Amazon Web Services ブログ
Operating Lambda: イベント駆動型アーキテクチャの設計原則 – Part 2
Operating Lambda シリーズでは、AWS Lambda ベースのアプリケーションに関わる開発者、アーキテクト、システム管理者向けの重要なトピックについて説明します。この3部構成のシリーズではイベント駆動型アーキテクチャと、それがどのようにLambdaベースのアプリケーションと関係しているのかについて説明します。
Part 1 では、イベント駆動型パラダイムの利点と、スループット、スケール、拡張性をどのように改善できるかについて説明しました。この記事では開発者が Lambda ベースのアプリケーション構築におけるメリットを享受するための、設計原則とベストプラクティスについて説明します。
概要
ソフトウェア開発および分散システムに適用されるベストプラクティスの多くは、サーバーレスアプリケーション開発にも適用されます。幅広い原則は、Well-Architected Frameworkと一致しています。全体的な目標は次のようなワークロードを開発することです。
- 信頼性: エンドユーザーに高レベルの可用性を提供します。AWS サーバーレスサービスは障害に備えるように設計されているため、信頼性が高くなります。
- 耐久性: ワークロードの耐久性のニーズを満たすストレージオプションを提供します。
- 安全性: ベストプラクティスに従い、提供されたツールを使用してワークロードへのアクセスを保護し、問題が発生した場合にブラストラディウス(訳注:影響範囲)を制限します。
- パフォーマンス: コンピューティングリソースを効率的に使用し、エンドユーザーのパフォーマンスニーズを満たします。
- コスト効率: 不要なコストを抑え浪費することなく拡張可能であり、必要に応じて大幅なオーバーヘッドなしに廃棄可能なアーキテクチャを設計します。
Lambda ベースのアプリケーションを開発する際には、上記の目標を達成するワークロードの構築に役立つ、いくつかの重要な設計原則があります。すべてのアーキテクチャにすべての原則を適用するとは限りませんし、Lambda を使用して構築する方法はかなり柔軟性があります。しかし、これらは一般的なアーキテクチャに関する意思決定をガイドする役割を果たします。
カスタムコードの代わりにサービスを使用する
サーバーレスアプリケーションは通常、複数の AWS サービスで構成され、Lambda 関数で実行されるカスタムコードと統合されています。Lambda はほとんどの AWS サービスと統合できますが、サーバーレスアプリケーションで最も一般的に使用されるサービスは次のとおりです。
| Category | AWS service |
| Compute | AWS Lambda |
| Data storage | Amazon S3
Amazon DynamoDB Amazon RDS |
| API | Amazon API Gateway |
| Application integration | Amazon EventBridge
Amazon SNS Amazon SQS |
| Orchestration | AWS Step Functions |
| Streaming data and analytics | Amazon Kinesis Data Firehose |
分散アーキテクチャには自分で構築したり、 AWS サービスを使用して実装することが可能な既に確立された共通パターンが多数あります。ほとんどのお客様にとって、これらのパターンをゼロから開発するために時間を投資することに商業的な価値はほとんどありません。アプリケーションにこれらのパターンのいずれかが必要な場合は、対応する AWS サービスを使用します。
| Pattern | AWS service |
| Queue | Amazon SQS |
| Event bus | Amazon EventBridge |
| Publish/subscribe (fan-out) | Amazon SNS |
| Orchestration | AWS Step Functions |
| API | Amazon API Gateway |
| Event streams | Amazon Kinesis |
これらのサービスは Lambda と統合するように設計されており、Infrastructure as code (IAC) を使用してサービス内のリソースを作成、および破棄できます。アプリケーションをインストールしたりサーバーを設定したりすることなく、AWS SDK 経由でこれらのサービスを利用できます。Lambda 関数のコードを使用して、これらのサービスを使用することに習熟することは、適切に設計されたサーバーレスアプリケーションを作成する上で重要なステップです。
抽象化のレベルを理解する
Lambda サービスは、Lambda 関数を実行する基盤となるオペレーティングシステム、ハイパーバイザー、ハードウェアへのアクセスを制限します。このサービスはインフラストラクチャを継続的に改善し変更することで、機能の追加、コストの削減、サービスのパフォーマンスの向上を実現します。あなたのコードはLambda のアーキテクチャについての知識を持たずハードウェアに対する依存が無いことを前提とすべきです。
同様にLambda と統合する他のサービスも、AWS によって管理され少数の設定オプションのみが公開されます。例えばAPI Gateway と Lambda が連携する場合、サービスによって完全に管理されているため負荷分散を有効化するという概念は存在しません。また任意の時点で関数を呼び出すときにサービスが使用するアベイラビリティゾーンや、Lambda の実行環境をスケールアップまたは破棄する方法とタイミングを直接制御することもできません。
この抽象化により、アプリケーションの統合、データの流れ、エンドユーザーに価値を提供するワークロードのビジネスロジックに集中できます。サービスが基盤のメカニズムを管理することで、保守のためのカスタムコードを減らしアプリケーションをより迅速に開発できます。
関数のステートレス性の実装
Lambda 関数を組み立てる場合、環境は単一の呼び出しに対してだけ存在すると仮定する必要があります。関数は、最初に起動したときに必要な状態に初期化する必要があります。たとえばDynamoDB テーブルからショッピングカートを取得します。永続的なデータ変更は、S3、DynamoDB、SQS などの耐久性のあるストアにコミットしてから、Lambda関数を終了する必要があります。関数は既に存在するデータ構造や一時ファイル、または複数の呼び出しによって管理される内部状態 (カウンタやその他の計算された集計値など) に依存するべきではありません。
Lambda はハンドラを実行する前に、データベースへの接続、ライブラリ、その他のリソースの初期化が可能なイニシャライザを提供します。実行環境はパフォーマンスを改善するために可能な限り再利用されるため、これらのリソースの初期化にかかる時間を複数の呼び出しで標準化されます。ただし、このグローバルスコープ領域に関数内で使用する変数やデータを格納すべきではありません。
Lambda関数の設計
ほとんどのアーキテクチャは、より大きな少数の関数よりも、より短い多数の関数にすることが推奨されます。Lambda 関数をワークロードに合わせて独自にチューニングすると簡潔で、一般的には実行時間が短くなります。各関数の目的はワークフロー全体またはトランザクションのボリュームに関する知識を持たず、関数に渡されるイベントを処理することです。これにより関数が他のサービスとの結合を最小限に抑え、イベントのソースについて関知しないようにできます。
頻繁に変更されないグローバルスコープの定数は、デプロイメントせずに更新できるように環境変数として実装すべきです。シークレット情報または機微な情報はAWS Systems Manager Parameter Store または AWS Secret Manager に保存し、関数によってロードする必要があります。これらのリソースはアカウント固有であり複数のアカウントに渡るビルドパイプラインを作成することが可能です。パイプラインは開発者にこれらの情報を公開したりコードを変更したりすることなく環境ごとに適切なシークレットをロードします。
バッチの代わりにオンデマンドデータを構築する
多くの従来型のシステムは、時間の経過と共に積み上げられたトランザクションのバッチを定期的に処理するように設計されています。たとえば、銀行のアプリケーションは1 時間ごとにATM トランザクションを中央の元帳に 書き込む処理を実行するかもしれません。Lambda ベースのアプリケーションでは、トランザクションをほぼリアルタイムで処理するためにサービスが必要に応じて並列にスケールアップするので、カスタムの処理はイベントごとにトリガーされるようにします。
Amazon EventBridge のスケジュール式のルールを使用してサーバーレスアプリケーションで cron タスクを実行できますが、これらのタスクは控えめに、または最後の手段として使用する必要があります。バッチを処理するスケジュールされたタスクでは、15 分の Lambda タイムアウト以内に処理できる範囲を超えてトランザクションの量が増加する可能性があります。外部システムの制限によりスケジューラの使用が強制される場合は、通常、妥当な最短の繰り返し期間でスケジュールする必要があります。
たとえば、新しい S3 オブジェクトのリストを取得するために Lambda 関数をトリガーするバッチ処理を使用するのはベストプラクティスではありません。その理由はサービスが 15 分の Lambda 関数の実行時間内で処理できるよりも多くの新しいオブジェクトをバッチ間で受け取る可能性があるためです。
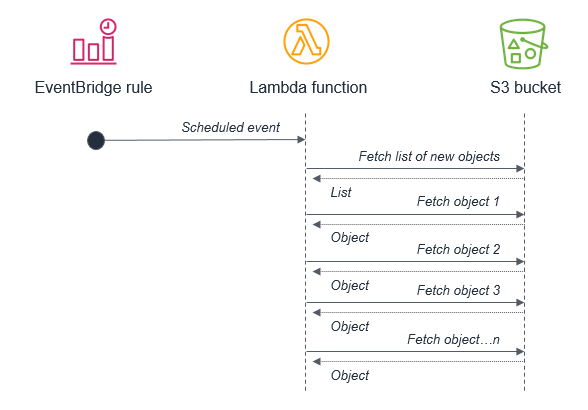
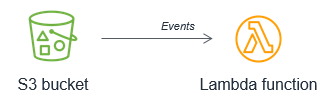
代わりに新しいオブジェクトが S3 バケットに配置されるたびに、S3 サービスによって Lambda 関数を呼び出すべきです。このアプローチの方が大幅にスケーラブルで、ほぼリアルタイムで処理を呼び出します。
ワークフローのオーケストレーション
分岐ロジック、異なるタイプのエラー処理モデル、およびリトライロジックを含むワークフローは通常全体の実行の状態を追跡するためにオーケストレータを使用します。この目的のために Lambda 関数を使用しないでください。関数グループとサービスが密結合され、ルーティングと例外処理の複雑なコードのハンドリングという結果をもたらします。
AWS Step Functionsを使うと、ステートマシンを使用してオーケストレーションを管理できます。これによってコードからエラー処理、ルーティング、分岐ロジックが取り除かれ、JSON を使用して宣言されたステートマシンに置き換えることができます。ワークフローをより堅牢で観察可能にすることとは別に、ワークフローに対してバージョン管理を追加し、ステートマシンをコード化されたリソースとしてコードリポジトリに追加することができます。
Lambda 関数内の単純なワークフローが時間の経過とともに複雑になることも、開発者が フローをオーケストレーションするのにLambda 関数を使用するのもよくあることです。本番環境でサーバーレスアプリケーションを運用する時に、これが発生しそうなことを認識することが重要であり、そうすればロジックをステートマシンに移行することが出来ます。
再試行と失敗のための開発
Lambda を含む AWS サーバーレスサービスは、耐障害性があり、失敗を処理するように設計されています。Lambdaの場合、サービスが Lambda 関数を呼び出そうとしてサービスの障害が発生した場合、Lambdaは異なるアベイラビリティーゾーンで関数を呼び出します。関数がエラーをスローした場合、Lambda サービスは関数を再試行します。
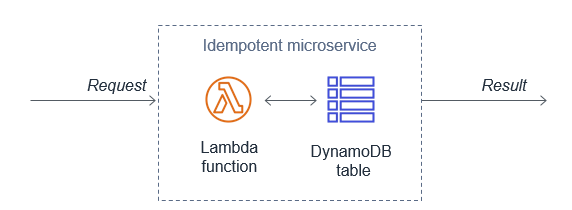
同じイベントが複数回受信される可能性があるため、関数は冪等になるように設計する必要があります。つまり同じイベントを複数回受信しても、そのイベントを最初に受け取った時と結果が変わることがないように実装します。。
たとえば、再試行によりクレジットカードのトランザクションが 2 回試行された場合、Lambda 関数は最初のレシートの支払を処理すべきです。2 回目の再試行では、Lambda 関数がイベントを廃棄するか、関数が使用するダウンストリームサービスで冪等である必要があります。
Lambda 関数は、一般的にDynamoDB テーブルを使用して直近で処理された識別子を追跡し、トランザクションが以前に処理されたかどうかを判断することによって冪等性を実装します。そのDynamoDB テーブルには通常、使用するストレージ領域を制限するためにアイテムを期限切れにするTime to Live (TTL) の値を実装します。
Lambda 関数のカスタムコード内で発生するエラーのために、サービスはイベントの保存と再試行に役立ついくつかの機能を提供し、発生したエラーを捕捉するためのモニタリングの機能を提供します。これらのアプローチを使用すると、障害に強いワークロードを開発し、Lambda 関数によって処理されるイベントの耐久性を向上させることができます。
結論
この記事では、Well-Architectedなサーバーレスアプリケーションの開発に役立つ設計原則について議論しました。コードを書く代わりにサービスを使用すると、アプリケーションの俊敏性とスケーラビリティを向上させることができる理由を説明しました。またステートレスであること、および関数の設計が、どのように優れたアプリケーションアーキテクチャに貢献するかについても示しました。バッチの代わりにイベントを使用することでサーバーレス開発にどのように役立つか、Lambda ベースのアプリケーションで再試行やエラー処理をどのように計画するかについてもカバーしました。
このシリーズのPart 3 では、イベント駆動型アーキテクチャの一般的なアンチパターンに注目し、あなたがマイクロサービスを開発する時にそれらのアンチパターンを組み入れてしまうことを避ける方法について説明します。
サーバーレスの学習リソースの詳細については、Serverless Landをご覧ください。
日本語訳はSA 福井厚が担当しました。原文はこちらです。