Amazon Web Services ブログ
aws login で AWS への開発者アクセスをシンプルに
AWS CLI の新しい aws login コマンドを使用すると、長期アクセスキーを作成・管理することなく、AWS マネジメントコンソールと同じサインイン方法で一時的な認証情報を取得できます。IAM 認証情報やフェデレーションサインインの両方に対応し、認証情報は 15 分ごとに自動ローテーションされます。IAM ポリシーによるアクセス制御や CloudTrail でのログ記録も可能で、デフォルトでセキュアな開発環境を実現します。

IAM アクセスキーからの脱却: AWS におけるモダンな認証アプローチ
IAM アクセスキーなどの長期認証情報に依存することは、認証情報の漏洩や盗難などのリスクをもたらします。この記事では、AWS CloudShell、AWS IAM Identity Center、IDE 統合、IAM ロール、IAM Roles Anywhere など、従来 IAM アクセスキーを使用してきた 5 つの一般的なユースケースに対するより安全な代替手段を紹介します。最小権限の原則の実装方法と合わせて、AWS 環境のセキュリティポスチャを改善するためのベストプラクティスを解説します。

株式会社アド・ダイセンが生成 AI で実現した現場主導の業務効率化:非技術者による生成 AI 活用の実践
本ブログは株式会社アド・ダイセン様とアマゾン ウェブ サービス ジャパン合同会社が共同で執筆いたしました。 み […]

smart EuropeがAmazon Bedrockでカスタマーサポート業務を変革した方法
自動車メーカーにとって、新型車のリリース、無線通信(OTA)によるソフトウェアアップデート、コネクテッドサービスの開始は、新鮮な顧客体験を生み出します。これらのイノベーションは運転体験の向上に役立つ一方で、自動車所有者から車両の機能、充電機能、メンテナンス手順、デジタルサービスに関する多数の問い合わせを生み出します。
AWSはsmart Europeと協力し、smart.AI Case Handlerを開発しました。このツールは、問い合わせに関するインサイトとカスタマイズされた対応を提案することで、サポート担当者の効率を大幅に向上させます。
Landing Zone Accelerator on AWS の Universal Configuration と LZA Compliance Workbook のご紹介
Landing Zone Accelerator on AWS (LZA) の最新サンプルセキュリティベースライン「Universal Configuration」と、AWS Artifact で利用可能な「LZA Compliance Workbook」を紹介します。Universal Configuration は、NIST 800-53 Rev5、CMMC、ISO-27001、HIPAA などのコンプライアンスフレームワークに対応し、セキュアなマルチアカウント AWS 環境を数時間でデプロイできます。生成 AI やエージェンティック AI ソリューションの基盤としても活用でき、規制の厳しい業界のお客様のセキュリティとコンプライアンスの取り組みを支援します。

Amazon 脅威インテリジェンスがロシアのサイバー脅威グループによる西側諸国重要インフラへの標的型攻撃を特定
Amazon 脅威インテリジェンスが、ロシア GRU 関連のサイバー脅威グループ Sandworm による西側重要インフラへの標的型攻撃キャンペーンを特定しました。2021 年から継続するこの攻撃では、設定ミスのあるネットワークエッジデバイスを侵害し、認証情報を窃取してオンラインサービスへのラテラルムーブメントを行う手法が用いられています。特にエネルギーセクターが標的となっており、組織はネットワークエッジデバイスの監査、認証情報リプレイ攻撃の検出、AWS 環境での適切なセキュリティ対策の実装を優先する必要があります。

Amazon Redshift フェデレーテッドアクセス許可でマルチウェアハウスのデータガバナンスを簡素化する
Amazon Redshift フェデレーテッドアクセス許可を使用すると、複数の Redshift ウェアハウス間でデータアクセス許可を一度定義するだけで、自動的に適用できます。本記事では、RLS と DDM ポリシーを設定し、ウェアハウス間で一貫したセキュリティを実現する方法を紹介します。
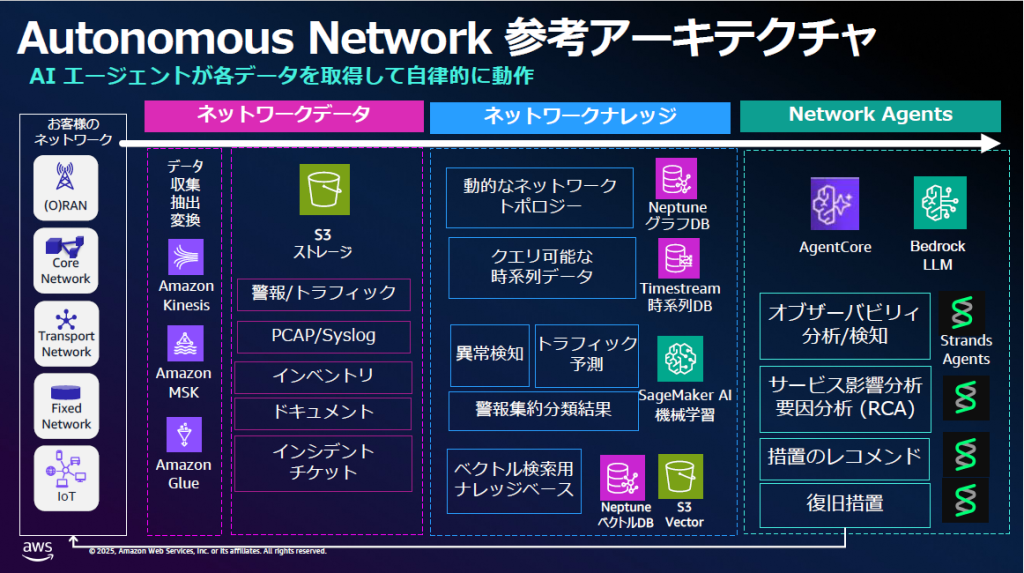
【開催報告】通信ネットワーク運用向け AI エージェントワークショップ開催しました! ( 2025 年 11 月 27 日 )
通信業界のネットワーク運用ではより安定した通信ネットワークを提供するために、障害の検知、要因特定、復旧を早期に […]

第 45 回 医療情報学連合大会 (JCMI 45th) 出展レポート
2025 年 11 月 12 日(水)~ 11 月 15 日(土)の 4 日間、兵庫県姫路市のアクリエひめじにて第 45 回医療情報学連合大会が開催されました。大会テーマは「医療 DX がもたらす医療情報新時代」。参加登録者数は 3,800 名を超え、現地では 2,900 名が参加されました。AWS は本大会において、スポンサードセッション「生成AIとヘルステックの融合が拓く、次世代の医療サービス」と展示ブースでの情報提供を通じて、医療関係者・研究者の皆様と医療 DX と生成 AI 活用の最新動向を共有する機会をいただきました。本ブログでは、セッションの登壇内容と展示ブースでの取り組みについてご報告します。

回復力のあるサプライチェーンの構築: Amazon Bedrock を活用した小売・消費財向けマルチエージェント AI アーキテクチャー
午前2時。携帯電話に緊急のアラートが届きます: 主要港湾の閉鎖、47件の入荷便への影響、そして72時間後に迫ったプロモーション開始。急いでノートパソコンを開き、在庫ダッシュボード、物流プラットフォーム、サプライヤーポータルといった十数個の異なるシステムを確認します。これらは今起きている状況の一部しか伝えておらず、必要な答えは得られません。市場シェアを競合他社に奪われる前に、どのように出荷を再ルーティングし、在庫を再配分し、プロモーションでコミットした出荷量を維持できるのでしょうか?