Amazon Web Services ブログ
Amazon CloudWatch で OpenTelemetry と PromQL がサポートされました
Amazon CloudWatch で OpenTelemetry メトリクスのネイティブ取り込みと PromQL クエリがサポートされました。メトリクスあたり最大 150 ラベルの高カーディナリティメトリクスストアにより、Kubernetes やマイクロサービスのラベルの多いメトリクスを変換なしで CloudWatch に直接送信できます。AWS リソースの自動エンリッチメントと組み合わせることで、インフラストラクチャ、コンテナ、アプリケーションのメトリクスを一元管理し、PromQL でクエリできるようになります。

週刊AWS – 2026/3/30週
AWS Direct Connect に BGP 監視用 CloudWatch メトリクス追加、Amazon SageMaker Data Agent が Unified Studio Query Editor で利用可能に、Amazon Athena が追加リージョンで Capacity Reservations 開始、Amazon CloudFront が IPv6 の BYOIP をサポート開始、AWS Outposts で Amazon RDS for Oracle が利用可能に、AWS Transform custom の自動コードベース分析が GA、AWS Security Agent オンデマンドペネトレーションテストが GA、AWS DevOps Agent が GA、Amazon S3 Vectors が 17 リージョンに拡張、Amazon OpenSearch Service にログ分析向けエージェント AI 導入等

AWS DevOps Agent によるエージェンティック AI を活用した自律的インシデント対応
このブログは、AWS DevOps Agentを使った自律的なインシデント対応について解説します。従来のSREエンジニアは、障害発生時に複数のログやツールから情報を手動で収集し、原因を特定するのに数時間かかっていました。AWS DevOps Agentは、アプリケーショントポロジーの理解、クロスアカウント調査、継続的学習機能を備えた完全マネージド型のAI運用チームメンバーです。6つの主要機能(Context、Control、Convenience、Collaboration、Continuous Learning、Cost Effective)により、単純なLLMラッパーとは異なる本格的な運用支援を実現します。このブログを読むことで、AWS DevOps Agentがどのように運用の複雑性を軽減し、インシデント対応を自動化・高速化するかを理解できます。

2026 年 3 月の AWS Black Belt オンラインセミナー資料及び動画公開のご案内
2026 年 03 月に公開された AWS Black Belt オンラインセミナーの資料及び動画についてご案内させて頂きます。
動画はオンデマンドでご視聴いただけます。
AWS Sustainability コンソールの提供開始 – プログラムによるアクセス、カスタム CSV レポート、スコープ 1-3 の排出量レポートを一か所で
AWS Sustainability コンソールが提供開始されました。サステナビリティに関するレポートとリソースを一か所に集約したスタンドアロンサービスで、Billing コンソールとは独立した権限モデル、スコープ 1〜3 の排出量表示、カスタム CSV レポート、API によるプログラムアクセスなどの機能を備えています。

Kiro のエンタープライズガバナンス: MCP サーバーとモデルを管理する
Kiro に 2 つの新しいエンタープライズガバナンス機能が追加されました。管理者が承認済み MCP サーバーを JSON 形式のレジストリでホワイトリスト管理できる「MCP サーバーレジストリ」と、組織内の開発者が利用できる AI モデルを制限できる「モデルガバナンス」です。MCP レジストリは起動時・24 時間ごとに同期され、未承認サーバーへの接続を防止します。モデルガバナンスはデータレジデンシー要件への対応にも有効で、実験的モデルを承認完了まで無効化できます。これらの機能は Kiro IDE 0.11.28 / CLI 1.23 以降のエンタープライズユーザー向けに提供されます。

AWS Weekly Roundup: AWS AI/ML Scholars プログラム、Agent Plugin for AWS Serverless など (2026 年 3 月 30 日)
2026 年 3 月 23 日週の出来事で私が最も心を躍らせたのは、AWS Agentic AI バイスプレジ […]

Amazon OpenSearch Service のエージェント AI でオブザーバビリティとトラブルシューティングを効率化
Amazon OpenSearch Service にエージェント AI 機能が追加されました。エージェントチャットボット、調査エージェント、エージェントメモリの 3 つの機能が連携し、インシデント発生時のアラートから根本原因の特定までを数分で実現します。仮説駆動型の分析で複数インデックスのデータを自動相関し、平均復旧時間 (MTTR) を短縮します。
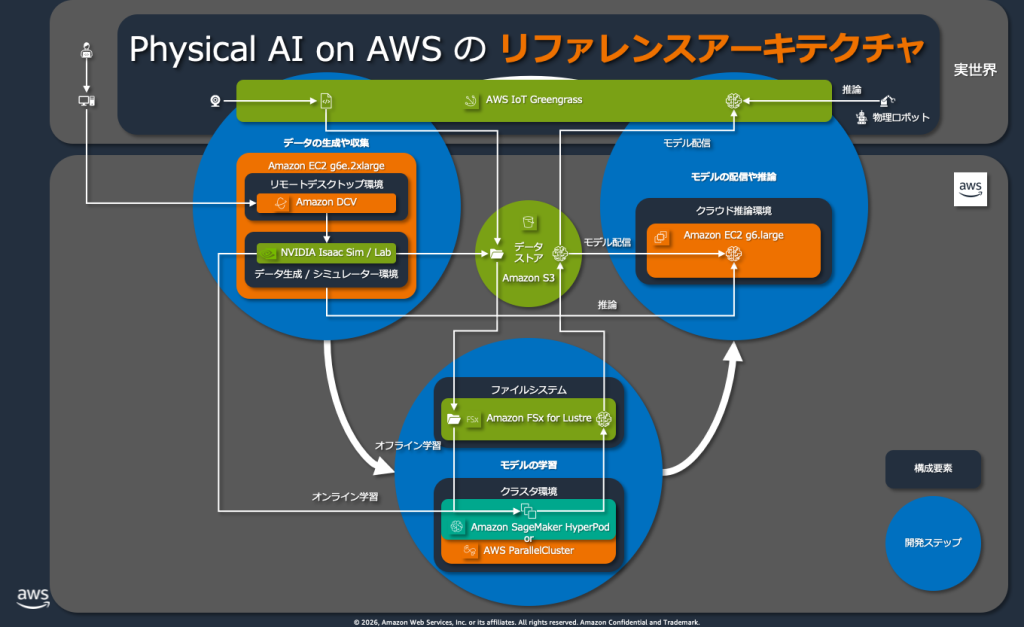
「Physical AI on AWS 勉強会 #1」を開催しました
2026 年 3 月 24 日、アマゾン ウェブ サービス ジャパン合同会社(以下、AWS ジャパン)は、「フ […]

AWS DevOps Agent の一般提供開始のお知らせ
AWS DevOps Agent の一般提供開始をお知らせします。AWS DevOps Agent は、インシデントの解決と予防、アプリケーションの信頼性とパフォーマンスの最適化、オンデマンドの SRE タスクを AWS、マルチクラウド、オンプレミス環境で処理する、いつでも対応可能な運用チームメイトです。