Amazon Web Services ブログ

Amazon Bedrock Guardrails では、一元化された制御と管理により、クロスアカウント保護がサポートされています
2026 年4 月 3 日、Amazon Bedrock Guardrails でクロスアカウントセーフガード […]
Amazon ECS マネージドインスタンスのマネージドデーモンサポートの発表
2026 年 4 月 1 日、Amazon Elastic Container Service (Amazon […]

AI を活用した大規模なセキュリティ防御の構築 — 脅威が出現する前に
AWS が Anthropic と共同で取り組む Project Glasswing と Claude Mythos Preview の発表、自律型ペネトレーションテストを実現する AWS Security Agent の一般提供開始、Amazon Bedrock の自動推論によるハルシネーション防止など、AI を活用した大規模セキュリティ防御の最新の取り組みと、脅威が現実化する前に先手を打つ AWS のセキュリティ哲学を紹介します。

Kiro Students プランのご紹介
学生は、私たちが暮らす世界を形作る未来の意思決定者です。この信念が、本日発表するすべての根幹にあります。まだ学び、実験し、何を作りたいかを模索している段階のみなさんに、本格的なツールを届けたいと考えています。本日より、Kiro Students プランを開始します。対象の大学生は、月 1,000 クレジット付きの Kiro を 1 年間無料でご利用いただけます。クレジットカード不要。トライアル期間の制限もありません。

コパイロットからコワーカーへ – AAAI : エージェント研究と実用化のギャップ
AAAI 2026 のパネルディスカッションで、Microsoft、Mistral、シンガポール国立大学、LinkedIn、AWS の研究者と実務者が、コーディングエージェントを本番環境に投入する際の現実的な課題について議論しました。研究は能力の最適化に注力する一方、本番環境では信頼性、コスト、レイテンシー、信頼、組織への適合性を同時に最適化する必要があり、そのギャップはアーキテクチャ設計、スケーラブルな強化学習環境の構築、評価ベンチマークの現実との乖離、そして人間とエージェント間の信頼構築という複数のレベルで現れます。パネルの結論は、AI エージェントの成功にはモデルの性能向上だけでなく、監査可能性や説明可能性を備えた信頼の仕組みづくりが不可欠であり、人間の役割はコードを書くことから、判断し、委任し、曖昧さを解消することへと移行しているというものでした。
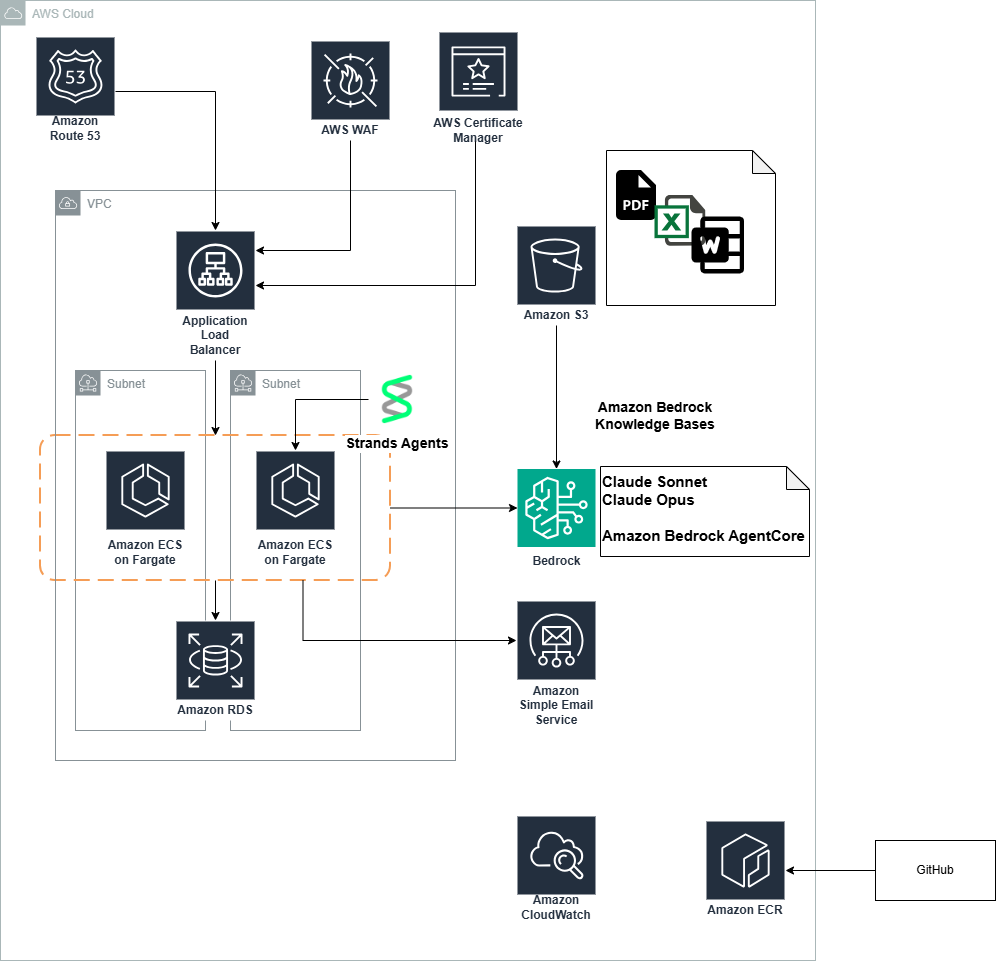
大豊建設が AWS で実現した大豊 AI:業務の様々な場面で活躍する生成 AI 活用事例
はじめに 本ブログは 大豊建設株式会社 様と Amazon Web Services Japan 合同会社が共 […]

Kiro スタートアップクレジットプログラムが復活します
起業家の皆さん、12 月のスタートアップクレジットにたくさんのご応募をいただきありがとうございました。昨年 Kiro スタートアップクレジットプログラムを開始した際、その反応は予想を大きく上回るものでした。数千もの応募が寄せられ、ニーズは明確でした。アーリーステージのチームには、成長に合わせてスケールする開発者ツールが必要だということです。
そこで、このプログラムを復活させます。本日より、対象となるスタートアップは最大 1 年分の Kiro Pro+ を無料で申請できます。仕様駆動開発と高度な AI エージェントを活用して、コストを気にせず開発を加速できます。

Amazon MSK Express ブローカー向けワークロードシミュレーションワークベンチのご紹介
Apache Kafka 設定の本番デプロイ前検証は容易ではありません。本記事では、Amazon MSK Express ブローカー向けのワークロードシミュレーションワークベンチを紹介します。AWS CDK によるデプロイで設定可能な IaC ソリューションとして、現実的なシナリオでのストリーミング設定の検証、キャパシティプランニング、アーキテクチャ検証、チームトレーニングまで幅広く活用できます。

Amazon OpenSearch Service、FAISS エンジンでのベクトル検索トラブル対処の考え方:新規ベクトルデータの投入が不安定、または失敗する場合
はじめに Amazon OpenSearch Service を使用したベクトル検索では exact k-NN […]
Amazon OpenSearch Service、FAISS エンジンでのベクトル検索トラブル対処の考え方:検索レイテンシの増加が問題になっている場合
はじめに Amazon OpenSearch Service を使用したベクトル検索では exact k-NN […]