Amazon Web Services ブログ
AWS Glue のパーティション分割されたデータを使用した作業
AWS Glue は、Hive 形式で整理されたデータセットの高度な取扱いをサポートします。AWS Glue クローラーは、自動的に Amazon S3 データのパーティションを識別します。AWS Glue ETL (Extract/Transform/Load) ライブラリは、DynamicFrame を取り扱う際、ネイティブでパーティションをサポートします。DynamicFrame はデータの分散コレクションを表します。スキーマを指定する必要はありません。DynamicFrame の作成時に述語をプッシュダウンしてパーティションをフィルタリングし、高コストの S3 への呼び出しを回避できます。また、Apache Spark DataFrame に変換することなく直接パーティショニングされたディレクトリに書き込む機能のサポートを追加しました。
パーティショニングは、データセットを様々なビッグデータシステムで効率的にクエリできるように、それらを整理するための重要な手法となっています。データは、ひとつまたは複数の列の重複しない値に基づいて、階層ディレクトリ構造にまとめられます。たとえば、Amazon S3 のアプリケーションログを、年別、月別、日別の内訳で日付ごとにパーティショニングするとします。すると、1 日分に相当するデータがs3://my_bucket/logs/year=2018/month=01/day=23/のようなプレフィックスの下に配置されます。
Amazon Athena、Amazon Redshift Spectrum、AWS Glue などのシステムでは、これらのパーティションを使用して値ごとにデータをフィルタリングできるため、Amazon S3 への不要な呼び出しを行う必要がありません。このため、読み取る必要のあるパーティションが少ないアプリケーションのパフォーマンスが大幅に改善します。
本投稿では、AWS Glue を使用してパーティショニングされたデータセットを効率的に処理する方法を紹介します。まず、クローラーを設定して、パーティショニングされたデータセットを自動的にスキャンし、AWS Glue データカタログにテーブルとパーティションを作成する方法を説明します。次に、パーティショニングされたデータを取り扱うための AWS Glue ETL ライブラリの機能をいくつか紹介します。SQL 式やユーザー定義の関数を使用してパーティションをフィルタリングし、Amazon S3 からの不要なデータのリスト作成や読み取りを回避することができます。また、ETL ライブラリでは、Spark SQL DataFrame に依存することなく、AWS Glue DynamicFrame をパーティションに直接記述する機能のサポートを追加しました。
それでは、始めましょう。
パーティショニングされたデータのクローリング
この例では、以前の AWS Glue の Scala サポートに関する投稿で紹介したものと同じ GitHub アーカイブのデータセットを使用します。このデータは GitHub アーカイブ で一般公開されており、GitHub サービスに対するすべての API リクエストのための JSON レコードを含んでいます。2017 年 1 月からの 1 か月分のアクティビティを含むサンプルデータセットは以下の場所で入手可能です:
<region> の箇所は、 us-east-1 など、利用中の AWS リージョンに置き換えます。このデータセットは年別、月別、日別にパーティショニングされているため、実際ファイルのパスは以下のようになります:
このデータをクロールするには、AWS Glue 開発者ガイド の説明に従うか、提供された AWS CloudFormation テンプレートを使用します。このテンプレートでは、以下のような内容を含むスタックを作成します:
- AWS Glue リソースにアクセスする権限を持つ IAMロール
- githubarchive_month という名前の AWS Glue データカタログのデータベース
- GitHub データセットをクロールするクローラーの設定
- AWS Glue 開発エンドポイント (次のセクションでデータ変換に使用します)
このテンプレートを実行するには、次のセクションで出力データを書き込む S3 バケットとプレフィックスを提供する必要があります。このテンプレートで作成するロールは、このバケットのみに書き込む権限を持ちます。また、開発エンドポイントに接続するため SSH 公開鍵を提供する必要があります。SSH の鍵作成について詳しくは、開発エンドポイントチュートリアルをご覧ください。AWS CloudFormation スタックの作成後、AWS Glue コンソールからクローラーを実行できます。
クローラーはタイプやスキーマを推論することに加え、自動的にデータセットのパーティション構造を識別し、AWS Glue データカタログに入力します。これでデータが正確にグループ化されて論理テーブルとなり、パーティション列が AWS Glue ETL ジョブや Amazon Athena などのクエリエンジンのクエリで利用可能な形になります。
テーブルをクロールした後は、AWS Glue コンソールでテーブルに移動し、 [View partitions (パーティションを表示)] を選択してパーティションを表示できます。パーティションは以下のように表示されます:
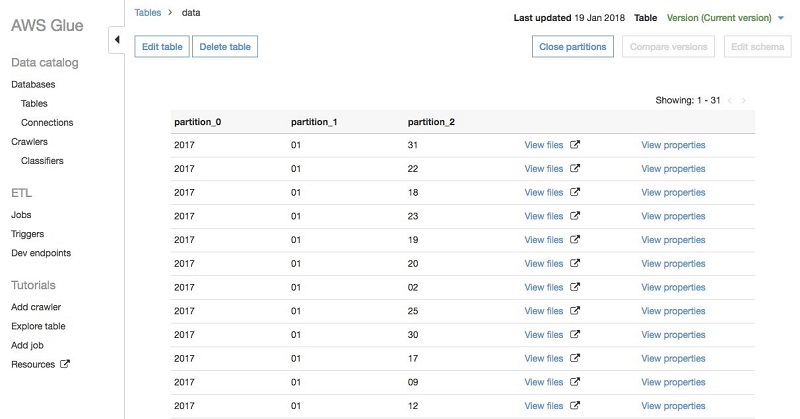
Hive 形式では、 key=val フォームのパーティショニングされたパスについてはクローラーが自動的に列の名前を入力します。この場合は、GitHub データが 2017/01/01 の形式のディレクトリに保存されているため、クローラーは partition_0、 partition_1 などのデフォルトの名前を使用します。これらの名前は AWS Glue コンソールで簡単に変更できます。テーブルに移動し、 [Edit schema (スキーマを編集)] を選択して、partition_0 を year、partition_1 を month、partition_2 を day に変更します:
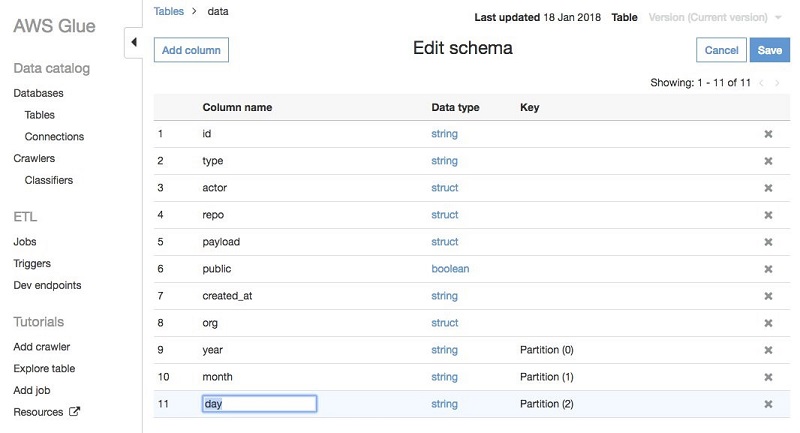
データセットをクロールし、パーティションに適切な名前を付けました。ここで AWS Glue ETL ジョブのパーティショニングされたデータの取り扱い方を見てみましょう。
データの変換とフィルタリング
まず AWS Glue ETL ライブラリについては、AWS Glue 開発エンドポイントと Apache Zeppelin ノートブックを使用することができます。AWS Glue 開発エンドポイントでは、Apache Spark および AWS Glue ETL ライブラリを使用してスクリプトを構築、実行する対話型環境を提供します。これはデバッグと探索的解析に役立ちます。また繰り返しのジョブに移行する前にスクリプトを開発、テストするために使用できます。
前のセクションで AWS CloudFormation テンプレートを実行した場合は、アカウントに partition-endpoint という名前の開発エンドポイントがすでにあるはずです。または、こちらの開発エンドポイントチュートリアルの説明に従って作業することもできます。いずれの場合も、ローカルまたは EC2 インスタンスで Apache Zeppelin ノートブックを設定する必要があります。開発エンドポイントおよびノートブックについて詳しくは、AWS Glue 開発者ガイドをご覧ください。
以下の例はすべてプログラミング言語 Scala で記述されていますが、わずかな変更ですべて Python に実装可能です。
パーティショニングされたデータセットを読み取る
最初にデータセットを読み取り、パーティションがどのようにスキーマに反映されるのか確認しましょう。 まず、この例で必要になるクラスをいくつかインポートし、GlueContext を設定します。これはデータの読み取り、書き込みに使用するメインのクラスです。
Zeppelin の パラグラフ で以下の内容を実行します。パラグラフとは実行可能なコードの単位です:
これは単純ですが、2 つ注意点があります: まず、各パラグラフは、Scala であることを示すため、 %spark という行で始める必要があります。2 点目は、シリアライゼーションの問題を回避するため、 spark 変数には @transient を付ける必要があることです。これは Zeppelin ノートブックで実行する場合のみ必要となります。
次に、GitHub データを DynamicFrame に読み込みます。これは AWS Glue スクリプトで使用される主要なデータ構造で、データの分散コレクションを表しています。DynamicFrame は Spark DataFrame に似ていますが、ETL 変換のための追加機能がある点が異なります。 DynamicFrames については、AWS Glue が Scala スクリプトをサポートおよび AWS Glue API ドキュメントの投稿で詳しく説明されています。
以下のスニペットは、先程クロールしてスキーマをプリントしたデータカタログのテーブルを参照して DynamicFrame を作成します:
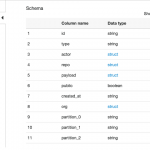
また、 githubEvents.printSchema() を使用してスキーマ全体をプリントすることもできます。ただし今回はスキーマ全体がかなり大きいため、トップレベルの列のみプリントしました。このパラグラフは、標準的なサイズの AWS Glue 開発エンドポイントで実行に 5 分ほどかかります。実行後、以下のような出力を確認できます:
id: string
type: string
actor: struct
repo: struct
payload: struct
public: boolean
created_at: string
year: string
month: string
day: string
org: struct
各レコードに、 year、month、day のパーティション列が自動的に追加されています。
パーティション列によるフィルタリング
データをパーティショニングする理由のひとつは、パーティションのサブセットでの作業を簡単にすることです。パーティション列によるデータのフィルタリング方法を見てみましょう。ここでは GitHub の週末のアクティビティを参照して、ユーザーが自由時間に何を作っているのか見てみることにします。これを行うには、対象のイベントを選択するため事前に作成した githubEvents DynamicFrame でフィルター変換を使用するという方法があります:
このスニペットでは、Java の Calendar クラスを使用する filterWeekend 関数を、パーティション列 (year、month、day) が週末になるレコードを識別するよう定義しています。 このコードを実行すると、全 29,160,561 イベント中、2017 年 1 月の週末には 6,303,480 の GitHub イベントが発生していたことがわかります。これは順当な結果のようです。イベントの約 22 パーセントが週末に発生し、その月の日の約 29 パーセント (31 日中 9 日) が週末に当たるためです。つまり、GitHub ユーザーは週末の利用がやや少ないものの、たくさんのアクティビティがあるということです。
パーティション列で述語をプッシュダウン
フィルター変換をこのように使用する場合の主な問題点は、ごく一部のみが必要であっても、Amazon S3 のデータセットのファイルをすべてリストし、読み取る必要があることです。1 か月分のデータなら対処できるでしょう。しかし、さらに多量のデータを処理する場合、読み取ってはすぐに廃棄するレコードに時間を費やすばかりになります。
この問題に対処するため、最近のリリースでは AWS Glue データカタログで指定されたパーティション列での述語のプッシュダウンがサポートされました。クラスター内のエグゼキューターでデータを読み取り DynamicFrame をフィルタリングする代わりに、カタログで利用可能なパーティションのメタデータに直接フィルターを適用します。こうすることで、処理が必要な S3 パーティションのみをリストし、読み取ることができます。
これを行うには、Spark SQL 述語を追加パラメータとして getCatalogSource メソッドに指定します。この述語は、フィルタリングするパーティション列のみを使っていれば、SQL 式 でも ユーザー定義の関数でも構いません。これはカタログに保存されたメタデータに適用することに注意してください。スキーマのその他のフィールドにはアクセス権がありません。
以下のスニペットでは、この機能を使用して週末に発生するパーティションのみを読み取る方法を示しています:
ここでは、SparkSQL 文字列の concat 関数を使用して、日付の文字列を構築しています。その文字列を to_date 関数を使用して日付オブジェクトに変換し、 date_format 関数を使用して「E」パターンで日付を 3 文字の曜日 (Mon、Tue など) に変換します。これらの関数や Spark SQL 式、ユーザー定義関数全体について詳しくは、 Spark SQL ドキュメントおよび関数一覧をご覧ください。
なお、 pushdownPredicate パラメータは Python でも利用可能です。Python の対応する呼び出しは以下の通りです:
述語のプッシュダウンによるパフォーマンスの影響は、各 Zeppelin パラグラフ用にレポートされる実行時間で確認できます。Scala フィルター関数を使用した最初のアプローチでは 2 分半かかりました。
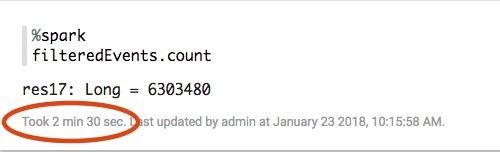
このバージョンではプッシュダウンリストを使用しており、データ読み取り量がはるかに少ないため、完了まで わずか 24 秒でした。5 倍の高速化です。
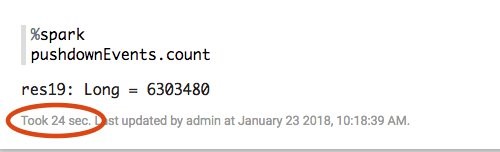
もちろん、これが役立つかどうかはフィルターの設定次第です。除外するパーティションが多いほど、さらに改善が見られるでしょう。
Amazon S3 パスの Hive 形式パーティショニングに加え、Parquet と ORC ファイル形式で各ファイルをパーティショニングし、列の値を示すデータブロックにできます。各ブロックは、列の最大値/最小値など、中に含むレコードの統計データも保存します。AWS Glue は、Hive 形式パーティションとこれらの形式のブロックパーティション両方の述語プッシュダウンをサポートしています。データ読み取り中、不要な S3 パーティションを切り詰め、Parquet および ORC 形式の列統計データで読み取り不要とされたブロックをスキップします。
追加の変換
これでデータセットの読み取りとフィルタリングが完了したため、追加の変換でデータを整理できます。 たとえば、以前の AWS Glue 投稿で説明したように、感情分析を導入することもできます。
単純化するため、 ApplyMapping 変換を使用してデータセットからいくつかの列を抽出することもできます:
ApplyMapping は投影や型変換を実行する柔軟な変換方法です。この例では、 actor.login などいくつかのフィールドのネストを解除し、トップレベルの actor フィールドにマッピングします。また、 id 列を長い整数のパーティション列に変換します。
パーティショニングされたデータの書き出し
最後のステップは、変換したデータセットを Amazon S3 に書き出し、Amazon Athena などの他のシステムで処理可能にすることです。デフォルトでは、DynamicFrame 書き出し時にはパーティショニングされていません。出力ファイルはすべて、指定の出力パス下のトップレベルに書き出されます。最近まで、DynamicFrame をパーティションに書き出すには、書き出し前に Spark SQL DataFrame に変換するしかありませんでした。DynamicFrames は、キーの順番によるパーティショニングをネイティブでサポートするようになりました。
これは、シンク作成時に追加の partitionKeys オプションのパスを渡すことで実行できます。たとえば以下のコードでは、先程の Parquet 形式で S3 の type フィールドでパーティショニングされたディレクトリに作成したデータセットを書き出します。
ここでは、 $outpath が S3 内の出力用基本プレースホルダーになります。また、 partitionKeys パラメータも Python の connection_options ディクショナリで指定できます:
この書き込みを実行すると、個々のレコードから type フィールドが削除され、ディレクトリ構造にエンコードされます。これを実際に確認する場合、AWS CLI から aws s3 ls コマンドを使用して出力パスをリストできます:
予想通り、個別のイベントタイプごとにパーティションが作成されました。 この例ではひとつの値でパーティションを作成しましたが、もちろん必須ではありません。たとえば、元の年、月、日のパーティションを残したい場合は、 partitionKeys オプションを Seq(“year”, “month”, “day”) と設定するだけで可能です。
結論
この投稿では、AWS Glue のパーティショニングされたデータの取り扱い方を説明しました。パーティショニングは、大型のデータセットを最大限に利用するためには必須のテクニックです。AWS ビッグデータのエコシステムには、Amazon Athena や Amazon Redshift Spectrum など、パーティションを活用してクエリ処理を高速化する多数のツールがあります。AWS Glue はクロール、フィルタリング、パーティショニングされたデータの書き出しのメカニズムを提供します。これで Amazon S3 のデータをお好みの形に構成し、ビッグデータアプリケーションを最大限活用することができます。
ぜひお試しください。
その他の参考資料
この投稿がお役に立ちましたら、AWS Glue が Scala スクリプトをサポートおよび AWS Glue の Relationalize 変換でネストされた JSON のクエリを簡略化の投稿もご覧ください。
 Ben Sowell は AWS Glue のシニアソフトウェア開発エンジニアです。彼は ETL システムに 5 年以上取り組み、ユーザーのデータから潜在的な力を引き出すお手伝いをしています。余暇には読書と、ベイエリアの散策を楽しんでいます。
Ben Sowell は AWS Glue のシニアソフトウェア開発エンジニアです。彼は ETL システムに 5 年以上取り組み、ユーザーのデータから潜在的な力を引き出すお手伝いをしています。余暇には読書と、ベイエリアの散策を楽しんでいます。
 Mohit Saxena は AWS Glue のシニアソフトウェア開発エンジニアです。彼はクラウドのデータの効率的な管理を目指して、スケーラブルな分散システム構築に熱心に取り組んでいます。映画鑑賞や最新テクノロジーについての本を読むことが好きです。
Mohit Saxena は AWS Glue のシニアソフトウェア開発エンジニアです。彼はクラウドのデータの効率的な管理を目指して、スケーラブルな分散システム構築に熱心に取り組んでいます。映画鑑賞や最新テクノロジーについての本を読むことが好きです。