Amazon Web Services ブログ
AWS でのビジュアル検索 – パート 1: Amazon SageMaker を使用したエンジンの実装
音声やテキストは使わずに、見つけたいものを表示することでビジュアル検索を行う。古いことわざにもあるように、「絵は千語の価値がある」と言います。 たいていは、実際の例や画像を示す方が、検索エンジンが効率的に探し出せる言葉で説明するよりも簡単です。専門的な用語を使って説明するだけの知識や理解が十分でないユーザーもいるからです。他にも、画像か動画データを使って検索を使いたいが、ビジュアル検索だと、取り込みが早すぎてラベルやメタデータを正確に割り当てられない、という場合があります。
ビジュアル検索を使って、ハードウェアストアで交換部品を探す、という小売業での例を見てみましょう。専門知識がないと難しい用語を使って部品を識別するのではなく、深層学習を利用できるビデオカメラの AWS DeepLens に部品をただ見せるだけです。するとデバイスは、視覚的に類似している部品の一覧と、それらが置いてある店舗内の場所を提示するのです。似たようなアイテムを購入したい場合、顧客が自宅に AWS DeepLens デバイスを持っていれば、家にあるアイテムをデバイスに見せるだけで済みます。ビジュアル検索の利点は、アイテムを示すだけで済むところでしょう。バーコード、QR コード、製品名、製品メタデータなど、他のデータは一切必要ありません。
このブログ記事は 2 部に別れており、Amazon SageMaker と AWS DeepLens を通して、ビジュアル検索を実装する方法を学びます。パート 1 では、ビジュアル検索の仕組みを学びながら、Amazon SageMaker を使ってビジュアル検索のモデルを構築していきます。Amazon SageMaker を使用して、検索対象の参照アイテムを含む高速インデックスを作成します。パート 2 では、AWS DeepLens を使用して、パート 1 の結果を、デジタル上から実際の利用へと広げていきます。現行のビジュアル検索用アプリケーションはほとんどどれも、リアルタイムでの物理の世界とのやり取りを直接行わず、ウェブサイトやアプリケーションといったデジタルの世界にある静止画像を取り込みます。パート 2 では、AWS DeepLens デバイスを使用して、物理的対象に視覚的に類似するアイテムをリアルタイムで直接検索する方法を示し、デジタルから物理世界への橋渡しを行います。このブログポストシリーズに関連するノートブックは、github.com/awslabs/visual-search/tree/master/notebooks にあります。
ビジュアル検索のしくみ
異なるアルゴリズムをいくつか適用することで、ビジュアル検索を実行します。このブログ記事では、1100 万を超える画像がある有名な ImageNet データセット上であらかじめトレーニングした Convolutional Neural Net (CNN) モデルを使って、画像から特徴を抽出します。Babenko 氏ら (2014) による「画像修正のためのニューラルコード。」など複数の研究論文で、あらかじめトレーニングされた CNN を使用して画像から特徴を抽出するという考えが研究されています。CNN は、色、テクスチャ、形状などを検出し、画像から特徴を抽出します。得られた特徴を元のイメージよりもはるかに低い次元空間で定義するので、視覚的に最も類似したマッチングを見つける際に、イメージ間の比較がより容易となります。
通常、あらかじめトレーニングした CNN だと、自動車、テーブル、掃除機などの異なるカテゴリーに画像を分類するラベルを出力します。ですので、事前にトレーニングしてある CNN を使用するには、修正する必要があります。具体的には、画像から特徴を抽出するように修正します。普通、最後に完全に接続したレイヤーの前のレイヤーを出力として使用できるように、CNN を修正します。このレイヤーの出力は、画像の特徴を要約する「特徴ベクトル」と考えることができます。クエリアイテムの画像を与えられてビジュアル検索を実行するには、クエリの特徴ベクトルを生成し、参照アイテムの特徴ベクトルのインデックスに対して検索が行われます。次の図が、このことを説明しています :

事前にトレーニングしたモデルを使用する大きな利点は、ラベル付きトレーニングデータを収集して新しいモデルをトレーニングすることに伴う時間とコストを回避できるという点です。フィーチャライゼーション (特徴表現) プロセスは、モデルトレーニングよりもはるかに高速で行えます。これは、フィーチャライゼーションが、各参照データアイテムに対して、モデル内の順方向パスを 1 つしか含まないからです。このプロセスには、通常トレーニングで行われる、計算集約型の反順方向パス勾配計算は含まれません。
参照アイテムデータセットのデータ収集だけは、実行する必要があります。その後に、特徴ベクトルセットへと変換されます。データ収集の一例として、小売店を考えてみましょう。小売店が収集する必要があるデータは、販売したアイテムを表す参照画像のセットと、製品タイトル、画像 URL などの画像に関する関連メタデータだけです。CNN モデル自体にとって基礎となる「データセット」は、 ImageNet データセットのみで、多くの場合、特徴を抽出するのに十分なバリエーションを持ちます。しかし、参照アイテムの画像は、クラスを区別する小さな差異によって高度に特殊化されているか、あるいは ImageNet データセットから分岐しているので、CNN モデルを微調整してこうした特殊な画像を説明するとよい場合があります。
モデルの作成と、参照アイテムのフィーチャリング
ビジュアル検索で使用するモデルを作成するプロセスには、いくつかのステップがあります。まず最初に、ImageNet データセット上に CNN モデルを含むあらかじめトレーニングしたモデルの「 model zoo 」を関連付けた深層学習フレームワークを選びましょう。このブログ記事シリーズでは、深層学習フレームワークとして Apache MXNet を使用します。MXNet Model Zoo では、コンテストで受賞した ResNet アーキテクチャに基づくトレーニング済みモデルを使用します。このモデルは、ImageNet データセットにある 1100 万を超える画像を高精度で分類しています。
モデルの作成に関するステップと関連ソースコードはすべて、このブログ記事シリーズに関する Jupyter ノートブックにあります。ノートブックは、このプロジェクトの GitHub リポジトリ (github.com/awslabs/visual-search/notebooks) からアクセスできます。ステップは、以下のようになります。
- MXNet Model Zoo からトレーニング済み CNN モデルをインポートします。
- 最初に完全に接続したモデルのレイヤーへのリファレンスを、その畳み込みレイヤーの後に取得します。
- そのレイヤーを出力としたモデルの新しいバージョンを保存します。
これらのステップを実行すると、修正したモデルの出力レイヤーが、画像を分類するためのラベルの代わりに、特徴ベクトルを生成します。特徴ベクトルは、簡単な浮動小数点数のベクトルです。例えば、出力として完全に接続したレイヤーを選んだ場合、152 層を有する ResNet CNN から生成された特徴ベクトルは、2048 個の要素を含むことが可能です。一方、18 層の RestNet CNN の場合、512 個の要素を有します。CNN レイヤーおよび特徴ベクトル要素が少ないと、その分情報は失われますが、特徴ベクトル生成およびその後のインデックス検索段階の両方において、より高速な計算が可能となります。
フィーチャライザーモデルが完成したところで、次に、リファレンスアイテムデータセットをフィーチャリングしましょう。先に説明したように、これは、モデル内の順方向パスを介して各画像を送り、特徴ベクトル出力を得ることを含みます。このプロジェクトの Jupyter ノートブックでは、このプロセスを、Amazon.com の製品画像の小さなサンプルデータセット用として実行します。 他にも、J. McAuley 氏らによる論文で参照されているような「スタイルと代入に関する画像ベースのレコメンド。 (2015) 」、Amazon.com の製品画像の大きなデータセットを試すこともできます。視覚的に類似したリファレンスアイテムを高速検索できるように、結果の特徴ベクトルをインデックスに挿入します。次に、使用可能なインデックスについて、ある 1 つのタイプを説明します。
Amazon SageMaker k-NN アルゴリズムでの、類似アイテムのインデックス作成
特徴ベクトルを生成するフィーチャライザーモデルは、ビジュアル検索の中核となる要素のうちの 1 つにすぎません。リファレンスアイテムの特徴ベクトルは、通常、オフラインで生成されるため、効率的に検索できるように保存する必要があります。小さなリファレンスアイテムデータセットの場合、クエリをすべての参照アイテムと比較する、総当たり線形検索を使用することができます。しかし、総当たり検索が非常に遅くなる大規模なデータセットでは、実行は難しいでしょう。従って、ビジュアル検索において中心的な要素は、リファレンスアイテム特徴ベクトルの高速インデックスとなります。
視覚的に類似した画像を効率的に検索するために、Amazon SageMaker k-Nearest Neighbors (k-NN) アルゴリズムを使用します。k-NN アルゴリズムを用いたトレーニングの主な目的は、インデックスを構築することです。このインデックスで、ユークリッド距離またはコサイン類似性などの距離メトリックによって「近隣」であると測定されたアイテムを、効率的に検索することを可能にします。検索時には、インデックスで、サンプルクエリアイテムの k 最近傍をクエリします。ビジュアル検索では、修正した CNN モデルを使用してクエリ画像がフィーチャリングされます。また、結果として得られる特徴ベクトルは、参照アイテムの特徴ベクトルの k-NN インデックスにおける視覚的に類似したマッチングを検索するために使用されます。
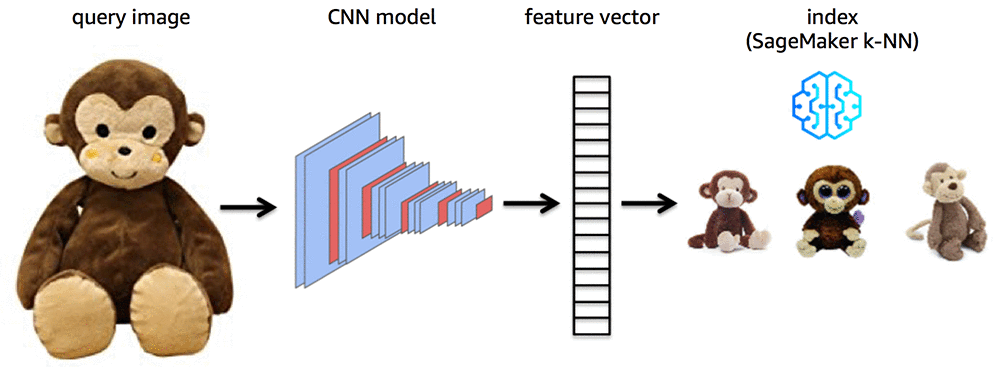
ビジュアル検索以外のユースケースでは、k-NN アルゴリズムの近傍は、通常、分類 (クラスラベル上の近隣の多数決による) 、または回帰 (近傍の平均による) のいずれかに使用されることに留意しましょう。一方で、ビジュアル検索のユースケースでは、これらの最近傍を、視覚的にクエリ画像と最も類似したマッチングとして直接使用します。前の図で示されているように、ビジュアル検索では、最も関心があると思われるアイテムの検索を絞り込むことができます。対照的に、機能ベクトルではなく分類カテゴリを出力する未修正の ResNet を使用すると、関連性の低い数百または数千のアイテムを含む一般的なカテゴリが返されてしまいます。
ノートブックコードを読みやすく簡潔に保つため、k-NN トレーニングジョブを、Amazon SageMaker Python SDK を使用して作成します。この SDK は、多くのヘルパーメソッドと便利性を備えています。SDK には、k-NN トレーニングジョブの設定の下位レベルの詳細を抽象化する、特定の KNN Estimator オブジェクトが用意されています。k-NN トレーニングジョブでインデックスを構築した後、Amazon SageMaker Predictor API の冗長形式を使用して、k-NN インデックスをホストする SageMaker エンドポイントから近傍を取得する必要があります。 次のコードスニペットは、リクエストの Accept ヘッダーを使った冗長 API を呼び出す方法を示しています。また、入力クエリ画像の特徴ベクトルのための CSV シリアライザー、SageMaker エンドポイントから返された応答のための JSON デシリアライザー、およびトレーニングのための KNN エスティメーターなど、数々の SDK の便利性をうまく利用する方法も示しています。
次のステップ
これまで、ビジュアル検索のユースケースを検討しながら、ビジュアル検索がどのように機能するかについて、詳しく見てきました。さらに、ビジュアル検索のフィーチャライザーモデルの準備方法、参照アイテムのデータセットをフィーチャリングし、特徴に関するインデックスを作成、それらに対してクエリを実行する方法についても学びました。
このブログ記事のパート 2 では、AWS DeepLens を使って、ビジュアル検索を実装する方法について説明します。ご期待下さい!
今回のブログ投稿者について
 Brent Rabowsky は、AWS のデータサイエンスの専門家で、AWS のお客様のデータサイエンスプロジェクトをお手伝いしています。
Brent Rabowsky は、AWS のデータサイエンスの専門家で、AWS のお客様のデータサイエンスプロジェクトをお手伝いしています。