Amazon Web Services ブログ
Amazon SageMaker で DeepChem を使用して、仮想スクリーニングを行う
仮想スクリーニングは、膨大な量の分子ライブラリを検索して、ターゲット特性を示す可能性が最も高い構造を特定することにより、薬物または物質の発見に用いられる計算手法です。
利用できる計算時間の急激な増加とシミュレーションの絶え間ない改善により、仮想スクリーニングは分子発見のための画期的なツールになりつつあります。
ディープラーニングテクノロジーは、この計算仮想コンパウンドスクリーニングで広く使用されており、そのようなテクノロジーは飛躍的に進化しています。DeepChem は最も人気のあるオープンソースツールの 1 つで、創薬、物質科学、量子化学、生物学においてディープラーニングを広く利用できるようにしています。詳細については、GitHub の「創薬、量子化学、物質科学および生物学のためのディープラーニングの民主化」をご参照ください。
この記事では、DeepChem を Amazon SageMaker で使用する方法について説明します。Amazon SageMaker は、機械学習 (ML) モデルをすばやく簡単に構築、トレーニング、デプロイできるようにする完全マネージド型のサービスです。ML は、モデルを構築し、トレーニングし、本番環境にデプロイするプロセスが複雑で時間がかかるため、本来よりも難しいと感じることが多々あります。Amazon SageMaker はその複雑さを軽減します。
Amazon SageMaker で DeepChem をインストールする
DeepChem をインストールするには、AWS アカウントをセットアップし、最初の Amazon SageMaker ノートブックインスタンスを作成します。次の手順を実行します。
- AWS アカウントがまだない場合は、AWS アカウントを作成します。
AWS にサインアップすると、AWS アカウントは Amazon SageMaker を含むすべての AWS のサービスに自動的にサインアップされます。請求は、利用したサービスに対してのみ行われます。Amazon SageMaker を初めて使用する場合は、「Amazon SageMaker の仕組み」をご参照ください。
- Amazon SageMaker コンソールで、[Notebook instances] を選択します。
- [Create notebook instance] を選択します。
- Notebook instance settings の Notebook instance name に、インスタンスの名前を入力します。この記事では
deepchemという名前を使用します。 - Notebook instance type には、希望するインスタンスタイプを入力します。この記事では
mL.t3.xlargeを使用します。 - Elastic Inference では、[None] を選択します。
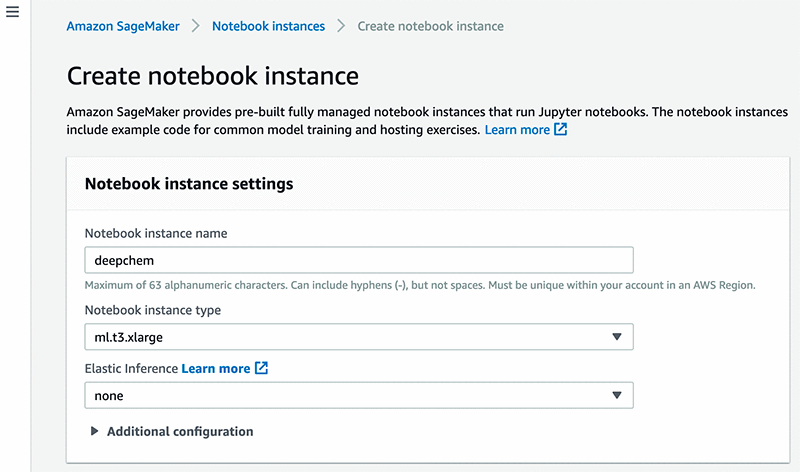
詳細については、「ステップ 2: Amazon SageMaker ノートブックインスタンスの作成」をご参照ください。
上記の手順を完了してノートブックインスタンスを作成すると、Amazon SageMaker は ML コンピューティングインスタンスを起動します。Notebook インスタンスには、事前設定された Jupyter Notebook サーバーと Anaconda ライブラリのセットがあります。
- ノートブックインスタンスのステータスが
InServiceの場合、[Open Jupyter] を選択します。
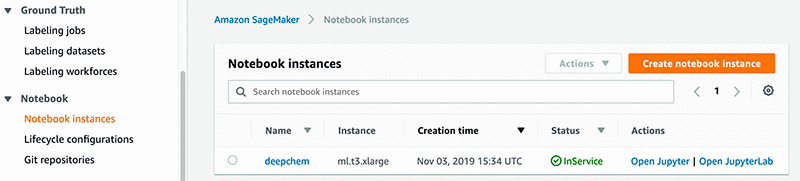
Jupyter ノートブックサーバーページが表示されます。
- New ドロップダウンメニューから、[Terminal] を選択します。

- 端末で次のコードを使用して Conda を更新します。
これで、DeepChem をインストールする準備ができました。
- 端末で次のコードを実行します。
- 次のコードを使用して、DeepChem Notebook カーネルを作成および確認します。
- ターミナルと Jupyter ホームウィンドウを閉じます。
Jupyter がドロップダウンメニューを再作成するには、数分かかる場合があります。
DeepChem インストールをテストする
DeepChem インストールをテストするには、次の手順を実行します。
- Amazon SageMaker コンソール で、[Open Jupyter] を選択します。
- Jupyter ダッシュボードの New ドロップダウンメニューから、[
conda_deepchem] を選択します。
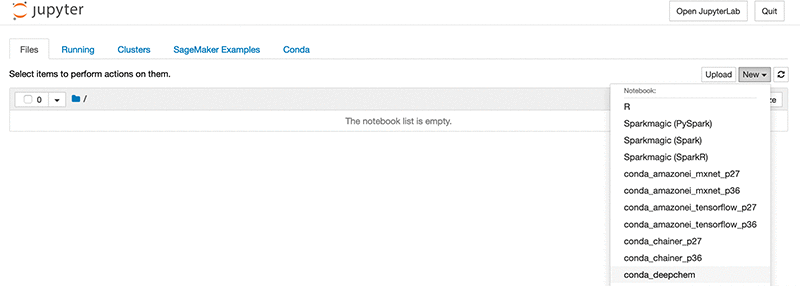
DeepChem が正しくインストールされたことを確認するには、ノートブックセルに次のコードを入力します。
DeepChem を実行する
これで、DeepChem を Amazon SageMaker ノートブックインスタンスの Jupyter Notebook アプリで使用できるようになりました。次の Python コードの例は、不確実性の推定値を生成します。詳細については、「ディープラーニングの不確実性」をご参照ください。データセットをロードし、モデルを作成し、トレーニングセットでトレーニングし、テストセットで出力を予測できます。次のコードを参照してください。
次の出力が表示され、y_pred および y_std の予測結果を確認できます。
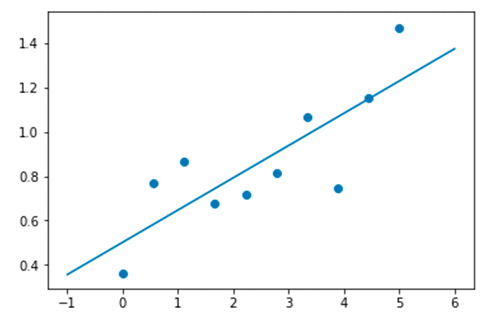
この 2 番目の例では、次のコードは 10 個のデータポイントのセットに対する最適な線形回帰を示しています。
結果として次のグラフが表示されます。
まとめ
この記事では、DeepChem を Amazon SageMaker にインストールし、DeepChem ウェブサイトで提供されるテストを実行して検証する方法を示しました。独自のコードを実行するか、さらに DeepChem チュートリアルを試してみてください。詳細については、DeepChem ウェブサイトの「チュートリアル」をご参照ください。チュートリアルでは、DeepChem のさまざまな側面や機能を紹介しています。チュートリアルは Jupyter (IPython) ノートブックでインタラクティブに実行できます。ノートブックファイルをダウンロードして、Amazon Sagemaker で開くこともできます。
何かご質問がある場合は、コメントに記入してください。
著者について
 Seongik Hong は、共有配信チームのクラウドインフラストラクチャアーキテクトです。自身の役割の中で、彼は自己の経験を活かし、人々が AWS により提供されるサービスを利用してアイデアを実現するのをサポートをしています。余暇には、クラウドコンピューティングが化学情報学にどのように役立つかを色々試してみることを楽しんでいます。
Seongik Hong は、共有配信チームのクラウドインフラストラクチャアーキテクトです。自身の役割の中で、彼は自己の経験を活かし、人々が AWS により提供されるサービスを利用してアイデアを実現するのをサポートをしています。余暇には、クラウドコンピューティングが化学情報学にどのように役立つかを色々試してみることを楽しんでいます。