazon S3 (3) に保存され、それぞれの製品レビューの感情の値を含めて、製品カテゴリ別に分割されます。次に、クローラー (4) を作成して新しく作成されたデータセットを検出し、それに従って AWS Glue Data Catalog を更新します。最後に、Amazon QuickSight (5) にログインし、Amazon Athena クエリエンジンを使用して視覚化を行います。とてもシンプルです。
このブログ記事を通して、ETL ジョブのさまざまなタスクに関連するので、コードスニペットを共有し、説明します。 参考のため、完全な AWS Glue ETL スクリプトを ここで確認することができます。
データの理解
何かをする前に、データを理解する必要があります。ドキュメントには、データがタブ区切り (TSV) と Apache Parquet ファイル形式で利用可能であることが記載されています。Parquet はより効率的であり、その理由からこのブログ記事で使用します。 Parquet のデータも product_category で分割されているため、すべての製品カテゴリではなく一部の製品カテゴリに固有のレビューを読むときに効率的に使用できます。AWS Glue が使用する Apache Spark では、次のようにデータを読み取るのは簡単です。
データを調べると、次のようになります。
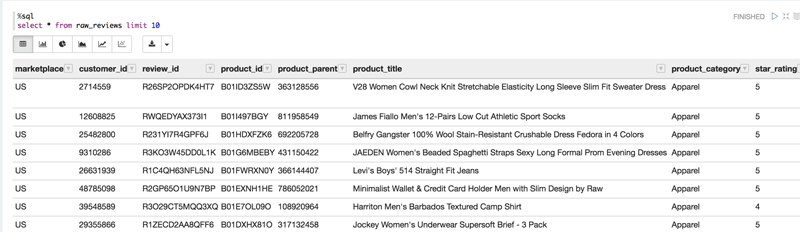
データの準備
Amazon Comprehend API を感情分析で使用するには、感情を抽出するための個々の文字列を提供する必要があります。あるいは、一度に最大 25 の文字列を使用できる bulk API を使用することもできます。 大量のデータがあるので、bulk API が良い選択でしょう。
データセットを分割するロジックに入る前に、いくつかのクリーンアップを行う必要があります。これを行うために、レビューの本文テキストの長さを含む body_len という名前の列を追加します。次に、10 文字未満および、Amazon Comprehend の最大文字長である 5,000 文字を超えるすべてのレビューを除外します。 このロジックは、適切に変更することができます。さらに、要件に基づいて処理する行の数を制限することができます。最後に、クリーンアップしたデータフレームから行の数を取得します。
行を 25 のグループに分割するロジックは、非常に簡単ですが、いくつか注意点があります。
このコードからわかるように、Spark に行を 1000 / (4 * 25) = 10 のパーティションに分割するように求めています。それぞれのパーティションには、100 行があります。おそらく、「なぜ 100 であって、25 ではないのか?」と疑問に思われるでしょう。Amazon Comprehend は、一度に 25 の文字列しか受け取らないのでは?25 で割り切れるグループを作成することで、Spark が Amazon Comprehend とインターフェイスするユーザー定義関数を呼び出す回数を減らすことができるのです。もう一つの利点は、バッチ処理を導入することでオーバーヘッドを削減できることです。 (前述した注意点は、変換する行がさらに増えるというオーバーヘッドに関係しています。単純に行数を 25 で割ると、パーティションが多すぎるため、Spark ドライバーはメモリ不足の例外をスローします。)
次のコードブロックでは、この段階では残りのデータは気にしないので、各行について繰り返し、レビューの ID と本文のみを抽出しています。さらに、指定された Spark パーティションのすべての行をまとめて配列にする glom() 関数を使用して、100 のID、本文タプルのリストを含む単一の行を生成します。
感情分析
ここで、レビュー ID と本文の各グループを取得し、Amazon Comprehend API を呼び出して、感情の値を返す関数を定義する必要があります。
Amazon Comprehend とインターフェイスするユーザー定義関数 (UDF) を見てみましょう。
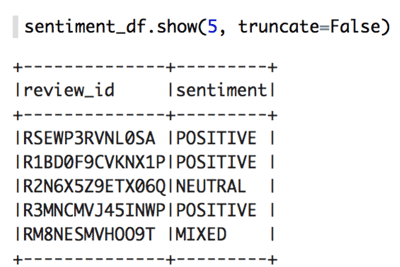
読みやすくするためと、後で DataFrame に変換するために、感情の結果を返すときに使用する Row クラスを宣言します。UDF にジャンプすると、すべてのレビュー本文テキストが bodies リスト変数に抽出されます。次に、選択したバッチの数まで、それぞれ 25 の文字列のサブリストを作成する文字列のリストを繰り返します。次に、それぞれの 25 のリストについて、Amazon Comprehend の batch_detect_sentiment API を呼び出して結果を処理し、レビュー ID と対応する感情の値のリストを返します。
これは、それぞれの行に対して UDF を実行する次のようなコード行になります。
出力は次のようになります。
すべての他の API と同様に、考慮するべき速度の制限があることを追加したいと思います。BatchDetectSentiment の場合、速度の制限は 1 秒当たり 10 リクエストです。多くのデータを並行して処理する場合、すぐにこの制限にぶつかります。この制限に対処するには、API を呼び出す頻度をコントロールするメカニズムを導入する必要があります。これを行うコードを ETL スクリプトに含めましたが、この記事ではこれ以上説明しません。
結果の結合
次に、前のステップで得られた感情の結果と元の製品レビューのリストを結合する必要があります。
このコード行は、元のレビューの DataFrame を取得し、レビュー ID と感情の値を含む感情の DataFrame と結合します。結合した後は、2 つの review_id 列になるので、1 つを削除する必要があります。
最後のステップは、データを Amazon S3 に書き出して、Amazon Athena および Amazon QuickSight を使用してデータを探索できるようにすることです。
このコード行はトリックを行います。
このコードはいくつかのことを行います。最初に、 write メソッド、それに続いて partitionBy を呼び出します。partitioned-by 列で dataset を分割することで、この列のそれぞれの値に対して Amazon S3 で Spark が作成するプレフィックス (フォルダ) が得られるので、partitionBy は重要です。私たちの場合、product_category を使用します。多くの場合、日付フィールドや、カーディナリティーが低い別の列を使用してデータを分割したい場合があります。Amazon S3 では、パスは次のようになります。
後で、Athena でデータを照会するときに、product_category 列で WHERE 句を使用して、この特定のフォルダに存在するデータだけを選択することができます。これにより、他のデータをスキャンすることが回避され、パフォーマンスが向上し、クエリごとに費やされる費用が削減されます。
コードの最後の部分は、出力モードを上書きするように設定し、実行するたびにデータセット全体を上書きします。また、追加するように設定することもできます。次に、Snappy (Parquetのデフォルトの圧縮) で圧縮された Parquet の列形式でデータを書き出します。
データの可視化
データを照会して視覚化するには、AWS Glue データカタログを新しいテーブル情報で更新する必要があります。 AWS Glue クローラーを使用してスキーマを自動的に検出し、AWS Glue データカタログを更新します。
AWS Glue コンソールを開き、左側のナビゲーションペインで [Crawlers] を選択します。新しいクローラーを追加し、名前を付けます。次に、[Include Path] フィールドで、前のセクションで出力した Parquet データへの S3 パスを指定します。[Exclude Patterns] フィールドで、次の 2 つのパターンを追加します。
- _metadata
- _common_metadata
[Next] を選択し、他のデータストアを追加するか尋ねられたら [No] のままにして、[Next] を選択します。 既存の [IAM role] を選択するか、新規に作成して、[Next] を選択します。 一度しか実行しないため、[Frequency] は [Run on demand] のままにしておきます。ただし、本番環境では、定期的な間隔でクローラーを実行するようにスケジューリングして、AWS Glue データカタログのメタデータを常に最新に保つのが良いでしょう。コンソールの次のページで、クローラーによって作成されたテーブルを保持するデータベースを選択または作成するように求められます。先へ進んで、新規に作成するか、デフォルトを使用します。さらに、名前の衝突を避けるためにテーブル名が生成されるため、テーブル名にプレフィックスを付けることができます。 最後に、[Next] をクリックして、[Finish] をクリックします。
メインのクローラーウィンドウでクローラーの横にチェックマークを付けて、[Run Crawler] を選択します。 クローラーがタスクを完了すると、データカタログに新しいテーブルが作成されます。次のように表示されます。
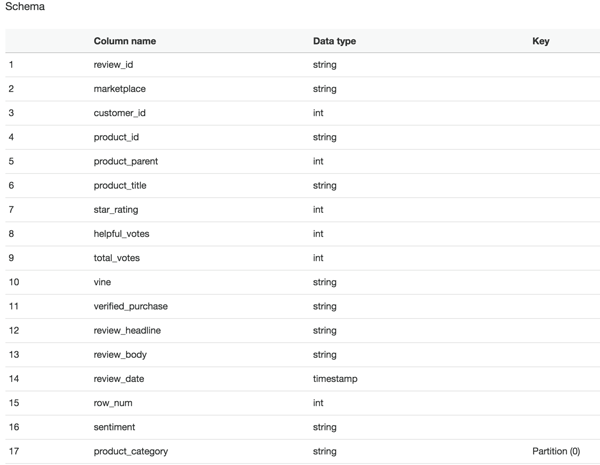
それでは、Amazon Athena コンソールに切り替えて、データを探索してみましょう。
Athena のエディタウィンドウに次の SQL 文を入力します。データベース名 (私の場合は amazon) とテーブル名 (私の場合は reviews_sentiment) を、使用している値に変更することを忘れないでください。
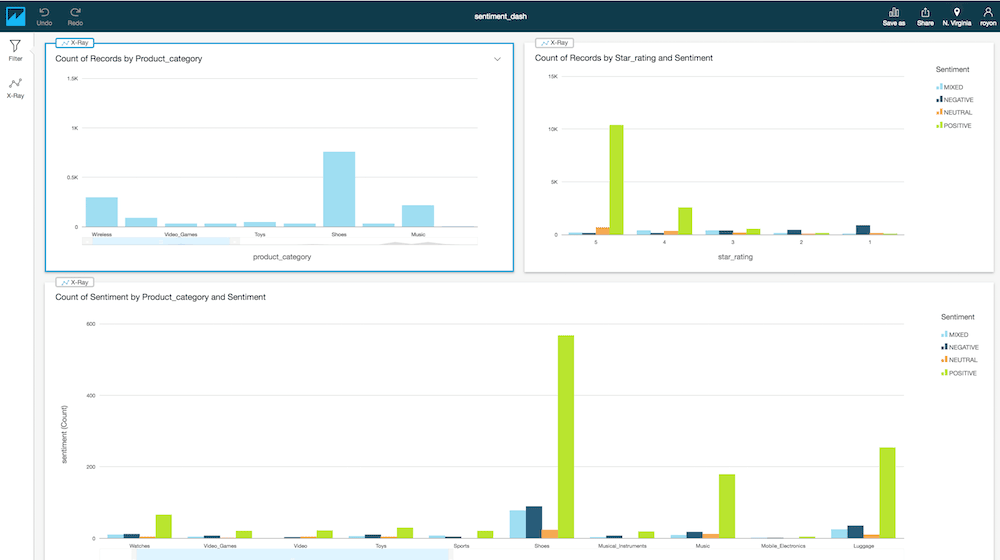
結果からわかるように、衣料品の製品レビューでの圧倒的な感情は肯定的であり、かなりの数の投票があります。

細心の注意を払った場合は、Athena のレポートのランタイム統計に気づいたかもしれません: Run time: 0.98 seconds, Data scanned: 0KB (あなたの数字は異なるかもしれません)。特に興味深いのは、スキャンしたデータの量です。これが、Parquet の列ファイル形式を使用する利点です。 Parquet は、保存する各列の数や最小値、最大値などのいくつかの統計を計算します。これにより、Athena は列データを読み取る必要なしで、特定の集約関数の結果を返すことができます。とても、良いですね。ところで、あなたのスクリプトが処理した行は私の場合と違うかもしれないので、クエリが異なる結果の値を返しても心配しないでください。
とにかく、良いデータが得られたので、Amazon QuickSight コンソールに切り替えて視覚化しましょう。
Amazon QuickSight を使ったことがないなら、このリンクに従って、設定します。
Amazon QuickSight コンソールを開いたら、[New Analysis] を選択し、ページの左上隅で [New Data Set] を選択します。使用可能なデータソースのリストから [Amazon Athena] を選択し、データソースに名前を付けて、[Create Data Source] を選択します。次に、前にクローラーを使って作成したデータベースとテーブルの名前を選択します。次のページでは、Amazon QuickSight の超高速キャッシュである SPICE を使用するか、毎回 Athena から直接データをクエリするか尋ねられます。私たちの目的のためには、直接データをクエリすることを選択しますが、ワークロードが重たい場合は SPICE の使用を強くお勧めします。[Visualize] を選択します。
これは、私が作成したシンプルなダッシュボードです。
まとめ
この時点で、好きな方法でデータを探索し、視覚化できるはずです。このブログ記事で明らかになったのは、サーバーレス技術を使用して大量のデータを迅速にクリーンアップ、変換、充実化、クエリ、視覚化するデータ処理ワークフローを構築する方法です。
さらに、AWS NLP サービスである Amazon Comprehend を使用して、大規模なデータセットを ETL ジョブで直接充実させる方法は、強力なパターンを示しています。適切な SDK を使用すれば、このパターンは、他のサービスと同様にどの AWS のサービスにも適用できます。ユーザーフレンドリーではありませんが、SDK が利用できない場合は、単にサービスの REST API を直接呼び出すこともできます。このパイプラインをまとめることで私が学んだもう 1 つの便利なパターンは、パイプラインのさまざまな段階で Amazon S3 に保存されるため、データを検査する必要があるときに Amazon Athena が本当に便利であることです。
今回のブログ投稿者について
 Roy Hasson は、AWS Analytics のグローバルビジネス開発マネージャです。彼は世界中の顧客と協力して、データ処理、分析、ビジネスインテリジェンスのニーズを満たすソリューションを設計しています。Roy はマンチェスターユナイテッドのファンであり、彼の家族とともにチームを応援しています。
Roy Hasson は、AWS Analytics のグローバルビジネス開発マネージャです。彼は世界中の顧客と協力して、データ処理、分析、ビジネスインテリジェンスのニーズを満たすソリューションを設計しています。Roy はマンチェスターユナイテッドのファンであり、彼の家族とともにチームを応援しています。