AWS Türkçe Blog
Amazon Redshift Serverless – Artık Yeni Özelliklerle Genel Olarak Kullanılabilir
Orijinal makale: Link (Danilo Poccia)
Geçen yıl re:Invent‘te, Amazon Redshift‘in veri ambarı altyapısını yönetmek zorunda kalmadan her ölçekte veriyi analiz etmenizi sağlayan sunucusuz bir seçeneği olan Amazon Redshift Serverless‘ın önizlemesini sunduk. Sadece verilerinizi yüklemeniz ve sorgulamanız yeterlidir ve yalnızca kullandığınız kadar ödersiniz. Bu, özellikle analitik iş yüklerinin 7 gün 24 saat çalışmadığı ve veri ambarının her zaman etkin olmadığı kullanım durumları için daha fazla şirketin modern bir veri stratejisi oluşturmasına olanak tanır. Kurum içinde veri kullanımının yaygınlaştığı ve yeni departmanlardaki kullanıcıların veri ambarı altyapısına sahip olmak zorunda kalmadan analitik çalıştırmak istediği şirketler için de geçerlidir.
Bugün, Amazon Redshift Serverless’ın genel kullanıma sunulduğunu ve birçok yeni özellik eklediğimizi paylaşmaktan mutluluk duyuyorum. Ayrıca önizlemeye kıyasla Amazon Redshift Serverless işlem maliyetlerini de azaltıyoruz.
You can now create multiple serverless endpoints per AWS account and Region using namespaces and workgroups:
Artık namespace’lerini ve workgroup’larını kullanarak AWS hesabı ve Bölge başına birden çok sunucusuz uç nokta oluşturabilirsiniz:
- Bir namespace (ad alanı), veritabanı adı ve parolası, izinler ve şifreleme yapılandırması gibi bir veritabanı nesneleri ve kullanıcıları topluluğudur. Burası, verilerinizin yönetildiği ve ne kadar depolama alanı kullanıldığını görebileceğiniz yerdir.
- Bir workgroup (çalışma grubu), ağ ve güvenlik ayarları dahil olmak üzere bir bilgi işlem kaynakları topluluğudur. Her çalışma grubunun, uygulamalarınızı bağlayabileceğiniz sunucusuz bir uç noktası vardır. Bir çalışma grubu yapılandırırken, özel veya genel olarak erişilebilir uç noktalar ayarlayabilirsiniz.
Her ad alanı, kendisiyle ilişkilendirilmiş yalnızca bir çalışma grubuna sahip olabilir. Tersine, her çalışma grubu yalnızca bir ad alanıyla ilişkilendirilebilir. Örneğin, yalnızca aynı veya başka bir AWS hesabı ya da Bölgesindeki diğer ad alanlarıyla veri paylaşmak için kullanmak üzere ilişkilendirilmiş herhangi bir çalışma grubu olmadan bir ad alanınız olabilir.
Çalışma grubu yapılandırmanızda, maliyetlerinizi kontrol altında tutmanıza yardımcı olmak için artık sorgu izleme kurallarını kullanabilirsiniz. Ayrıca, Amazon Redshift Serverless’ın veri ambarı kapasitesini otomatik olarak ölçeklendirme yöntemi, zorlu ve öngörülemeyen iş yükleri için hızlı performans sağlamak için daha akıllıdır.
Bunun hızlı bir demo ile nasıl çalıştığını görelim. Ardından, ad alanları ve çalışma gruplarıyla neler yapabileceğinizi göstereceğim.
Amazon Redshift Serverless Kullanma
Amazon Redshift konsolunda, gezinti bölmesinde Redshift serverless‘ı seçiyorum. Başlamak için, en yaygın seçeneklere sahip bir ad alanı ve bir çalışma grubu yapılandırmak için Use default settings‘i seçiyorum. Örneğin, varsayılan VPC‘mi ve varsayılan security group‘u kullanarak bağlanabileceğim.

Varsayılan ayarlarla, yapılandırılacak tek seçenek Permissions‘dır. Burada Amazon Redshift’in S3, Amazon CloudWatch Logs, Amazon SageMaker ve AWS Glue gibi diğer servislerle nasıl etkileşime girebileceğini belirtebilirim. Verileri daha sonra yüklemek için Amazon Redshift’e bir S3 bucket’ına erişim izni veriyorum. Manage IAM roles‘u ve ardından Create IAM role‘u seçiyorum.
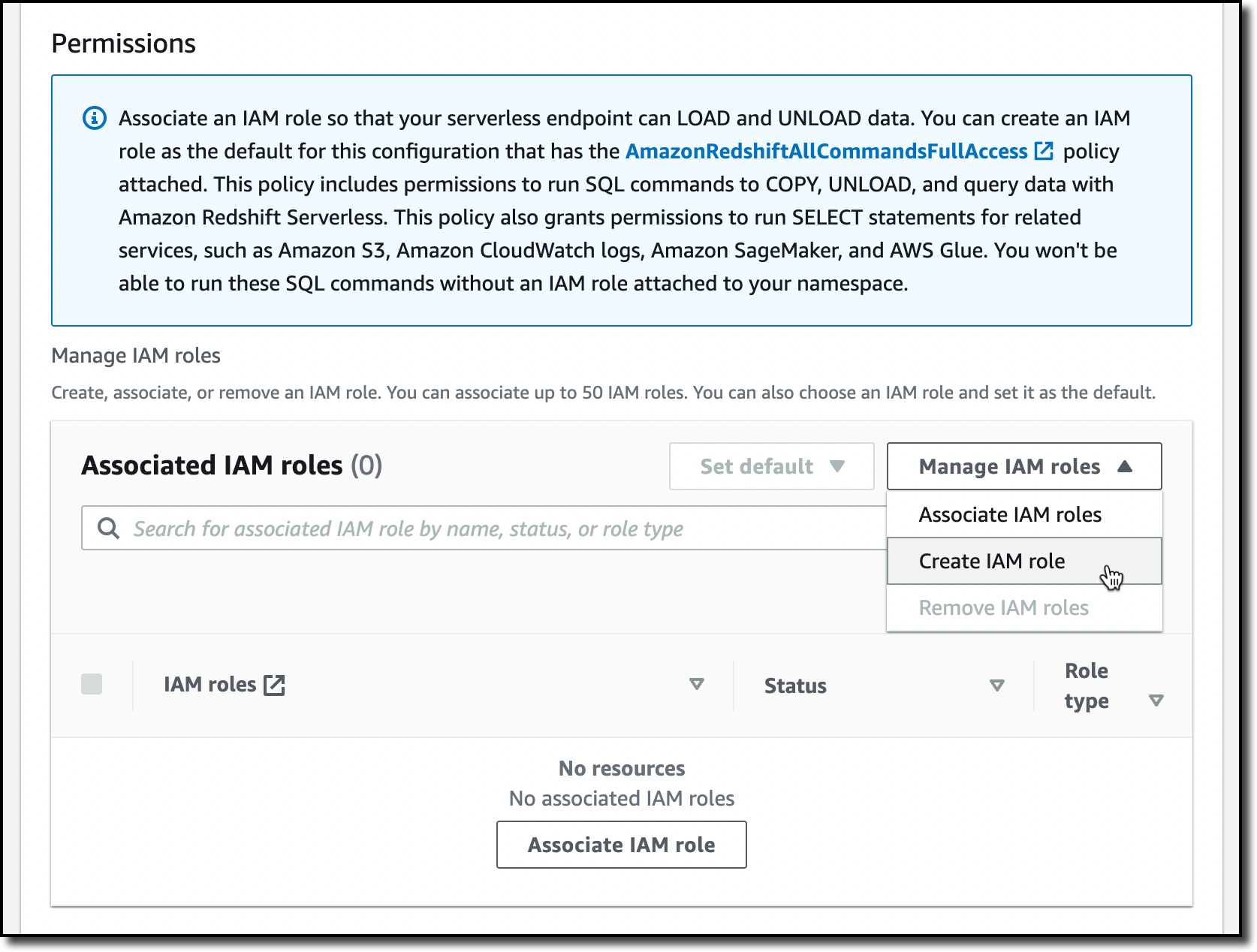
IAM rolünü oluştururken, belirli S3 klasörlerine (specific S3 buckets) erişim verme ve aynı AWS Bölgesinde bir S3 klasörü seçme seçeneğini işaretliyorum. Ardından, rolün oluşturulmasını tamamlamak ve bunu ad alanı için varsayılan rol olarak otomatik olarak kullanmak için Create IAM role as default‘u seçiyorum.

Save configuration‘ı seçiyorum ve birkaç dakika sonra veritabanı kullanıma hazır. Serverless dashboard panelinde, Redshift query editor v2‘yu açmak için Query data‘yı seçiyorum. Burada, örnek bir veritabanı yüklemek için Amazon Redshift Veritabanı Geliştirici kılavuzundaki talimatları izliyorum. Hızlı bir test yapmak istiyorsanız, birkaç örnek veritabanı (burada kullandığım dahil) sample_data_dev veritabanında zaten mevcuttur. Ayrıca, sorguları çalıştırmak için Amazon Redshift’e veri yüklemenin gerekli olmadığını unutmayın. Harici bir şema ve harici bir tablo oluşturarak sorgularımda bir S3 veri gölünden gelen verileri kullanabilirim.
Örnek veritabanı yedi tablodan oluşur ve kullanıcıların spor etkinlikleri, gösteriler ve konserler için bilet alıp sattığı kurgusal bir “TICKIT” web sitesi için satış etkinliğini izler.
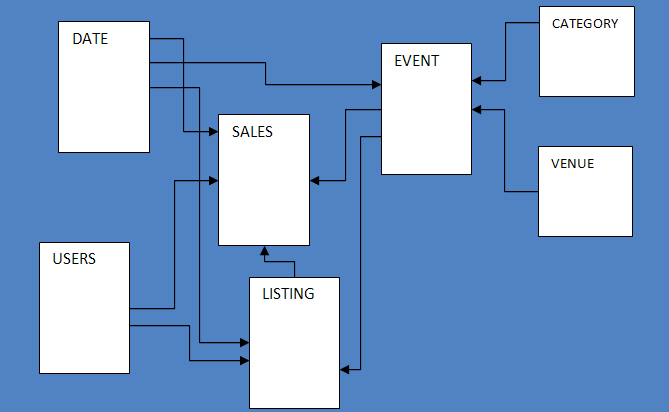
Veritabanı şemasını yapılandırmak için, users, venue, category, date, event, listing ve sales tablolarını oluşturmak için birkaç SQL komutu çalıştırıyorum.

Ardından veritabanı tabloları için örnek verileri içeren tickitdb.zip dosyasını indiriyorum. Dosyaları açıp, IAM rolünü yapılandırırken kullandığım S3 klasöründeki bir tickit klasörüne yüklüyorum.
Artık S3 klasöründeki verileri veritabanıma yüklemek için COPY komutunu kullanabilirim. Örneğin, users tablosuna veri yüklemek için:
sales tablosu verilerini içeren dosya, sekmeyle ayrılmış değerleri kullanır:
Tüm tablolara veri yükledikten sonra bazı sorguları çalıştırmaya başlıyorum. Örneğin, aşağıdaki sorgu, Kaliforniya merkezli etkinlikler için ilk beş satıcıyı bulmak için beş tabloyu birleştirir (örnek verilerin 2008 yılı için olduğunu unutmayın):

Artık veritabanım hazır olduğuna göre, Amazon Redshift Serverless ad alanlarını ve çalışma gruplarını yapılandırarak neler yapabileceğimi görelim.
Ad Alanlarını Kullanma ve Yapılandırma
Ad alanları, veritabanı verilerinin koleksiyonları ve güvenlik yapılandırmalarıdır. Amazon Redshift konsolunun gezinme bölmesinde Namespace configuration‘ı seçiyorum. Listede, az önce oluşturduğum default ad alanını seçiyorum.
Data backup sekmesinde, bir anlık görüntü (snapshot) oluşturabilir veya geri yükleyebilir veya her 30 dakikada bir otomatik olarak oluşturulan ve 24 saat boyunca saklanan kurtarma noktalarından birinden verileri geri yükleyebilirim. Bu, yanlışlıkla yazma veya silme durumunda verileri kurtarmak için yararlı olabilir.

Security and encryption sekmesinde, kaynaklarımı şifrelemek ve şifresini çözmek için kullanılan AWS Key Management Service (AWS KMS) anahtarı da dahil olmak üzere izinleri ve şifreleme ayarlarını güncelleyebilirim. Bu sekmede ayrıca denetim günlüğünü etkinleştirebilir ve kullanıcı, bağlantı ve kullanıcı etkinliği günlüklerini CloudWatch Logs’a aktarabilirim.

Datashares (veri paylaşımı) sekmesinde, aynı veya farklı Bölgelerdeki diğer ad alanları ve AWS hesapları ile veri paylaşmak için bir veri paylaşımı oluşturabilirim. Bu sekmede ayrıca diğer ad alanlarından veya AWS hesaplarından aldığım bir paylaşımdan veritabanı oluşturabilir ve AWS Data Exchange tarafından yönetilen veri paylaşımlarının aboneliklerini görebilirim.

Bir veri paylaşımı oluşturduğumda, hangi nesnelerin dahil edileceğini seçebilirim. Örneğin burada hassas veriler içermediği için sadece date ve event tablolarını paylaşmak istiyorum.

Çalışma Gruplarını Kullanma ve Yapılandırma
Çalışma grupları, bilgi işlem kaynaklarının ve bunların ağ ve güvenlik ayarlarının koleksiyonlarıdır. Konfigüre edildikleri ad alanı için sunucusuz uç nokta sağlarlar. Amazon Redshift konsolunun gezinme bölmesinde Workgroup configuration seçiyorum. Listede, az önce oluşturduğum default ad alanını seçiyorum.
Data access sekmesinde, ağ ve güvenlik ayarlarını güncelleyebilir (örneğin, VPC’yi, subnet’leri veya security group’u değiştirebilir) veya uç noktayı herkesin erişimine açık hale getirebilirim. Bu sekmede, sunucusuz veritabanım ile kullandığım veri havuzları (örneğin, verileri yüklemek veya boşaltmak için kullanılan S3 paketleri) arasındaki ağ trafiğini internet yerine bir VPC aracılığıyla yönlendirmek için Enhanced VPC routing‘i de etkinleştirebilirim. Başka bir VPC veya subnet’teki sunucusuz uç noktalara erişmek için Amazon Redshift tarafından yönetilen bir VPC endpoint oluşturabilirim.

Limits sekmesinde, sorgularımı işlemek için kullanılan temel kapasiteyi (Redshift işlem birimleri (Redshift processing units) veya RPU’lar olarak ifade edilir) yapılandırabilirim. Amazon Redshift Serverless, daha fazla sayıda kullanıcıyla başa çıkmak için kapasiteyi ölçeklendirir. Burada ayrıca sorgularımı hızlandırmak için temel kapasiteyi artırma veya maliyetleri azaltmak için azaltma seçeneğine de sahibim.
Bu sekmede, maliyetlerimin öngörülebilir olmasını sağlamak için günlük, haftalık ve aylık eşikleri yapılandırmak için Usage limits de ayarlayabilirim. Örneğin, işlem kaynaklarım için günlük 200 RPU-hours bir sınır ve aylık 2.000 RPU-hours bir sınır yapılandırdım. Bölgeler arası veri paylaşımları için veri aktarım maliyetlerini kontrol etmek için günlük 3 TB ve haftalık 10 TB sınır yapılandırdım. Son olarak, her sorgu tarafından kullanılan kaynakları sınırlamak için, 60 saniyeden fazla çalışan sorguların zaman aşımına uğraması için Query limits kullanıyorum.

Kullanılabilirlik ve Fiyatlandırma
Amazon Redshift Serverless bugün genel olarak US East (Ohio), US East (N. Virginia), US West (Oregon), Europe (Frankfurt), Europe (Ireland), Europe (London), Europe (Stockholm), and Asia Pacific (Seoul), Asia Pacific (Singapore), Asia Pacific (Sydney) ve Asia Pacific (Tokyo) AWS Bölgelerinde kullanılabilir durumdadır.
Favori istemci araçlarınızdan JDBC/ODBC aracılığıyla veya Amazon Redshift konsolunda bulunan web tabanlı bir SQL istemci uygulaması olan Amazon Redshift query editor v2 kullanarak bir çalışma grubu uç noktasına bağlanabilirsiniz. Web hizmetleri tabanlı uygulamaları (AWS Lambda işlevleri veya Amazon SageMaker notebook’ları gibi) kullanırken, yerleşik Amazon Redshift Data API‘yi kullanarak veritabanınıza erişebilir ve sorgular gerçekleştirebilirsiniz.
Amazon Redshift Serverless ile yalnızca etkin durumdayken veritabanınızın tükettiği işlem kapasitesi kadar ödeme yaparsınız. İşlem kapasitesi, iş yükünüze bağlı olarak otomatik olarak yukarı veya aşağı ölçeklenir ve zaman ve maliyetten tasarruf etmek için işlem yapılmayan dönemlerde kapanır. Verileriniz yönetilen depolama alanında depolanır ve aylık GB ücreti ödersiniz.
Size daha iyi bir fiyat performansı ve Amazon Redshift Serverless’ı daha da geniş bir kullanım senaryosu seti için kullanma esnekliği sağlamak amacıyla, US East (N. Virginia) Bölgesi için fiyatı RPU-hours başına 0,5 ABD Dolarından 0,375 ABD Dolarına düşürüyoruz. Benzer şekilde, diğer Bölgelerdeki fiyatı, önizleme fiyatından ortalama yüzde 25 oranında düşürüyoruz. Daha fazla bilgi için Amazon Redshift fiyatlandırma sayfasına bakın.
Kendi kullanım örneklerinizle pratik yapmanıza yardımcı olmak için, Amazon Redshift Serverless’ı denemeniz için 90 gün boyunca 300 ABD doları tutarında AWS kredisi de sağlıyoruz. Bu krediler, yalnızca Amazon Redshift Serverless’ın bilgi işlem, depolama ve anlık görüntü kullanımı maliyetlerinizi karşılamak için kullanılır.
Get insights from your data in seconds with Amazon Redshift Serverless.
Amazon Redshift Serverless ile verilerinizden saniyeler içinde içgörüler elde edin.
— Danilo