Amazon Web Services ブログ

Amazon CloudFront のパブリックオリジンからプライベート VPC オリジンへの移行
この記事では、さまざまな戦略を使用して Amazon CloudFront のパブリックオリジンを Amazon Virtual Private Cloud (Amazon VPC) オリジンに移行する方法を紹介します。また、クロスアカウントで VPC オリジンを使用することで、セキュリティを最優先としたアーキテクチャをサポートすることもできます。

Agentic AIの運用化 Part 2: ペルソナ別のガイダンス
本記事は 2026 年 3 月 16 日 に公開された「Agentic AI in the Enterpris […]

Agentic AIの運用化 Part 1: ステークホルダー向けのガイド
本記事は 2026 年 3 月 6 日 に公開された「Operationalizing Agentic AI […]

大成株式会社様の AWS 生成 AI 活用事例「Amazon Bedrock と Amazon Q Developer で非エンジニアが実現する契約書管理 AI エージェントの構築」のご紹介
みなさん、こんにちは。AWS ソリューションアーキテクトの古屋です。 日々のお客様との会話の中で、「業務課題を […]

Well-Architected Framework における Games Industry Lens のアップデート
ゲーム業界とライブサービスゲームが成長を続ける中、クラウドサービスは何百万ものプレイヤーに没入型の体験を提供する上で重要な役割を果たしています。世界中のゲーム開発チームは、Amazon Web Services (AWS) のインフラストラクチャを活用してゲームを構築、テスト、成長させています。彼らは分析を構築し、プレイヤーインサイトを獲得することで、開発を推進し、シームレスで低レイテンシーの体験を世界中に提供することに努めています。
AWS for Games チームは、AWS Well-Architected Games Industry Lens およびホワイトペーパー (Games Lens) のアップデート版のリリースを発表できることを嬉しく思います。Games Lens は、クラウドでゲームを構築および運用する際の独自の課題に対処することを目的としたベストプラクティスで構成されています。これらの推奨事項は、ゲーム業界の開発者、パブリッシャー、そして私たち自身の AWS for Games チームとの協働経験に基づいており、アップデートされた Games Lens に反映されています。Games Lens は、クラウドでゲームを構築および運用する際の特有の課題に対処するために設計されたベストプラクティスによって Well-Architected Framework を補完します。

Amazon Aurora DSQL 及び Database 事例イベントのお知らせ
AWS では、データと AI を活用したイノベーションの推進を支援するため、「AWS Data & A […]

電通総研、大規模 GPU 環境を約 1 ヶ月で構築 〜リアルタイム 3DCG ソリューション「UNVEIL」の戦略的アプローチ 〜
本ブログは株式会社電通総研とAmazon Web Services Japan が共同で執筆いたしました。 電 […]

Fivetran の Managed Data Lake Service の CDC で実現する業務システムから Apache Iceberg へのリアルタイムデータ連携
本記事は アマゾン ウェブ サービス ジャパン合同会社 ソリューションアーキテクト 疋田、畠 と、Fivetr […]
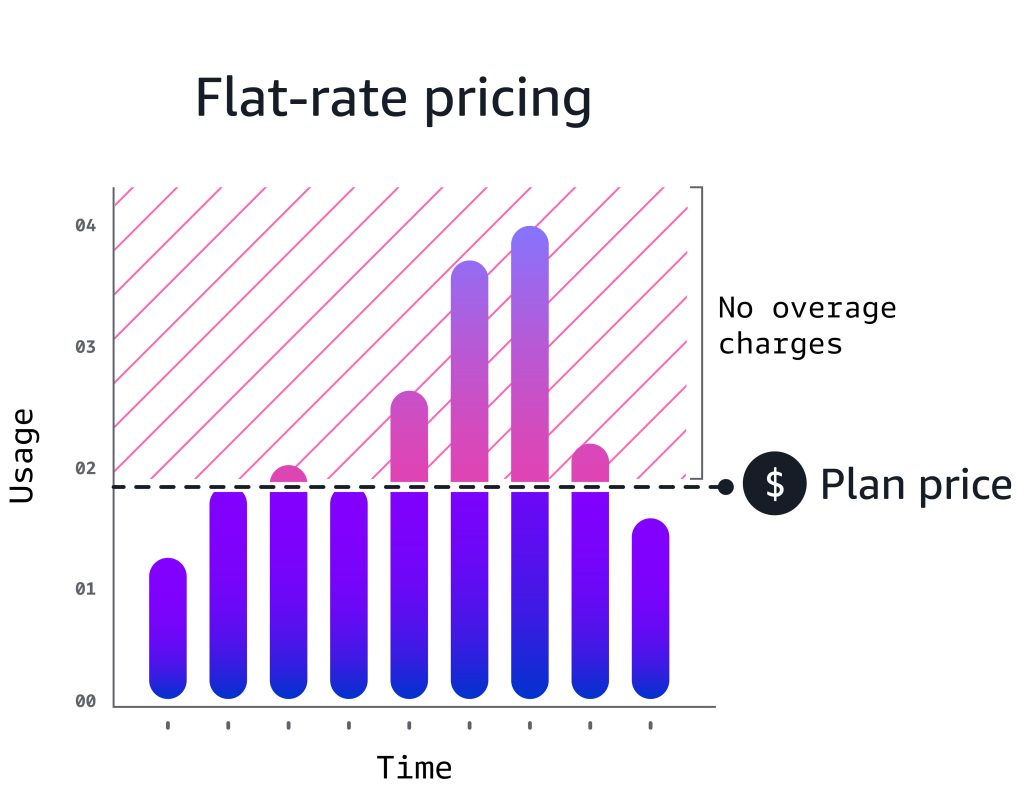
Amazon CloudFront 定額料金プラン:新機能と対応機能の拡大
Amazon CloudFront は定額料金プランのリリース以降、お客様からいただいたフィードバックをもとに新しい機能を追加してきました。この記事では、 Lambda@Edge のサポート、 CAPTCHA 、相互 TLS (mTLS) 、そして AI ボットやエージェントのトラフィックを可視化する AI アクティビティダッシュボードなど、最新の追加機能をご紹介します。また、使用量の上限を超えたトラフィックの扱いについても明確化しています。
アカウントの色、リージョン、サービスの表示などの視覚的な設定を使用して AWS マネジメントコンソールのエクスペリエンスをカスタマイズ
2025 年 8 月に、AWS User Experience Customization (UXC) 機能を […]