Amazon Web Services ブログ
新インスタンス- NVIDIA Tesla V100 GPUを最大8個搭載したAmazon EC2インスタンス P3
私たちは2006年に最初のm1.smallを発表した後も、お客様のご要望に応じて、そして常に進歩している最先端の技術を利用可能にするために、コンピュート能力、バースト可能な性能、メモリサイズ、ローカルストレージ、アクセラレータなどインスタンスを強化し続けています。
新しいP3インスタンス
本日、次世代のGPUを搭載したEC2インスタンスを4リージョンで公開しました。NVIDIA Tesla V100 GPUを最大8個搭載したP3インスタンスは、コンピュートインテンシブな機械学習、深層学習、流体計算、金融計算、地震解析、分子計算、ゲノム処理を想定して設計しました。
P3インスタンスは、最大2.7GHzで動作するIntel Xeon E5-2686v4プロセッサを搭載し、3種類のサイズを用意しています(VPCのみ、EBSのみ)
| Model | NVIDIA Tesla V100 GPUs | GPU Memory | NVIDIA NVLink | vCPUs | Main Memory | Network Bandwidth | EBS Bandwidth |
| p3.2xlarge | 1 | 16 GiB | n/a | 8 | 61 GiB | Up to 10 Gbps | 1.5 Gbps |
| p3.8xlarge | 4 | 64 GiB | 200 GBps | 32 | 244 GiB | 10 Gbps | 7 Gbps
|
| p3.16xlarge | 8 | 128 GiB | 300 GBps | 64 | 488 GiB | 25 Gbps | 14 Gbps |
各GPUは 5,120CUDAコアと640Tensorコアを備え、最大125TLOPSの混合精度浮動小数点演算、15.7TFLOPSの単精度浮動小数点演算、7.8TFLOPSの倍精度浮動小数点演算を可能とします。大きい2つのサイズでは、GPUはNVIDIA NVLink 2.0で相互接続され、最大300Gbpsデータレートで接続されています。これによりGPU間での中間結果やその他のデータのやりとりを、CPUやPCI-Expressを経由せずに高速に行うことが可能です。
Tensorコアとは?
このブログを書き始めるまで、私はTensorコアを聞いたことがありませんでした。大変有益なNVIDIA ブログの記事によると、Tensorコアは大きなDeep Neural Networkの学習や推論を高速化するために設計されています。各コアは、半精度(FP16)の4×4行列同士の積演算と、4×4の別の半精度もしくは単精度(FP32)行列の和演算を行い、半精度もしくは単精度の4×4行列の演算結果を保存することができます。以下にNVIDIAのブログ記事から図を転載します:
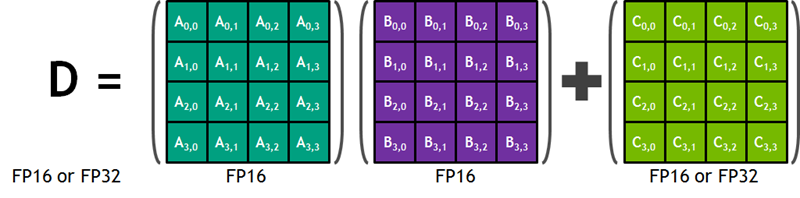
この操作は、Deep Neural Networkの学習処理において最も内部のループ処理であり、現在のGPUハードウェアが特定の市場のニーズに対して特化してどのように動作しているかを示しています。そして、Tensorコアの混合精度の性能は、16bitと32bitの浮動小数点の組み合わせを柔軟に扱えることを意味しています。
性能
実際の性能数値を提示することは、より簡易に実際のアプリケーションと関連づけられ、有意義だと考えています。8個のV100 GPUを搭載したp3.16xlargeでは、驚くことに単精度浮動小数点の乗算を1秒に125兆回可能です。
マイクロプロセッサの歴史を振り返って、1977年の夏に私が買ったIntel 8080Aチップを搭載したMITS Altairを考えてみます。2MHzクロックで秒間832回の乗算が可能でした。(このデータを使い、より速いクロックスピードに訂正しました)。p3.16xlargeは約1500億倍も高速です。しかし、その夏から12億秒が経過しました。言い換えると、過去40年に私のAltairが行なった計算に比べ、100倍以上の計算を1秒に実行することが可能となっています!
IBM PC用の追加オプションとして1981年の夏に発表された、革新的な8087数値演算コプロセッサーはどうでしょうか? 5MHzクロックで目的に特化したハードウェアで、秒間52,632回の乗算が可能でした。発表から11.4億秒が経ちましたが、p3.16xlargeは23.7億倍も高速で、当時の小さく貧弱なPCではまだ計算途中の演算が、今日では1秒で可能です。
では、Cray-1はどうでしょう?1976年に発表された最初のスーパーコンピューターは、160MFLOPSのベクトル演算が可能でしたが、p3.16xlargeは781,000倍高速です。当時に比べ、1500回も興味深い問題を繰り返し計算することが可能です。
P3と現在のスケールアウト型スーパーコンピュータの比較は難しくなっています。 スーパーコンピュータのコンポーネントとしてP3を捉え、必要に応じて使うことが可能です。
今すぐ起動できます
V100 GPUとTensorコアの利点を全て享受するには、CUDA 9とcuDNN 7が必要です。これらのドライバやライブラリは最新のWindows AMIに追加されており、Amazon Linux AMIにも11月7日に追加予定です。新しいパッケージはAWSのリポジトリで利用可能ですので、必要に応じてすでに利用中のAmazon Linux AMIにインストールできます。
最新のAWS Deep Learning AMIには、Apache MxNet、Caffe2、Tensorflow(それぞれがNVIDIA Tesla V100 GPUをサポート)の最新リリースがプリインストールされており、Microsoft Cognitive ToolkitやPyTorchなどの他の機械学習フレームワークがNVIDIA Tesla V100 GPUのサポートをリリースするとすぐに、P3インスタンスをサポートするように更新されます。また、NVIDIA Volta Deep Learning AMI for NGCを使用することもできます。
P3インスタンスは、米国東部(バージニア北部)、米国西部(オレゴン)、欧州(アイルランド)、アジアパシフィック(東京)のリージョンにて、オンデマンド、スポット、リザーブドインスタンス、Dedicated Hostとして利用可能です。
— Jeff;
原文はこちらです。