Amazon Web Services ブログ
Amazon Redshiftのワークロード管理(WLM)を使ってミックスワークロードを実行する
ミックスワークロードの環境下では、ビジネス上の要求を満たすために、バッチとインタラクティブのワークロード双方が同時に実行されます。ミックスワークロードを管理し構成するには、アクセスパターンやシステムリソースの使われ方、およびパフォーマンス要件についての詳細な理解が必要です。
ミックスワークロードでは、一般に、一部のプロセスが他より高い優先順位を必要とします。あるケースでは、これはあるジョブが特定のSLA内で完了しなくてはならないことを意味します。別のケースでは、あまりクリティカルではないレポーティングワークロードが一度に多くのクラスターリソースを消費しすぎないようにするだけでよいこともあります。
ワークロード管理(WLM)を利用しない場合、各クエリーは同じ優先順位で処理されます。これによって、あるメンバー、チーム、あるいはワークロードが、他のビジネス上重要なジョブに比べてさほど重要ではない処理のために、大量のクラスターリソースを消費するといった事態が起こり得ます。
このブログポストでは、一般的なWLMパターンに関するガイドラインを提供するとともに、WLMに関連する様々なクエリーとビューを使用して本番ワークロードの構成を最適化する方法について記載します。
ワークロードの概念
WLMを使用して、複数のビジネスワークロードを分離すると共に、システム上で実行される様々なタイプの同時実行クエリ−の優先順位を設定することができます。
- インタラクティブ:実行する人間の入力を受け付けるソフトウェア。インタラクティブなソフトウェアには、BIツールやレポーティングアプリケーションなどのポピュラーなプログラムが含まれます。
- 短時間のみ実行される、読み取り専用のユーザークエリー。低レイテンシーで実行する要件を含むTableauダッシュボードクエリーなどが該当します。
- 長時間実行される、読み取り専用のユーザークエリー。過去10年間の営業データの集計する複雑な構造化レポートなどが該当します。
- バッチ:手動介入を伴わない、サーバープログラム内の一連のジョブの実行(非インタラクティブ)。単一の入力ではなく、複数の入力の集合(”バッチ的な”入力とも言えます)に基づく一連のプログラムの実行は、カスタムジョブと呼ばれます。
- 一括で実行されるINSERT、UPDATE、およびDELETEトランザクションもバッチクエリーに含まれます。ETLやELTプログラムはこの一例です。
Amazon Redshift ワークロード管理(WLM)
Amazon Redshift はスケーラビリティ、セキュリティおよび高パフォーマンスを提供する、ペタバイトスケール・カラムナー・超並列型の、完全に管理されたデータウェアハウスです。Amazon Redshiftは業界標準のJDBC/ODBCドライバーインターフェイスを提供します。これにより、お客様は彼らの既存のBIツールを用いて接続することができ、また既存の分析クエリーを再利用することが可能です。
Amazon Redshiftは様々な種類の分析的データモデルに適合します。例えば、スタースキーマ、スノーフレークスキーマや、 シンプルな非正規化テーブルなどが利用できます。
ワークロードを管理する
Amazon Redshiftワークロード管理は、特定環境下における、様々なサイズと複雑性を持つワークロードの管理を可能にします。WLMの構成はパラメーターグループに含まれ、いくつのクエリーキューが処理に利用可能か、およびそれぞれのキューがどのようにそれらのキューにルーティングされるかを決定します。カスタムパラメーターグループを作成してグループ内の設定を編集し、それをクラスターに関連付けて下さい。以下のような設定が構成可能です。
- それぞれのキュー内でいくつのクエリーが同時に実行可能か
- キュー間でのメモリ配分
- クエリーがどのようにキューにルーティングされるか。誰がクエリーを実行しているか、クエリーレベルは、などの基準
- あるキューにおけるクエリータイムアウト設定
ユーザーがクエリーを実行する際、WLMはそのクエリーを最初にマッチしたキューに割り当てた上で、WLMの構成に基づいてルールを実行します。WLMクエリキュー、同時実行、ユーザーグループ、クエリーグループ、タイムアウト設定、およびキューホッピング機能等の詳細については、クエリーキューの定義を参照して下さい。動的に変更可能な構成プロパティの詳細については、WLM の動的設定プロパティと静的設定プロパティを参照して下さい。
例えば、以下のスクリーンショットのWLM構成では、ETL、BI、およびそれ以外のユーザーをサポートするための三つのキューが構成されています。ETLジョブは長時間実行用のキューに割り当てられ、BIクエリーは短時間実行用のキューに割り当てられます。その他のユーザーのクエリーはデフォルトキューで実行されます。

WLM最適化クラスター構成のガイドライン
1. 複数のビジネスワークロードを分離し、クエリーを互いに独立して実行する。
ダッシュボードクエリーとETLといった異なるビジネスプロセスをサポートするため、互いに独立したキューを作成します。例えば、ワンタイムクエリーのための独立したキューを作成することは、それらのクエリーがより重要なETLジョブを阻害しないようにするための有益なソリューションと言えます。
また、より短時間で実行されるクエリーは一般的にメモリー使用量が少ないため、それらのワンタイムユーザーやクエリーグループ用のキューには、より低いWLM使用メモリー比率(訳者註:マネジメントコンソール上の”メモリ(%)”の設定値)を設定することができます。
2. 同時実行数やメモリー割り当てをアクセスパターンに合わせてローテーションする。(適合するユースケースの場合)
トラディショナルなデータ管理では、ETLジョブはソースシステムから特定のバッチウィンドウ内でデータを取得、整形した後、ターゲットのデータウェアハウスにロードします。このアプローチでは、業務時間中は、BI_USERグループにより多くの同時実行数とメモリを割り当て、ETL_USERには非常に限られたリソースのみを割り当てます。業務時間後は、重くリソースインテンシブなジョブが迅速に完了するよう、ETL_USERへの割り当てを動的に変更またはスイッチすることを、クラスターの再起動なしに行うことが可能です。
注:下記のAWS CLIコマンドサンプルはデモ目的のために、複数の行で表示されています。実際のコマンドは改行を挟まず一行で実行する必要があります。また、下記のJSON構成にはエスケープクォートが必要です。

WLM設定を動的に変更する方法として、AWSはスケジュールされたLambda関数あるいはスケジュールされたデータパイプライン(ShellCmd)をお勧めします。
3. ミックスワークロード(ETLとBIワークロード)を継続的にサポートないし最適化するために、キューホッピングを使用する
WLMキューホッピングは、読み取り専用クエリー(BI_USERのクエリー)が、キャンセルされる代わりにあるキューから別のキューに移動することを可能にします。例えば、以下のスクリーンショットにあるように、二つのキュー(一つはタイムアウトが60秒に設定されたインタラクティブクエリー用のもの、もう一つはタイムアウトなしで設定されたバッチクエリー用のもの)を作成し、同じユーザーグループ(BI_USER)をそれぞれのキューに設定します。WLMは、インタラクティブキューで実行され、タイムアウトしたBI_USERのクエリー(のみ)を、バッチキューに自動的に再ルーティングし再実行します。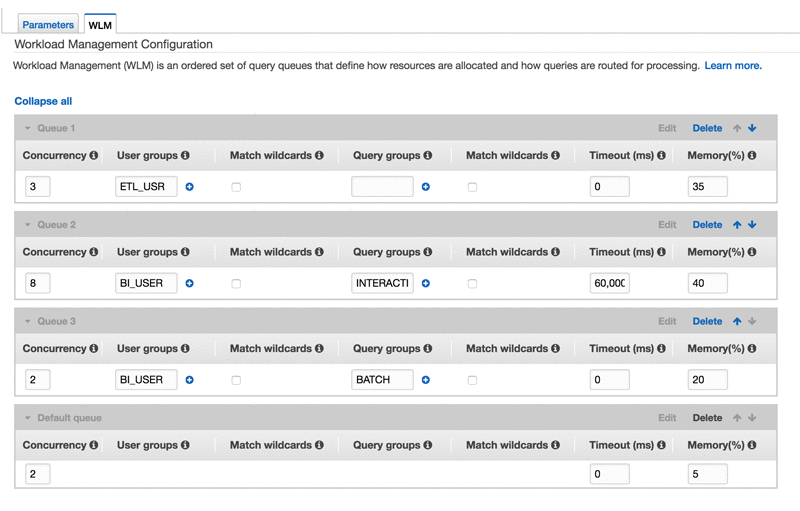
この例では、ETLワークロードはBIワークロードクエリーを阻害しません。長時間実行されている読み取り専用クエリーは、自動的にバッチとして分類され、より短時間で完了するクエリーをブロックしないようになります。
4. リソースインテンシブなETLやバッチクエリー用に、スロットカウントを一時的に増やす。
Amazon Redshiftはメモリー不足エラーを回避するために中間結果をディスクに書きますが、ディスクI/Oはパフォーマンスを劣化させる要因となります。次のクエリーは、ディスク上で実行されているアクティブクエリーを表示します。
SELECT query, label, is_diskbased FROM svv_query_state WHERE is_diskbased = 't';クエリーの結果は以下の通りです。
query | label | is_diskbased
-------+--------------+--------------
1025 | hash tbl=142 | t一般的に、ハッシュ、集計、ソートの操作は、システムが十分なメモリーをクエリー処理に割り当てなかった場合、ディスクにデータを書く可能性が高くなります。この問題を回避するには、その処理が使用するクエリースロットの数を一時的に増やすことで、より多くのメモリーを割り当てます。例えば、同時実行レベルが4であるキューは、4つのスロットを持っています。この時、スロットカウントを4に設定すると、単一のクエリーがそのキューの持つ全ての利用可能メモリーを使うことができるようになります。なお、複数のスロットを単一クエリーに割り当てると、同時実行数が消費され、他のクエリーが実行できなくなり得る点に注意して下さい。
以下の例では、クエリーを実行する前にスロットカウントを4にセットし、クエリー完了後、1に戻しています。
set wlm_query_slot_count to 4;
select
p_brand,
p_type,
p_size,
count(distinct ps_suppkey) as supplier_cnt
from
partsupp,
part
where
p_partkey = ps_partkey
and p_brand <> 'Brand#21'
and p_type not like 'LARGE POLISHED%'
and p_size in (26, 40, 28, 23, 17, 41, 2, 20)
and ps_suppkey not in (
select
s_suppk
from
supplier
where
s_comment like '%Customer%Complaints%'
)
group by
p_brand,
p_type,
p_size
order by
supplier_cnt desc,
p_brand,
p_type,
p_size;
set wlm_query_slot_count to 1; -- after query completion, resetting slot count back to 1
注: 上記のTPC データセットクエリーは例示のみを目的としています。
WLMクエリーの例
以下のサンプルクエリーは、お客様がご自身のワークロードに関してお持ちの、以下のような疑問への回答となるかも知れません。
- 現在のクエリーキュー構成は?クエリースロット数や、それぞれのキューのタイムアウト設定はどうなっているか?
- いくつのクエリーが実行され、キューに到達し、また現在クエリーキュー上で実行されているか?
- 我々のワークロードは、各クエリーキュー上で毎時どの程度滞留しているか?負荷に応じて、構成を変更する必要があるか?
- 我々の既存のWLM構成はどのように動作しているか?どのクエリーキューがビジネス上の要求に対して最適化される必要があるか?
WLMは、内部で定義されたWLM”サービスクラス”に応じて、クエリーキューを構成します。”キュー”と”サービスクラス”の用語は、システムテーブル内でほぼ同義に使われます。
Amazon Redshiftは、WLM構成で定義されたキューと共に、これらのサービスクラスに応じたいくつかの内部キューを作成します。それぞれのサービスクラスは一意のIDを持ちます。サービスクラス1 – 4はシステム用途に予約されています。スーパーユーザーキューはサービスクラス5を使用します。ユーザー定義のキューはサービスクラス6以上を使用します。
クエリー:既存のWLM構成
既存のWLM構成を確認するためには、以下のクエリーを実行します。4つのキューが構成され、それぞれのキューはある数字に割り当てられています。クエリーでは、キュー番号はサービスクラスにマップされ(ETL_USER用の1番目のキューはサービスクラス6にマップされている)、evictableフラグ(*)はfalseに設定されています(クエリータイムアウトが設定されていない)。
*訳者註:evictは“立ち退き”の意で、ここではキューホッピングを意味しています。
select service_class, num_query_tasks, evictable, eviction_threshold, name
from stv_wlm_service_class_config
where service_class > 5;
上記のクエリーは現在のWLM構成についての情報を提供します。このクエリーはLambdaを使用して自動化し、WLMに変更が発生した都度、運用チームに通知を送ることが可能です。
クエリー: キュー状態
キューの状態、各キューに対するメモリー割り当て、および各キューに対して実行されたクエリーをモニタリングするには、以下のクエリーを実行します。このクエリーは、カスタムキューとスーパーユーザーキューについての情報を提供します。
select config.service_class, config.name
, trim (class.condition) as description
, config.num_query_tasks as slots
, config.max_execution_time as max_time
, state.num_queued_queries queued
, state.num_executing_queries executing
, state.num_executed_queries executed
from
STV_WLM_CLASSIFICATION_CONFIG class,
STV_WLM_SERVICE_CLASS_CONFIG config,
STV_WLM_SERVICE_CLASS_STATE state
where
class.action_service_class = config.service_class
and class.action_service_class = state.service_class
and config.service_class > 5
order by config.service_class;
上記の結果からは、サービスクラス9は使用されていないことが伺えます。このことは、デフォルトキューに割り当てるリソース(同時実行数とメモリー)を最小限に押さえることができることを意味します。サービスクラス6(etl_group用)はより多くのクエリーを実行しているため、より多くのメモリーや同時実行数を割り当てることを検討してもよいかも知れません。
クエリー: 前回のクラスター再起動後の状況
前回のクラスター再起動後から現在までに完了または実行中のクエリーの数をサービスクラスごとに確認するには、以下のクエリーを実行します。
select service_class, num_executing_queries, num_executed_queries from stv_wlm_service_class_state where service_class >5 order by service_class;

サービスクラス9は使用されていません。サービスクラス6(etl_group用)は他のサービスクラスより多くのクエリーを実行しています。クエリー処理を高速化するために、このグループ用のメモリーや同時実行数を変更することを検討した方がよいでしょう。
クエリー: 各WLMキューの時間ごとのワークロード
各WLMクエリーキューの時間ごとのワークロードを確認するには、以下のクエリーを実行します。このクエリーを使用して、WLMキューの最適化を行うことが可能です。少なすぎるスロットや多すぎるスロットを含んだキューは、WLMでのキューイングや、未使用のクラスターメモリーに繋がります。このクエリー(wlm_apex_hourly.sql)は、amazon-redshift-utils GitHubレポジトリーからコピーできます。
WITH
-- Replace STL_SCAN in generate_dt_series with another table which has > 604800 rows if STL_SCAN does not
generate_dt_series AS (select sysdate - (n * interval '1 second') as dt from (select row_number() over () as n from stl_scan limit 604800)),
apex AS (SELECT iq.dt, iq.service_class, iq.num_query_tasks, count(iq.slot_count) as service_class_queries, sum(iq.slot_count) as service_class_slots
FROM
(select gds.dt, wq.service_class, wscc.num_query_tasks, wq.slot_count
FROM stl_wlm_query wq
JOIN stv_wlm_service_class_config wscc ON (wscc.service_class = wq.service_class AND wscc.service_class > 4)
JOIN generate_dt_series gds ON (wq.service_class_start_time <= gds.dt AND wq.service_class_end_time > gds.dt)
WHERE wq.userid > 1 AND wq.service_class > 4) iq
GROUP BY iq.dt, iq.service_class, iq.num_query_tasks),
maxes as (SELECT apex.service_class, trunc(apex.dt) as d, date_part(h,apex.dt) as dt_h, max(service_class_slots) max_service_class_slots
from apex group by apex.service_class, apex.dt, date_part(h,apex.dt))
SELECT apex.service_class, apex.num_query_tasks as max_wlm_concurrency, maxes.d as day, maxes.dt_h || ':00 - ' || maxes.dt_h || ':59' as hour, MAX(apex.service_class_slots) as max_service_class_slots
FROM apex
JOIN maxes ON (apex.service_class = maxes.service_class AND apex.service_class_slots = maxes.max_service_class_slots)
GROUP BY apex.service_class, apex.num_query_tasks, maxes.d, maxes.dt_h
ORDER BY apex.service_class, maxes.d, maxes.dt_h;本ポストの主旨に基づき、結果はサービスクラスごとにブレイクダウンされています。

上記の結果からは、サービスクラス6が24時間を通じて、コンスタントに最大8までのスロットを消費していることが伺えます。この数字を見る限り、このサービスクラスへの変更は現時点では特に必要ありません。

サービスクラス7は、上記の結果に基づき最適化することが可能です。
二つの点が観察できます。
- 朝6時から午後3時まで、あるいは午後6時から翌朝6時まで:消費されている最大スロットは3です。これらのアクセスパターンに基づいて、同時実行数とメモリー割り当てをローテーションする余地があります。リソースのローテーションについて詳しくは、本ポストのガイドラインセクションの項を参照して下さい。
- 午後3時から午後6時まで:この期間にピークの発生が観察されます。この時間帯については、現在の設定のままで構いません。
まとめ
Amazon Redshiftは強力かつ完全に管理されたデータウェアハウスであり、高いパフォーマンスと低いコストの双方をクラウド上でご提供します。WLM機能を用いることで、クラスター上で動作する異なるユーザーとプロセスが、それぞれのパフォーマンスとスループットを最大化するための適切な量のリソースを得られることを担保することができます。
ご質問やご提案がありましたら、以下にコメントを残していただけますと幸いです。
著者について
 Suresh AkenaはAWS Professional ServiceのシニアBig Data/ITトランスフォーメーションアーキテクト。SureshはAWSプラットフォームへのマイグレーション、ビッグデータ、分析プロジェクトを含む巨大データストラテジーのリーダーシップをエンタープライズカスタマーに提供し、AWSを使ったデータドリブンアプリケーションの最適化や市場に出るまでにかかる時間の改善を支援しています。余暇には8才と3才の娘達と遊び、映画を楽しんでいます。
Suresh AkenaはAWS Professional ServiceのシニアBig Data/ITトランスフォーメーションアーキテクト。SureshはAWSプラットフォームへのマイグレーション、ビッグデータ、分析プロジェクトを含む巨大データストラテジーのリーダーシップをエンタープライズカスタマーに提供し、AWSを使ったデータドリブンアプリケーションの最適化や市場に出るまでにかかる時間の改善を支援しています。余暇には8才と3才の娘達と遊び、映画を楽しんでいます。
(翻訳はプロフェッショナルサービス仲谷が担当しました。原文はこちら)