Amazon Web Services ブログ
Operating Lambda: パフォーマンスの最適化 – Part 2
Operating Lambda シリーズでは、AWS Lambda ベースのアプリケーションを管理している開発者、アーキテクト、およびシステム管理者向けの重要なトピックを取り上げます。この 3 部構成のシリーズでは、Lambda ベースのアプリケーションのパフォーマンスの最適化について説明します。
パート1では、Lambda 実行環境のライフサイクルについて説明し、コールドスタートを定義、測定、改善する方法について説明しました。このブログでは、メモリ構成が Lambda のパフォーマンスに及ぼす影響と、静的初期化コードを最適化する方法について説明します。
メモリとコンピューティングパワー
メモリは、Lambda 開発者が関数のパフォーマンスを制御するために使用できる主要なレバーです。Lambda 関数に割り当てられるメモリの量は、128 MB ~ 10,240 MB の範囲で設定できます。Lambda コンソールでは、新しい関数はデフォルトで最小設定になり、多くの開発者は関数に 128 MB を選択しています。
ただし、128 MB は通常、イベントを変換して他の AWS サービスにルーティングする関数など、最も単純な Lambda 関数にのみ使用された方が良いでしょう。関数がライブラリまたは Lambda レイヤーをインポートする場合、または Amazon S3または Amazon EFSからロードされたデータを操作する場合は、メモリ割り当てを増やすとパフォーマンスが向上する可能性があります。
また、メモリの量によって、関数で使用できる仮想 CPU の量も決まります。メモリを追加すると、それに比例してCPU の量が増加し、使用可能な全体的な計算能力が向上します。関数が CPU バウンド、ネットワークバウンド、またはメモリバウンドである場合、メモリ設定を変更すると、パフォーマンスが大幅に向上する可能性があります。
Lambda サービスは関数によって消費された総GB-秒に対して課金されるため、合計実行時間が一定であれば、メモリを増やすと全体的なコストに影響します。GB-秒は、総メモリ(ギガバイト)と実行時間(秒)の積です。ただし、多くの場合、使用可能なメモリを増やすと、実行時間が短くなります。その結果、全体的なコスト増加は無視できる程度になるか、または減少することさえあります。
例えば、素数を計算する関数を1000回実行した場合、異なるメモリレベルでの平均実行時間は次のようになります。
| メモリ | 実行時間 | コスト |
| 128 MB | 11.722 s | $ 0.024628 |
| 256 MB | 6.678 s | $ 0.028035 |
| 512 MB | 3.194 s | $ 0.026830 |
| 1024 MB | 1.465 s | $ 0.024638 |
このケースでは、128 MB の場合、関数が完了するまでに平均 11.722 秒かかり、1,000 回の呼び出しに対するコストは $0.024628 となります。メモリを1024MBに増やすと、所要時間の平均は1.465秒になり、コストは0.024638ドルになります。1,000分の1セントのコスト差で、この関数のパフォーマンスは10倍向上しています。
Amazon CloudWatchで関数をモニタリングし、メモリ消費が設定された最大値に近づいた場合にアラームを設定できます。これは、メモリにバウンドされた関数を識別するのに役立ちます。CPU バウンドおよび IO バウンド関数の場合、実行時間を監視することで、より多くの洞察が得られる場合があります。このような場合、メモリを増やすと、コンピューティングまたはネットワークのボトルネックを解消できます。
AWS Lambda Power Tuningによる関数のプロファイリング
Lambda 関数に割り当てられるメモリの選択は、速度 (実行時間) とコストのバランスをとる最適化プロセスです。さまざまなメモリ割り当てを設定し、関数実行終了までの時間を測定することで、関数のテストを手動で実行できますが、AWS Lambda Power Tuning ツールを使用すると、プロセスを自動化できます。
このツールは、AWS Step Functionsを使用して、異なるメモリ割り当てで Lambda 関数の複数の関数バージョンを同時実行し、そのパフォーマンスを測定します。測定対象の関数はお客様のAWSアカウントで実行され、ライブのHTTPコールとSDKのインタラクションを行い、ライブの本番シナリオで起こりうるパフォーマンスを測定します。
CI/CD プロセスを実装して、このツールを使用して、デプロイする新しい関数のパフォーマンスを自動的に測定することもできます。
結果をグラフ化することで、パフォーマンスとコストのトレードオフを可視化することができます。この例では、ある関数のコストは1024MBと1536MBのメモリで最も低く、実行速度は3008MBで最も速いことがわかります。

一般的に、CPU バウンドの Lambda 関数はメモリが増えると最大のメリットが得られますが、ネットワークバウンドのメリットは最小限に抑えられています。これは、メモリが多いほど計算能力は向上しますが、ネットワークコールのダウンストリームサービスの応答時間には影響しないためです。関数でプロファイラを実行すると、さまざまなメモリ割り当てでコードがどのように実行されるかについての洞察が得られ、関数の構成方法についてより適切な決定を下すことができます。
AWS Compute Optimizerを使用して、AWS アカウントのすべての Lambda 関数のコストパフォーマンス分析を自動化することもできます。このサービスは、過去 14 日間に少なくとも 50 回実行された関数を評価し、メモリ割り当ての自動推奨を提供します。Compute Optimizerコンソールからオプトインして、このレコメンデーションエンジンを使用できます。
静的初期化の最適化
静的初期化は、ハンドラコードが関数内で実行を開始する前に行われます。これは、ハンドラーの外で行われる「INIT」コードです。このコードは、ライブラリや依存関係のインポート、構成の設定、他のサービスへの接続の初期化などによく使われます。本番の呼び出しにおけるLambdaのパフォーマンスを分析したところ、関数実行前のレイテンシーの最大の要因はINITコードにあるというデータが出ています。開発者が最もコントロールできるセクションが、コールドスタートの実行時間に最も大きな影響を与えることもあります。

INIT コードは、新しい実行環境が初めて起動されたときに実行されます。また、関数がスケールアウトし、Lambda サービスが関数の新しい環境を作成するときにも実行されます。呼び出しがウォーム実行環境を使用している場合、初期化コードは再度実行されません。コールドスタートは以下の要素に影響を受けます。
- インポートされたライブラリと依存関係、および Lambda レイヤーの観点から見た関数パッケージのサイズ。
- コードと初期化作業の量。
- 接続およびその他のリソースを設定する際のライブラリおよびその他のサービスのパフォーマンス。
開発者は、コールドスタートの原因となる部分を最適化するために実行できるステップがいくつかあります。関数に多数のオブジェクトと接続がある場合、1 つの関数を複数の特化した関数に再構築できる場合があります。これらは個別に小さく、INIT コードが少なくなります。
関数は必要なライブラリと依存関係のみをインポートすることが重要です。たとえば、AWS SDK で Amazon DynamoDBのみを使用する場合は、SDK 全体ではなく個別のサービスを要求できます。次の 3 つの例を比較します。
// Instead of const AWS = require('aws-sdk'), use:
const DynamoDB = require('aws-sdk/clients/dynamodb')
// Instead of const AWSXRay = require('aws-xray-sdk'), use:
const AWSXRay = require('aws-xray-sdk-core')
// Instead of const AWS = AWSXRay.captureAWS(require('aws-sdk')), use:
const dynamodb = new DynamoDB.DocumentClient()
AWSXRay.captureAWSClient(dynamodb.service) テストでは、AWS SDK 全体ではなく DynamoDB ライブラリのみとすると、インポートが 125 ミリ秒速くなりました。AWS X-Ray コアライブラリのインポートは、X-Ray SDK よりも 5 ミリ秒高速でした。同様に、サービスの初期化をラップするときに、ラップする前に DocumentClient を準備すると 140ミリ秒の向上が見られました。JavaScript 用 AWS SDKのバージョン 3 では、モジュール式のインポートがサポートされるようになりました。これにより、未使用の依存関係をさらに減らすことができます。
静的初期化は、関数が同じ実行環境への複数回の呼び出しで接続を再利用できるように、データベース接続を開くのに適した場所であることが多いです。しかし、関数内の特定の実行経路でしか使用されないオブジェクトが大量にある場合があります。このような場合には、グローバルスコープの変数を遅延的にロードすることで、静的初期化の期間を短縮することができます。
グローバル変数は、呼び出しごとのコンテキスト固有の情報の格納先としては避けるべきです。1回の呼び出しの間だけ使用され、次の呼び出しでリセットされるグローバル変数を持つ関数の場合は、ハンドラのローカルな変数スコープを使用してください。これにより、呼び出し間でのグローバル変数のリークを防ぐだけでなく、静的初期化のパフォーマンスも向上します。
グローバルスコープの影響の比較
この例では、Lambda 関数がデータベースから顧客 ID を検索して支払いを処理します。いくつかの問題があります。
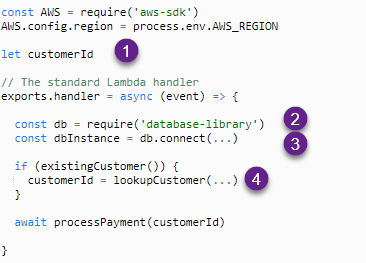
- 呼び出しごとにのみ使用されるプライベートデータは、ハンドラ内で定義する必要があります。グローバル変数は、同じ実行環境での呼び出し間で値を保持します。
- ライブラリは、ハンドラ外の初期化コードで定義する必要があります。そのため、実行環境が作成されたときに一度ロードされます。この実装により、呼び出しごとにライブラリがロードされ、パフォーマンスが低下します。
- 接続ロジックも初期化ハンドラで管理する必要があり、シークレットを含む接続文字列はプレーンテキストで保存しないでください。
- このタイプのロジックは、意図しない結果につながる可能性があります。ExistingCustomer 関数がfalseを返す場合、CustomerID は関数の最後の呼び出しからの値を保持します。その結果、間違った顧客に請求されます。
次の例では、スコープを正しく使用してこれらの問題を解決します。

- ライブラリは初期化セクションで定義され、実行環境ごとに一度ロードされます。インスタンス変数は遅延ロードされます。
- customerIdはハンドラで定義されているため、関数が終了したときに変数が消去され、関数間のデータ漏洩のリスクはありません。
- dbInstance 接続は、遅延読み込みを使用して、最初の呼び出しでのみ行われます。
- existingCustomer関数がfalseを返す場合、customerIdの値はヌルになります。
静的初期化とプロビジョニングされた同時実行性
オンデマンド Lambda 関数では、静的初期化処理は、リクエストを受信した後、ハンドラが呼び出される前に実行されます。この結果、リクエスト送信者側でレイテンシーが発生し、コールドスタート実行時間全体に影響します。前のセクションで示したように静的初期化処理を最適化することはできますが、ここで大量の作業を実行する必要がある場合があり、INIT 実行時間が長くなるのを避けることはできません。
Provisioned Concurrencyを使用すると、トラフィックを受信する前に実行環境を準備できるため、複雑で長い INIT コードを持つ関数に最適です。この場合、INIT コードの実行時間は、呼び出しの全体的なパフォーマンスに影響しません。
すべてのProvisioned Concurrencyが設定された関数は、既存のオンデマンド Lambda 実行スタイルよりも早く開始されますが、これは一部の関数プロファイルでは特に有益です。C# や Java のようなランタイムは、Node.js や Python よりも初期化時間はかなり遅くなりますが、一度初期化されると実行時間は速くなります。Provisioned Concurrency をオンにすると、これらのランタイムは、関数の起動時の一貫した低レイテンシーと、実行時のパフォーマンスの両方の恩恵を受けます。
結論
この記事は、Lambdaのパフォーマンス最適化に関する3部構成のパート2です。メモリの設定がLambdaのパフォーマンスに与える影響と、メモリの設定が関数で利用可能な計算能力とネットワークI/Oを制御する理由を説明しました。コストとパフォーマンスのバランスを取るための好ましい構成を見つけるために、Lambda関数をプロファイリングする方法について説明しました。
また、静的な初期化コードの仕組みと、このコードを最適化してコールドスタートのレイテンシを短縮する方法についても説明しました。関数のパッケージサイズ、ライブラリのパフォーマンス、モジュラーインポートがレイテンシーにどのような影響を与えるかを紹介しました。パート3では、対話型ワークロードと非同期型ワークロードの比較、Lambda関数の代わりに直接サービス統合を使用できる場合、コスト最適化のヒントを紹介します。
サーバーレスの学習リソースについては、こちらで見つけることができます。
この記事の翻訳は Solution Architect 福本が担当しました。原文はこちらからご覧いただけます。