Amazon Web Services ブログ
MXNet と Amazon Elastic Inference を使用した、深層学習の推論コストの削減
Amazon Elastic Inference (Amazon EI) は、Amazon EC2 および Amazon SageMaker インスタンスに低コストの GPU 駆動のアクセラレーションをアタッチ可能にするサービスです。MXNet は AWS re:Invent 2018 での最初のリリース以来 Amazon EI をサポートしています。
このブログでは、MXNet で Amazon EI を使った場合のコストとパフォーマンスのメリットについて詳しく見ていきます。当初 43ms だった推論のレイテンシーを 1.69 倍改善し、コスト効率が 75% 向上している例をご紹介します。
Amazon Elastic Inference のメリット
Amazon Elastic Inference は深層学習推論の実行コストを最大 75% 削減できます。最初に、Elastic Inference とその他の Amazon EC2 のオプションをパフォーマンスとコストの点で比較します。
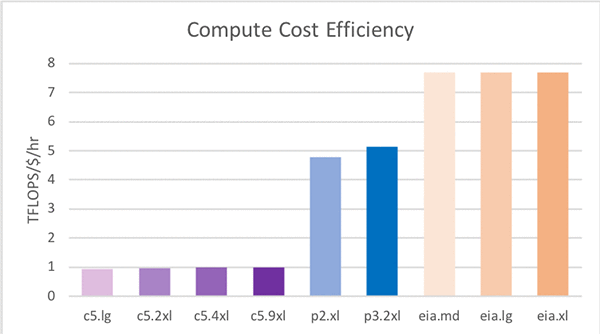
以下の表は各 EC2 オプションのリソース、キャパシティー、コストを詳しく示したものです。c5.xlarge + eia1.xlarge と p2.xlarge のコンピューティング性能がほぼ同じである点に注目してください (ハイライトしている以下の 2 つの行)。
| インスタンスタイプ | vCPUs | CPU メモリ (GB) | GPU メモリ (GB) | FP32 TFLOPS | USD/時間 | TFLOPS/USD/時間 |
| C5.Large | 2 | 4 | – | 0.08 | 0.09 USD | 0.94 |
| C5.XLarge | 4 | 8 | – | 0.17 | 0.17 USD | 1.00 |
| C5.2XLarge | 8 | 16 | – | 0.33 | 0.34 USD | 0.97 |
| C5.4XLarge | 16 | 32 | – | 0.67 | 0.68 USD | 0.99 |
| C5.9XLarge | 32 | 64 | – | 1.34 | 1.36 USD | 0.99 |
| P2.XLarge (K80) | 4 | 61 | 12 | 4.30 | 0.90 USD | 4.78 |
| P3.2XLarge (V100) | 8 | 61 | 16 | 15.70 | 3.06 USD | 5.13 |
| EIA1.Medium | – | – | 1 | 1.00 | 0.13 USD | 7.69 |
| EIA1.Large | – | – | 2 | 2.00 | 0.26 USD | 7.69 |
| EIA1.Xlarge | – | – | 4 | 4.00 | 0.52 USD | 7.69 |
| C5.XL + EIA.XL | 4 | 8 | 4 | 4.17 | 0.69 USD | 6.04 |
コンピューティング能力 (Tera-Floating-point-Operations-Per-Second または TFLOPS) に注目すると、C5.4XLarge は 0.67 TFLOPS の性能が 1 時間あたり 0.68 USD である一方、EIA1.Medium は 1.00 TFLOPS がほんの 0.13 USD のコストです。パフォーマンスだけが目的の場合 (コストを無視)、15.7 TFLOPS の P3.2XLarge インスタンスを活用すれば最高のパフォーマンスが得られることは明らかです。しかし、1 ドルあたりの TFLOPS を示す最後の列を見ると、EI アクセラレータ― (EIA) が最大の価値を提供することがわかります。EI アクセラレーター (EIA) は EC2 インスタンスにアタッチする必要があるため、最後の行に組み合わせ例の 1 つを示しています。C5.XLarge + EIA1.XLarge の vCPU と TFLOPS の値は P2.XLarge とほぼ同じですが、1 時間あたりのコストを比較すると C5.XLarge + EIA1.XLarge で 0.69 USD、P2.XLarge で 0.90 USDとなっています。つまり、1 時間あたり 0.21 USD の割引です。これは Amazon EI を利用するもう 1 つのメリットであり、ニーズに合わせて vCPU、メモリ、GPU のキャパシティーを無駄なく構成できます。
Amazon EI での Apache MXNet の利用
Apache MXNet はオープンソースの深層学習フレームワークであり、ディープニューラルネットワークの構築、訓練、展開に使います。MXNet はニューラルネットワークを実装する際の複雑な作業の多くを抽象化します。また、パフォーマンスと拡張性に優れ、API では Python、C++、Java、R、Scala など多くのプログラミング言語をサポートしています。Amazon EI 対応の Apache MXNet は AWS 深層学習 AMI で利用できます。「pip」パッケージは Amazon S3 で利用できるため、Amazon Linux や Ubuntu AMI、Docker コンテナでも構築できます。
ここで、様々なインスタンスについて ResNet-152 モデルのパフォーマンス (レイテンシー) とコスト効率のトレードオフを分析します。このブログ用に修正を加えた AWS のサンプルコードを使います。推論のパフォーマンスを測定するために変更した部分は青で示します。
ご覧のように、推論の呼び出しの前後にループを追加し、forward() と get_outputs() 関数の所要時間を計りました。MXNet は遅延評価を使うため、forward 呼び出しを強制的に実行するにはこの出力を使う必要があります (numpy 配列に変換する)。最初の推論は EIA にあるリモート GPU の初期化が原因で異常に遅くなるため、最初の推論時間は別に保存し、それ以外の推論レイテンシーで合計を出して平均を計算しました。
EI アクセラレーターを使うインスタンスのセットアップ
AWS 深層学習 AMI (DLAMI) を使ってインスタンスを起動します。このインスタンスは Amazon EI を使った Apache MXNet をに既に対応しています。Elastic Inference に関連する手順については、Elastic Inference の前提条件で確認できます。Elastic Inference アクセラレーターを使用して DLAMI を起動する方法は、Elastic Inference のドキュメントを参照してください。
EI アクセラレーターを使うインスタンスのテスト
最大の EI アクセラレーターである EIA1.XLarge で C5.4XLarge インスタンスを起動しました。この構成はおそらく必要以上のコンピューティング性能を提供しますが、EI で得られる最高のパフォーマンスから逆向きに取り組む開始点として最適です。次に、EI で MXNet を使うために、インストール済みの conda 環境を以下のコマンドを使ってアクティブにしました。
EI アクセラレーターが設定されているインスタンス上でコードを実行すると、次の出力が得られます。
最初の長い推論時間は 2763.00 ms です。最初の推論後に実行した 99 回の反復の平均は 20.34 ms です。
C5 インスタンスのテスト
同じスクリプトを一か所だけ変更すれば、同じインスタンスで CPU のみを使って推論を実行できます。今回はコンテキストを CPU に設定したため、MXNet は EI アクセラレーターを使いません。
このコードを実行すると、次の出力が得られます。
推論の平均が 44.61 ms であることに注目してください。EI アクセラレーターを使用した最初の実行と比較すると、標準の C5 インスタンス使用時ではそれぞれの推論の呼び出しに対して、CPU は平均して 2.19 倍長くかかっています。
GPU インスタンス上でのテスト
次に性能を比較するために、別の P2.XLarge インスタンスを起動します。使用した DLAMI のバージョンは同じです。インスタンスを起動後、通常の MXNet conda 環境を有効化します。
ここでスクリプトに以下の 2 つの調整が必要です。
変更した最初のコンテキストはバインディングに使用されるもので、2 番目に変更したコンテキストは入力データの場所です。CPU と EIA のインスタンスについて、データは CPU のコンテキストに割り当てられる必要があります。通常は、モデルにバインドするものと同じコンテキスト上に ndarray を作成することは重要なので指摘しておきます (CPU には CPU、GPU には GPU)。ただし、EIA については、モデルと EIA のコンテキストをバインドします。データは CPU のコンテキストで作成します。MXNet は必要に応じて自動的にデータを EIA にコピーします。
このコードを P2.XLarge インスタンスで実行すると、次の出力が得られます。
結論に至る前に、性能を比較するため別の P3.2XLarge インスタンスを起動してみます。先に P2.XLarge インスタンスのために使った、同じ DLAMI スクリプトと conda 環境が使用できます。コードを実行すると P3.2XLarge インスタンスで次の出力が得られます。
C5、P2、P3 と EIA インスタンスの比較
これまでに集めたデータをグラフにすると、GPU は CPU より (予想通り) 性能が良く、P3 インスタンスの V100 GPU は、P2 インスタンスの K80 GPU より3.34倍速いことがわかります。以前は P2 と P3 の間で選択する必要がありましたが、EI によってその中間に速度では P2 を超え 2.02 倍増加する別の選択肢ができました。

単位時間あたりのインスタンスのコストだけに基づけば (EIA と EC2 に対する us-east-1)、C5.4XL + EIA.XL のコストは P2 と P3 インスタンスの間にあることがわかります (下記の表を参照ください)。しかし、100,000 回の推論を実行するコストをファクタリングしてみると、P2 と P3 のインスタンスではコストはほぼ同額であり、C5.4XL と C5.4XL +EI インスタンスもそれぞれ 1 USD 以下 (0.84USD と 0.83USD) であることがわかります。大局的に見ると、EIA を使うことにより、C5 インスタンスのコストで、P2 のパフォーマンスよりも高いものが得られるということです。大変お得な話です。
| インスタンスタイプ | 時間あたりのコスト | 推論のレイテンシー AWS Managed Services | 推論10万回のコスト |
| C5.4XLarge | 0.68 USD | 44.61 | 0.84 USD |
| C5.4XL + EIA.XL | 1.20 USD | 24.89 | 0.83 USD |
| P2.Xlarge | 0.90 USD | 41.10 | 1.03 USD |
| P3.2XLarge | 3.06 USD | 12.31 | 1.05 USD |
すべての可能性を探る
では、EI と追加のインスタンスの組み合わせをさらに詳しく調べてみます。 f C5.Large、C5.Xlarge、C5.2XLarge、C5.4XLarge のインスタンスを、EIA1.Medium、EIA1.Large、EIA1.XLarge の EI アクセラレーターとの組み合わせで最初のスクリプトを再度実行してみると、以下の表の結果になりました。
| ホストのインスタンスタイプ | EI アクセラレータータイプ | 時間あたりのコスト | 推論のレイテンシー AWS Managed Services | 推論10万回のコスト |
| C5.Large | EIA1.Medium | 0.22 USD | 39.00 | 0.23 USD |
| EIA1.Large | 0.35 USD | 25.68 | 0.25 USD | |
| EIA1.XLarge | 0.61 USD | 20.29 | 0.34 USD | |
| C5.XLarge | EIA1.Medium | 0.30 USD | 38.55 | 0.32 USD |
| EIA1.Large | 0.43 USD | 25.99 | 0.31 USD | |
| EIA1.XLarge | 0.69 USD | 21.12 | 0.40 USD | |
| C5.2XLarge | EIA1.Medium | 0.47 USD | 38.56 | 0.50 USD |
| EIA1.Large | 0.60 USD | 26.45 | 0.44 USD | |
| EIA1.XLarge | 0.86 USD | 20.76 | 0.50 USD | |
| C5.4XLarge | EIA1.Medium | 0.81 USD | 39.18 | 0.88 USD |
| EIA1.Large | 0.94 USD | 25.90 | 0.68 USD | |
| EIA1.XLarge | 1.20 USD | 20.34 | 0.68 USD |
この表で、EIA1.Medium (黄色のハイライト) のホストのインスタンスタイプを見ると、結果が似ていることがわかります。これはホスト側での処理はあまりなく、より大きなホストのインスタンスに移行することでは性能が改善しないことを意味します。つまり小さなホストを選択してコストを削減できることを示しています。同様に、一番大きな EIA1.XLarge アクセラレーターを使用するホストのインスタンスすべて (青のハイライト) を見ても、大きな性能の差は見られません。EIA の性能はホストのサイズには制約されないということも確認できます。これはまた、C5.Large ホストのインスタンスタイプを引き続き使用して同様の性能を実現し、コスト削減ができることを意味します。
推論のレイテンシーの比較
これで C5.Large ホストのインスタンスタイプに決定したので、アクセラレーターのタイプを見てみます。推論のレイテンシーに関して、39.18ms から 25.90ms へ、さらに最終的に 20.34ms への向上が見られます。以下のグラフは、前のグラフに様々なアクセラレーターサイズの新しいデータポイントを追加した場合に、得られるもの示しています。
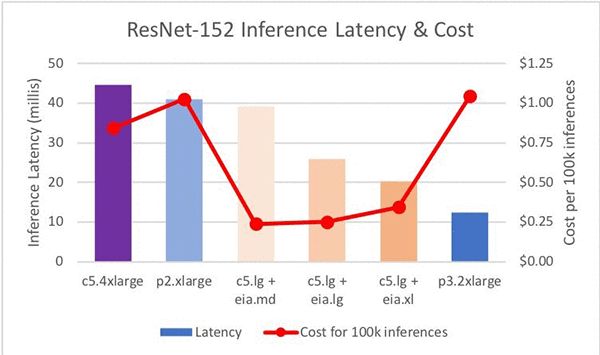
このグラフは、加工されていない性能において、EI アクセラレーターによって P2 と P3 の間にいくつかの段階ができることを示しています。
推論のコスト効率の比較
表の最後の列は組み合わせのコスト効率を示しています。この列を見ると、C5.Large + EIA1.Medium が最もコスト効率が高いことがわかります。純粋に最小コストの比較であれば、C5.4XL および P2/P3 インスタンスと比較した場合、C5.Large + EIA1.Medium の組み合わせが最もコスト効率が良いものです。節約は 71 パーセントから 77 パーセントになります。また、C5.Large + EIA1.XLarge は P2 に対して速度で 2.02 倍の増加であり、C5.4XL に対しては 2.19 倍の増加です (CPU のみ)。節約はそれぞれ 66 と 59 パーセントです。
まとめ
これまでにわかったことは以下の通りです。
- EI アクセラレーターをどのホストのインスタンスタイプと組み合わせても、ホスト計算やメモリー等の量は、構成可能な GPU のメモリーと計算量に応じて選択できる。
- EI アクセラレーターは、P2 インスタンスと同様のメモリーと計算の域を、より少ないコストで提供する。
- EI アクセラレーターは、P2 と P3 インスタンスの間の、加工されていない性能 (推論のレイテンシー) におけるギャップを穴埋めできる。
- EI アクセラレーターは、C5 および P2/P3 インスタンスよりも高いコスト効率を達成できる。
分析により、MXNet はモデルをバインドして多次元配列を作成するためのコンテキストを変更するのと同じように簡単で使いやすいことが分かりました。MXNet の CPU、GPU、および EIA コンテキストでほぼ同じテストスクリプトを使用できるため、テストとパフォーマンス分析を容易に行うことができました。
C5.4XLarge インスタンスで実行する Resnet-152 モデルで、44ms の推論のレイテンシーから始めました。それを C5.Large + EIA.Xlarge に移行することにより、レイテンシーが 20ms に下がりました。 これにより、2.19 倍 高速化し、1 時間あたり 0.07 USD のコスト削減になりました。また、C5.Large + EIA.Medium を使用すると、71% のコスト削減 (100k の推論あたり 0.84 USD 対 0.24 USD) となり、さらに優れたパフォーマンス (44ms 対 39ms) を達成できました。
行動喚起
EI で MXNet を試し、モデルの推論のパフォーマンスを上げながらどの程度のコスト削減が可能か確認できます。下記は、深層学習推論のために設計スペースを分析した際のステップです。使用中のモデルにこのステップを適用することができます。
- CPU コンテキストの推論パフォーマンスを分析するためのテストスクリプトを作成します。
- GPU および EIA コンテキスト用に微調整を加えてスクリプトのコピーを作成します。
- C5、P2、P3 インスタンスタイプでスクリプトを実行してパフォーマンスのベースラインを取得します。
- EIA のパフォーマンスを分析します。
- 最大の EI アクセラレータタイプと大きいホストインスタンスタイプから開始します。
- 小さすぎるコンボを発見できるまで逆行解析を行います。
- 10 万回の推論を実行するためのコストを計算することで、分析にコスト効率を導入します。
モデルの推論のパフォーマンスを改善しながら、どの程度のコスト削減を達成できるでしょうか。 1 セントも追加費用をかけず、モデルの推論のレイテンシーはどの程度改善できますか? コメントセクションで結果を共有しましょう。
著者について
 Sam Skalicky は、高機能の異種コンピューティングシステムの構築を楽しむ AWS 深層学習のソフトウェアエンジニアです。Sam は熱烈なコーヒー愛好家ですが、ハイキングだけは何としてでも行きたくありません。
Sam Skalicky は、高機能の異種コンピューティングシステムの構築を楽しむ AWS 深層学習のソフトウェアエンジニアです。Sam は熱烈なコーヒー愛好家ですが、ハイキングだけは何としてでも行きたくありません。
 Hagay Lupesko は、AWS Deep Learning のエンジニアリングマネージャーです。開発者や科学者がインテリジェントなアプリケーションを実現できるような深層学習ツールの構築に注力しています。余暇には、彼は読書、ハイキング、家族との時間を楽しんでいます。
Hagay Lupesko は、AWS Deep Learning のエンジニアリングマネージャーです。開発者や科学者がインテリジェントなアプリケーションを実現できるような深層学習ツールの構築に注力しています。余暇には、彼は読書、ハイキング、家族との時間を楽しんでいます。