Amazon Web Services ブログ

C# を使用した Amazon DynamoDB でのネストされたトランザクションの有効化
Amazon DynamoDB は、あらゆる規模の高性能アプリケーション向けに設計された、フルマネージド型のサーバーレス NoSQL データベースサービスです。この記事では、C# を使用して DynamoDB で ACID (原子性、一貫性、分離性、永続性) 準拠のトランザクションを管理するフレームワークを紹介します。このフレームワークは、ネストされたトランザクションのサポートを特徴としています。この機能により、.NET アプリケーション内でデータの一貫性とエラー処理をより細かく制御しながら、洗練されたロジックを実装できます。このネストされたトランザクションフレームワークを使用すると、問題を分離し、部分的なロールバックを可能にし、DynamoDB の組み込みトランザクション機能の上に保守可能でモジュール化されたワークフローを構築できます。

AWS Security Agent のオンデマンドペネトレーションテストの一般提供を開始
AWS Security Agent のオンデマンドペネトレーションテストの一般提供を開始しました。エージェンティック AI を活用した自律型ペネトレーションテストにより、すべてのアプリケーションを対象に、手動テストの数分の一のコストで脆弱性の検出・検証・修復までを実現します。コンテキスト認識型のアプローチにより、単独では見過ごされる脆弱性も検出し、それらの連鎖がもたらす重大なリスクを特定します。本記事では、仕組み、セットアップ手順、料金体系を詳しく解説します。
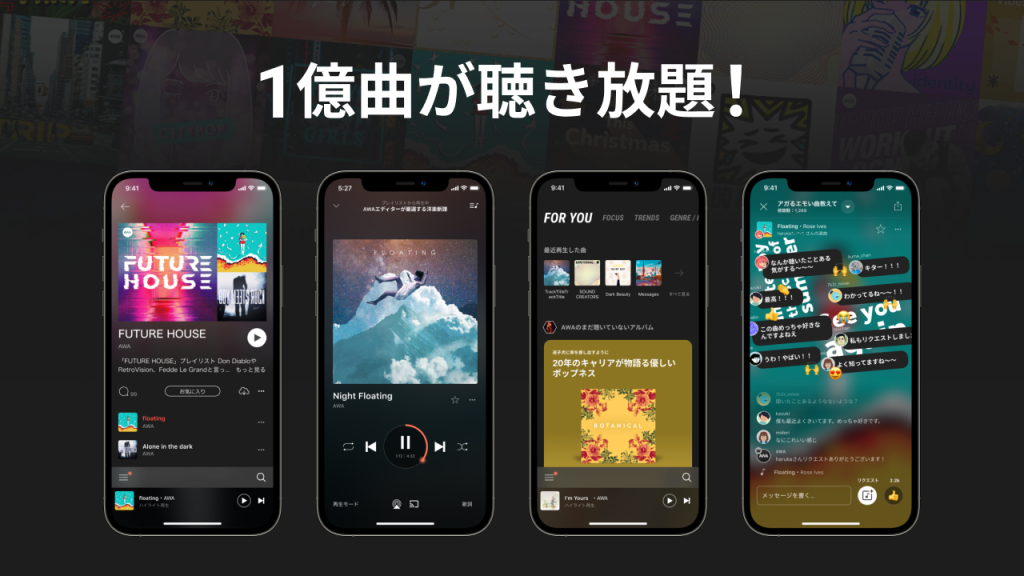
AWA 株式会社、MongoDB on EC2 から Amazon DocumentDB への移行でデータベースコストを約 50% 削減(Part 1/2)
AWA 株式会社は、MongoDB on Amazon EC2 から Amazon DocumentDB への移行を実施しました。本記事では、ドキュメント指向データベースの活用方法(スキーマレス設計、配列・ネスト構造、非正規化設計)と、Amazon DocumentDB を選択した理由について紹介します。
AWA 株式会社、MongoDB on EC2 から Amazon DocumentDB への移行でデータベースコストを約 50% 削減(Part 2/2)
AWA 株式会社が 23 億ドキュメントをニアゼロダウンタイムで Amazon DocumentDB へ移行したプロセスと、直面した課題(Writer への負荷集中、データ同期、TLS 認証対応)、そしてデータベースコスト約 50% 削減を含む移行後の効果を紹介します。

ヘルスケア業界のエンジニア 46 名がセキュリティインシデント疑似体験に挑戦 – AWS GameDay 開催レポート
2026 年 3 月 31 日にヘルスケア業界のお客様を AWS にお招きして「ヘルステック企業向け セキュリティインシデント疑似体験 GameDay」を開催しました。今回はそのイベントのご紹介や当日の雰囲気をお伝えし、セキュリティへの取り組みを知っていただければ幸いです。

Kiro に MiniMax M2.5 と GLM-5 が追加されました
Kiro に新たに MiniMax M2.5 と GLM-5 の 2 つのオープンウェイトモデルが追加されました。MiniMax M2.5 はクレジット乗数 0.25x の低コストモデルで、SWE-Bench Verified 80.2% を達成し、マルチステップ実装や長時間エージェントセッションに最適です。GLM-5 は 200K コンテキストウィンドウを持つ大規模 MoE モデルで、リポジトリ規模の複雑なアーキテクチャ変更や長期エージェントワークフローに強みを発揮します。両モデルは IDE と CLI から即座に利用可能です。
AWS Sustainability コンソールの発表: プログラムによるアクセス、設定可能な CSV レポート、スコープ 1~3 のレポートを 1 か所で
皆さんの多くと同じく、私も親です。そして、皆さんと同じように、自分の子どもたちのために築いている世界について考 […]

週刊生成AI with AWS – 2026/3/30 週
今週の「週刊 生成 AI with AWS」では、非エンジニアが Amazon Bedrock と Amazon Q Developer で契約書管理 AI エージェントを構築した大成様の事例や、Agentic AI を PoC から本番稼働へ引き上げるための組織論・ペルソナ別ガイドなど、生成 AI の「実用化」と「組織展開」に役立つコンテンツが充実しています。サービス面でも AWS DevOps Agent の GA、Amazon Bedrock AgentCore Evaluations と Amazon Bedrock Guardrails のクロスアカウントセーフガードの GA、Amazon OpenSearch Service へのエージェント AI 機能追加、Amazon S3 Vectors の 31 リージョン展開など、AI エージェントの本番運用を支える重要なアップデートを紹介しています。

Kiro CLI の新しいデザイン
私たちはターミナルが大好きです。この記事を読んでいるあなたも、きっとそうでしょう。CLI には、スピード、集中力、そして直接性という独特の魅力があります。速く、反応が良く、即座に結果が返ってくる。Kiro CLI はすでに、エージェントとの直接チャット、計画の作成、複数ステップにわたる処理の実行といった機能を通じて、エージェント型コーディングの力をターミナル環境にもたらしています。そして、さらに良い体験を追求した結果、新しいデザインへの刷新が必要だという結論に至りました。
本日、Kiro CLI の刷新された UX をご紹介します。いつでも以前の体験に戻せる「実験的モード」として提供しますので、ぜひフィードバックをお聞かせください。Kiro CLI をインストールして、コマンドラインで kiro-cli –tui と入力するだけで試せます。

AWS Deadline Cloud のサービスマネージドフリートで 3ds Max を使う方法
本記事では、AWS Deadline Cloud のサービスマネージドフリート (SMF) 上で Autodesk 3ds Max を使用する方法を紹介します。設定スクリプトを活用して 3ds Max をフリートワーカーにインストールし、マネージドインフラストラクチャの利便性とレンダリングパイプラインの柔軟性を両立する手順を解説します。