Amazon Web Services ブログ
Amazon SageMaker RL で継続的な学習を使用してコンテキストバンディットを強化する
Amazon SageMaker は、開発者やデータサイエンティストがあらゆる規模の機械学習モデルを短期間で簡単に構築、トレーニング、デプロイできるようにするモジュラー式完全マネージド型サービスです。 トレーニングモデルは、組み込みの高性能アルゴリズム、構築済みのディープラーニングフレームワークのセットや、独自のフレームワークを使用して、迅速かつ簡単に構築できます。 機械学習 (ML) アルゴリズムの選択を支援するために、Amazon SageMaker には、インストール済みでパフォーマンスが最適化された最も一般的な ML アルゴリズムが付属しています。
教師ありおよび教師なし学習手法を使用した機械学習モデルの構築に加えて、Amazon SageMaker RL を使用して Amazon SageMaker で強化学習モデルを構築することもできます。Amazon SageMaker RL には、強化学習の開始を容易にする、事前に構築された RL ライブラリとアルゴリズムが含まれています。GitHub には、Amazon SageMaker RL をロボットと自律走行車のトレーニング、ポートフォリオ管理、エネルギー最適化、自動容量スケーリングに使用する方法を示した例がいくつかあります。
このブログ記事では、Amazon SageMaker RL を使用してコンテキストを考慮したマルチアームバンディット (または略してコンテキストバンディット) を実装し、ユーザー向けにコンテンツをパーソナライズする方法を紹介します。コンテキストバンディットアルゴリズムは、おすすめをクリックしたかどうかなどのおすすめに対するユーザーの応答から学習することにより、ユーザー (ゲーマーやハイキング愛好家など) にさまざまなコンテンツオプションをおすすめします。このアルゴリズムでは、データの変化に適応するために機械学習モデルを継続的に更新する必要があり、Amazon SageMaker で反復トレーニングとデプロイループを構築する方法を説明します。
コンテキストバンディット
パーソナライズされたウェブサービス (コンテンツレイアウト、広告、検索、製品のおすすめなど) のような多くのアプリケーションは、多くの場合、いくつかのコンテキスト情報に基づいて、継続的に決定を下す必要に迫られます。これらのアプリケーションは、ユーザー情報とコンテンツ情報の両方を利用して、個人向けにコンテンツをパーソナライズする必要があります。たとえば、彼女がゲーム愛好家であることに関連するユーザー情報と、そのゲームがレーシングゲームであることに関連するコンテンツ情報です。これらのアプリケーションを可能にする機械学習システムには、2 つの課題があります。ユーザーの好みを学習するためのデータはまばらで偏っています (多くのユーザーはほとんどまたはまったく履歴を持たず、過去におすすめされた製品も多くありません)。また、新しいユーザーとコンテンツが常にシステムに追加されています。パーソナライゼーションに使用される従来の Collaborative Filtering (CF) ベースのアプローチは、まばらで偏っているデータセットと現在のユーザーとコンテンツのセットに対して静的な推奨モデルを構築します。一方、コンテキストバンディットは、既知の情報の exploiting (ゲーム愛好家へゲームをおすすめすること) と、おすすめの exploring (ゲーム愛好家にハイキング用具をおすすめすること) との間でトレードオフを行うことで、戦略的な方法でデータを収集および増強します。これにより、高い利益が得られる可能性があります。バンディットモデルはユーザー機能とコンテンツ機能も使用するため、同様のコンテンツとユーザーの好みに基づいて、新しいコンテンツとユーザーにおすすめを作成できます。
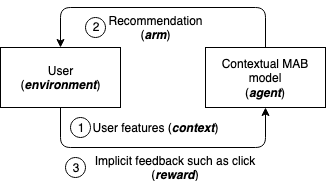
先に進む前に、いくつかの用語を紹介しましょう。コンテキストバンディットアルゴリズムは、反復プロセスによって特徴付けられます。agent が選択できる (arm または action として知られている) 選択肢がいくつかあり、そこには確率的な rewards が含まれます。各ラウンドの開始時に、environment は固定次元のstate (context とも呼ばれています)、および state に関連する各アクションの報酬を生成します。エージェントは、特定の probability を持ったアームをそのラウンドに選択し、環境はそのアームの報酬を明らかにしますが、他のアームの報酬は明らかにしません。エージェントの目標は、アクションを探索して活用することで、優れたモデルを学習すると同時に、低報酬のアクションの使用を最小限に抑えることです。
Amazon SageMaker RL コンテキストバンディットソリューション
Amazon SageMaker RL で探索/活用戦略を実装するために、次のような反復トレーニングおよびデプロイシステムを開発しました。それは、(1) ユーザーの特徴 (コンテキスト) に基づいて、現在ホストされているコンテキストバンディットモデルからのおすすめをユーザーに提示し、(2) 経時的に暗黙的なフィードバックをキャプチャし、そして (3) 増分相互作用データでモデルを継続的に再トレーニングするシステムです。
特に、Amazon SageMaker RL Bandits ソリューションには次の機能があります。 このブログと併せて、この機能を示した「Amazon SageMaker サンプルノートブック」もリリースします。
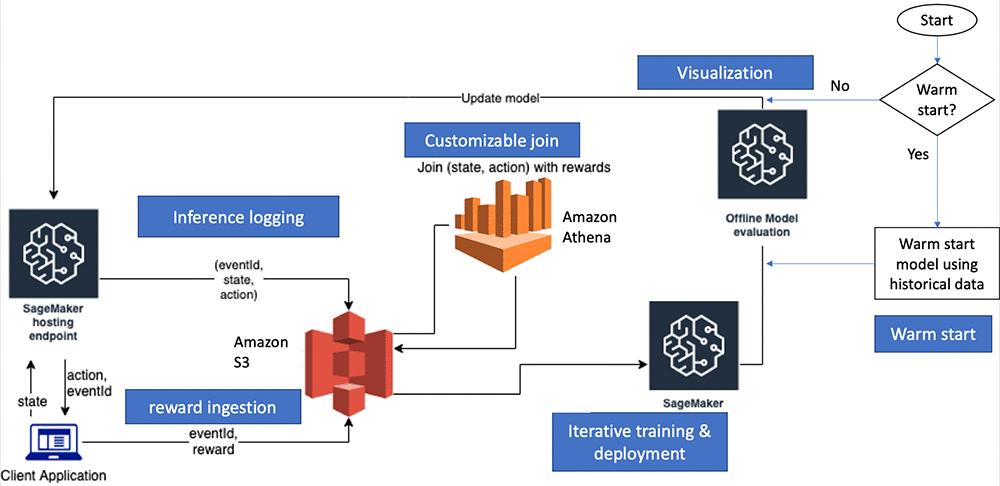
Amazon SageMaker RL Bandits Container: Amazon SageMaker RL バンディットコンテナは、Vowpal Wabbit (VW) プロジェクトからコンテキストバンディットアルゴリズムのライブラリを提供します。さらに、予測のためにトレーニングされたバンディットモデルをホストするためのサポートも提供します。
ウォームスタート: ユーザーとコンテンツの対話をキャプチャする履歴データがある場合、それを使用して初期モデルを作成できます。特に、<state, action, probability, reward> 形式のデータが必要です。このようなデータの存在は、モデルの収束時間 (トレーニングとデプロイのサイクル数) の改善に役立ちます。そのようなデータがない場合、モデルをランダムに初期化することもできます。Amazon SageMaker のサンプルノートブックの次のコードでは、履歴データを使用してバンディットモデルをウォームスタートする方法を示しています。
(シミュレーション) クライアントアプリケーションと報酬の摂取: 実際のアプリケーション (たとえば、ユーザーにおすすめ商品を提供する小売ウェブサイト) は、上の図ではクライアントアプリケーションと呼ばれ、ユーザー機能 (state) で Amazon SageMaker でホストされているエンドポイントに ping を送信し、それと引き換えにおすすめ (action) と関連する確率 (probability) を受け取ります。さらに、クライアントアプリケーションはシステムが生成した event_id も受け取ります。ユーザーのおすすめとの対話の結果として生成されたデータは、後続のトレーニングの反復で使用されます。特に、関心のあるユーザーの行動 (クリックや購入など) は、フィードバックまたは reward としてキャプチャされます。フィードバックは瞬時ではない場合があり (おすすめの数時間後に購入) 、クライアントアプリケーションは (1) reward を event_id に関連付け、 (2) 集計された報酬データ (<reward, event_id>) を S3 に戻すことが予想されます。このようなクライアントアプリケーションを実装する方法を示すために、サンプルノートブックにコードを含めます。シミュレートされたアプリケーションには、Amazon SageMaker エンドポイントへの HTTP リクエストを行うロジックを持つ予測オブジェクトがあります。 event_id は、推論データ (<state, action, probability, event_id>) を報酬データ (<reward, event_id>) に結合するために使用します。
推論ロギング: デプロイされたコンテキストバンディットモデルでユーザーインタラクションから生成されたデータを使用するには、推論時にデータをキャプチャできる必要があります (<state, action, probability, event_id>)。バンディットモデルを提供するデプロイされた Amazon SageMaker エンドポイントから、推論データのロギングが自動的に行われます。データがキャプチャされ、ユーザーアカウントの S3 バケットにアップロードされます。このデータが保存されている S3 ロケーションの詳細については、ノートブックを参照してください。
カスタマイズ可能な結合: 反復ごとに、推論データを報酬データと結合することにより、トレーニングデータを取得できます。デフォルトでは、指定されたすべての報酬データと推論データが結合に使用されます。Amazon SageMaker RL Bandits ソリューションでは、推論データと報酬データを結合できる時間枠 (結合までの時間数) を指定することもできます。
反復トレーニングとデプロイ (継続的学習のセットアップ): サンプルノートブックと付随するコードは、Amazon SageMaker およびその他の AWS のサービスを使用して、反復トレーニングおよびデプロイループを作成し、バンディットモデルを構築およびトレーニングする方法を示すのに役立ちます。これは 2 つの部分で示されます。最初に、ノートブックは各ステップを個別に示します (モデルの初期化、最初のモデルのデプロイ、クライアントアプリケーションの初期化、報酬の取り込み、モデルの再トレーニング、リデプロイ)。個々の手順は、開発段階で役立ちます。その後、エンドツーエンドのループで、開発後にバンディットモデルをデプロイする方法を示します。ExperimentManager クラスは、すべてのバンディット/RL および継続的な学習ワークフローに使用できます。Amazon SageMaker Python SDK のエスティメーターと同様に、ExperimentManager にはトレーニング、デプロイ、および評価のための方法が含まれています。ジョブのステータスを追跡し、ワークフローの現在の進行状況を反映します。Amazon SageMaker に加えて、継続的な学習ループをサポートするために必要な Amazon DynamoDB、Amazon Kinesis Data Firehose、Amazon Athena などの AWS リソースの AWS CloudFormation スタックをセットアップします。
オフラインモデルの評価と視覚化: すべてのトレーニングおよびデプロイの反復で、オフラインモデル評価を使用してデプロイ済みモデルを更新する決定を支援する方法を示します。トレーニングサイクルごとに、新しくトレーニングされたモデルが現在デプロイされているモデルよりも優れているかどうかを評価する必要があります。評価データセットを使用して、現在デプロイされているモデルと比較して、新しいモデルがデプロイされた場合はどうなるかを評価します。Amazon SageMaker RL は、この反事実分析 (CFA) を実行することでオフライン評価をサポートしています。デフォルトでは、二重ロバスト (DR) 推定メソッドを適用します [1]。これらの評価スコアは Amazon CloudWatch にも送信されるため、長い実行サイクルでは、ユーザーは時間の経過に応じて進行状況を視覚化できます。
Amazon SageMaker サンプルノートブック
バンディットアプリケーションのデモを行うために、UCI Machine Learning リポジトリの Statlog (Shuttle) データセットを使用しました [2]。スペースシャトル飛行中のインジケーターに関連する 9 つの整数属性 (または特徴) が含まれており、目標はスペースシャトルのラジエーターサブシステムの 7 つの状態の 1 つを予測することです。バンディットソリューションを実証するために、このマルチクラス分類問題をバンディット問題に変換します。分類問題では、アルゴリズムは特徴を受け取り、データポイントごとにラベルを修正します。バンディット問題では、アルゴリズムは特徴に応じてラベルオプションの 1 つを選択します。これが元のデータポイントのクラスと一致する場合、1 の報酬が割り当てられます。そうでない場合、ゼロの報酬が割り当てられます。
ウォームスタートの特徴を紹介するオフラインデータセットを作成します。この目的のために、100 個のデータポイントがランダムに選択されます。特徴はコンテキストと見なされ、7 つの (probability=1/7) から 1 つのクラスをランダムに選択することにより、各サンプルに対してアクションが生成されます。トレーニングとデプロイのループ中に、ホストされたバンディットモデルが予測クラス (アクション) と関連する確率を生成します。この場合も、予測されたクラスが実際のクラスと一致する場合、報酬は 1 として割り当てられます。それ以外の場合は、ゼロに設定されます。500 データポイントごとに、蓄積されたデータを使用して、オフラインモデル評価に基づいてデプロイされたモデルを再トレーニングします。
ローカルと Amazon SageMaker モード
探索/活用戦略には、反復トレーニングとモデルデプロイサイクルが必要です。 実験/開発サイクルを高速化するために、Amazon SageMaker ローカルモードを使用しました。このモードでは、モデルのトレーニング、データの結合、デプロイが Amazon SageMaker ノートブックインスタンスで行われ、反復の高速化に役立ちます。ローカルモードから Amazon SageMaker のトレーニングに簡単に移行でき、1 回のクリックで高いモデルスループットにスケーリングする必要がある本番ユースケースに対応できます。
さまざまな探査戦略の比較
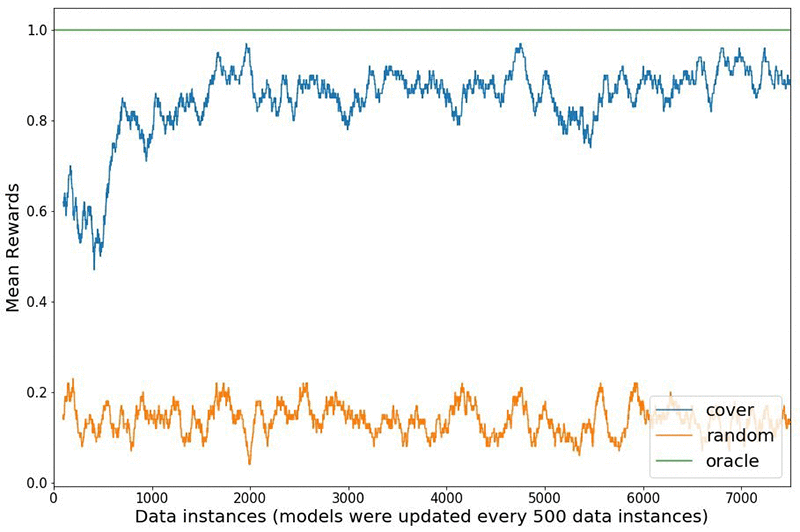
Statlog (Shuttle) シミュレーション環境で受け取った報酬を、環境を探索するのに単純なランダム戦略を使用するのと、オンラインカバーと呼ばれるバンディットアルゴリズムとの間で比較します [3]。以下の図は、バンディットアルゴリズムがさまざまなアクションを最初に探索し、受け取った報酬から学習し、時間の経過とともに活用に移行する方法を示しています。予測されたアクションが正しいクラスである場合、エージェントは 1 の報酬を受け取り、それ以外の場合はゼロを受け取ります。オラクルは、各状態に対して取るべき適切なアクションを常に知っており、1 つの完全なスコアを取得します。実験は、100 個のデータポイントからウォームスタートされたモデルで開始し、合計 7500 回の相互作用に対して 500 回の相互作用ごとにモデルを更新します。表示される報酬は、100 データポイントを超えるローリング平均です。報酬プロットは、文献で報告された結果と一致しています [4]。
まとめ
このブログ記事では、Amazon SageMaker RL および Amazon SageMaker 組み込みバンディットコンテナを使用して、コンテキストバンディットモデルを体系的にトレーニングおよびデプロイする方法を紹介しました。ライブ環境と相互作用し、効率的な探索とともにモデルを更新するマルチアームコンテキストバンディットモデルのトレーニングを開始する方法を説明しました。添付の Amazon SageMaker サンプルノートブックは、Amazon SageMaker マネージドサービスが提供するすべての利点に加えて、独自のバンディットワークフローを管理する方法を示しています。Amazon SageMaker RL の詳細については、こちらの開発者向けドキュメントをご覧ください。
参考文献
- Dudik, M., Langford, J. and Li, L.(2011).Doubly Robust Policy Evaluation and Learning.In Proceedings of the 28thInternational Conferenceon Machine Learning (ICML 2011).
- Dua, D. and Graff, C.(2019).UCI Machine Learning Repository.Irvine, CA: University of California, School of Information and Computer Science.
- Agarwal, A., Hsu, D., Kale, S., Langford, J., Li, L. and Schapire, R.E.(2014).Taming the monster: A fast and simple algorithm for contextual bandits.In Proceedings of the 31st International Conference on Machine Learning (ICML-14).
- Bietti, A., Agarwal, A. and Langford, J.(2018).A Contextual Bandit Bake-off.
著者について
 Saurabh Gupta は、AWS Deep Learning のアプライドサイエンティストです。彼は、カリフォルニア大学サンディエゴ校で AI と Machine Learning の修士号を取得しました。彼は、自然言語処理と強化学習アルゴリズム、および現実世界でデプロイできる前者の高性能で実用的な実装を提供することに関心を持っています。
Saurabh Gupta は、AWS Deep Learning のアプライドサイエンティストです。彼は、カリフォルニア大学サンディエゴ校で AI と Machine Learning の修士号を取得しました。彼は、自然言語処理と強化学習アルゴリズム、および現実世界でデプロイできる前者の高性能で実用的な実装を提供することに関心を持っています。
 Bharathan Balaji は AWS のリサーチサイエンティストで、彼の研究対象は強化学習システムとアプリケーションです。彼は Amazon SageMaker RL と AWS DeepRacer の立ち上げに貢献しました。彼はカリフォルニア大学サンディエゴ校でコンピューターサイエンスとエンジニアリングの博士号を取得しました。
Bharathan Balaji は AWS のリサーチサイエンティストで、彼の研究対象は強化学習システムとアプリケーションです。彼は Amazon SageMaker RL と AWS DeepRacer の立ち上げに貢献しました。彼はカリフォルニア大学サンディエゴ校でコンピューターサイエンスとエンジニアリングの博士号を取得しました。
 Anna Luo は AWS のアプライドサイエンティストです。彼女は、サプライチェーンや推奨システムなど、さまざまな分野で RL テクニックを活用しています。彼女カリフォルニア大学サンタバーバラ校の統計学で博士号を取得しました。
Anna Luo は AWS のアプライドサイエンティストです。彼女は、サプライチェーンや推奨システムなど、さまざまな分野で RL テクニックを活用しています。彼女カリフォルニア大学サンタバーバラ校の統計学で博士号を取得しました。
 Yijie Zhuang は AWS SageMaker のソフトウェアエンジニアです。彼はデューク大学でコンピューター工学の修士号を取得しました。彼は、スケーラブルなアルゴリズムと強化学習システムの構築に関心を持っています。彼は Amazon SageMaker 組み込みアルゴリズムと Amazon SageMaker RL に貢献しました。
Yijie Zhuang は AWS SageMaker のソフトウェアエンジニアです。彼はデューク大学でコンピューター工学の修士号を取得しました。彼は、スケーラブルなアルゴリズムと強化学習システムの構築に関心を持っています。彼は Amazon SageMaker 組み込みアルゴリズムと Amazon SageMaker RL に貢献しました。
 Siddhartha Agarwal は、AWS Deep Learning チームのソフトウェア開発者です。カリフォルニア大学サンディエゴ校でコンピューターサイエンスの修士号を取得し、現在は SageMaker で強化学習ソリューションの構築に注力しています。SageMaker に取り組む前は、AWS の自然言語処理サービスである Amazon Comprehend に取り組んでいました。余暇には料理をしたり、新しい場所を探検したりするのが大好きです。
Siddhartha Agarwal は、AWS Deep Learning チームのソフトウェア開発者です。カリフォルニア大学サンディエゴ校でコンピューターサイエンスの修士号を取得し、現在は SageMaker で強化学習ソリューションの構築に注力しています。SageMaker に取り組む前は、AWS の自然言語処理サービスである Amazon Comprehend に取り組んでいました。余暇には料理をしたり、新しい場所を探検したりするのが大好きです。
 Vineet Khare は、AWS Deep Learning のサイエンスマネージャーです。彼は、研究の最前線にある技術を使用して、AWS 顧客の人工知能および機械学習のアプリケーションを構築することに重点を置いています。余暇には、彼は読書、ハイキング、家族との時間を楽しんでいます。
Vineet Khare は、AWS Deep Learning のサイエンスマネージャーです。彼は、研究の最前線にある技術を使用して、AWS 顧客の人工知能および機械学習のアプリケーションを構築することに重点を置いています。余暇には、彼は読書、ハイキング、家族との時間を楽しんでいます。