亚马逊AWS官方博客
Amazon Managed Streaming for Apache Kafka (MSK) – 现已全面推出
我们的客户使用流数据的方式总是出人意料,令人赞叹。例如,全球最受企业和专业人士信赖的新闻机构之一 Thomson Reuters,构建了一个用于捕获、分析和可视化分析数据的解决方案,帮助产品团队不断改善用户体验。提供《卡通农场》、《部落冲突》和《海岛奇兵》等游戏的社交游戏公司 Supercell 正在实时提供游戏内数据,每天处理 450 亿个事件。
自从我们在 re:Invent 2013 上推出 Amazon Kinesis 以来,我们不断扩展客户在 AWS 上使用流数据的方式。部分可用工具包括:
- Kinesis Data Streams,用于使用您自己的应用程序捕获、存储和处理数据流。
- Kinesis Data Firehose,用于将数据转换并收集到 Amazon S3、Amazon Elasticsearch Service 和 Amazon Redshift 等目的地。
- Kinesis Data Analytics,用于使用 SQL 或 Java(通过 Apache Flink 应用程序)持续分析数据,以便满足检测异常或进行时间序列聚合等需求。
- Kinesis Video Streams,用于简化媒体流的处理。
在 re:Invent 2018 上,我们介绍了开放预览版的 Amazon Managed Streaming for Apache Kafka (MSK),这是一项完全托管的服务,可用于轻松构建和运行使用 Apache Kafka 处理流数据的应用程序。
我很高兴地宣布 Amazon MSK 于今天正式发布!
工作原理
Apache Kafka (Kafka) 是一个开源平台,它使客户能够捕获点击流事件、交易、IoT 事件、应用程序和机器日志等流数据,并拥有执行实时分析、运行连续转换和将这些数据实时分发到数据湖和数据库的应用程序。 您可将 Kafka 用作流数据存储,以将生成流数据(创建者)的应用程序与使用流数据(使用者)的应用程序分离。
虽然 Kafka 是一种流行的企业数据流和消息传递框架,但在生产环境中可能很难进行设置、扩展和管理。 Amazon MSK 负责处理这些管理任务,并可在遵循高可用性和安全性最佳实践的环境中轻松设置、配置和运行 Kafka 以及 Apache ZooKeeper。
您的 MSK 集群始终在由 MSK 服务管理的 Amazon VPC 中运行。您的 MSK 资源可通过弹性网络接口 (ENI) 提供给您自己的 VPC、子网和安全组,弹性网络接口 (ENI) 将显示在您的账户中,如以下架构图所述:
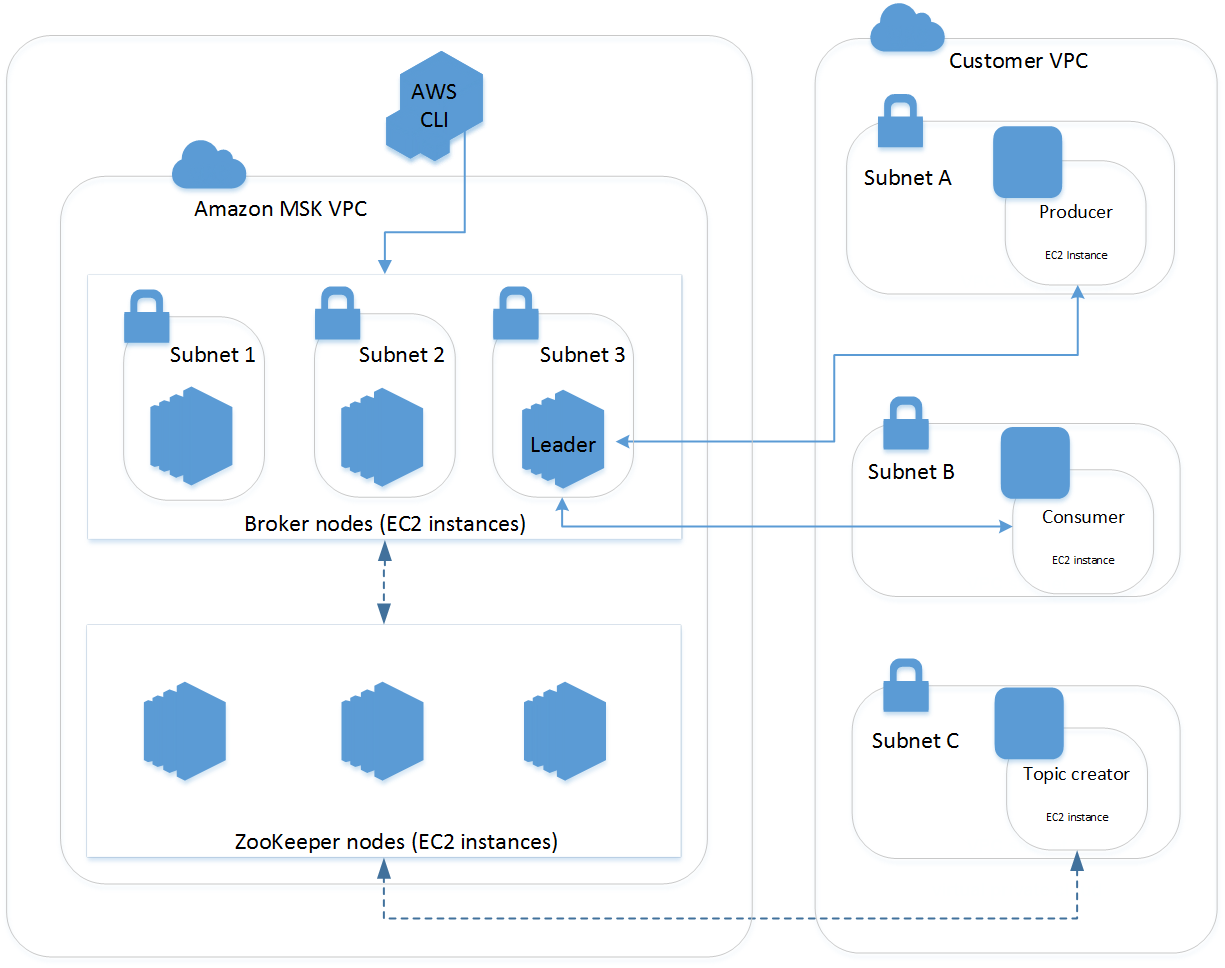
客户可以在几分钟内创建集群、使用 AWS Identity and Access Management (IAM) 控制集群操作、使用由 AWS Certificate Manager (ACM) 完全托管的 TLS 私有证书颁发机构授权客户端、使用 TLS 加密传输中数据,以及使用 AWS Key Management Service (KMS) 加密密钥加密静态数据。
Amazon MSK 会持续监控服务器运行状况,在服务器发生故障时自动替换服务器,自动执行服务器修补,并将高可用性 ZooKeeper 节点作为服务的一部分运行,而无需额外费用。Kafka 关键性能指标在控制台和 Amazon CloudWatch 中发布。Amazon MSK 与 Kafka 1.1.1 和 2.1.0 版完全兼容,因此您可以继续运行应用程序,使用 Kafka 的管理工具,并使用 Kafka 兼容的工具和框架,而无需更改代码。
根据我们在开放预览期间的客户反馈,Amazon MSK 添加了如下功能:
- 通过客户端和代理之间以及代理之间的 TLS 进行传输加密
- 使用 ACM 私有证书颁发机构进行相互 TLS 身份验证
- 支持 Kafka 2.1.0 版
- SLA 可用性达到 99.9%
- 符合 HIPAA 要求
- 集群范围的存储实现扩展
- 与 AWS CloudTrail 集成以进行 MSK API 日志记录
- 集群标记和基于标记的 IAM 策略应用程序
- 为主题和代理定义自定义的集群范围配置
AWS CloudFormation 支持将在未来几周提供。
创建集群
让我们使用 AWS 管理控制台创建一个集群。我给集群命名,选择我想从中使用集群的 VPC 以及 Kafka 版本。

然后,我选择可用区 (AZ) 和要在 VPC 中使用的相应子网。在下一步中,我选择在每个可用区中部署的 Kafka 代理数量。更多的代理允许您通过将分区分配给不同的代理来扩展集群的吞吐量。

我可以添加标记来搜索和筛选我的资源、将 IAM 策略应用到 Amazon MSK API,并跟踪成本。对于存储,我保留每个代理的默认存储卷大小。
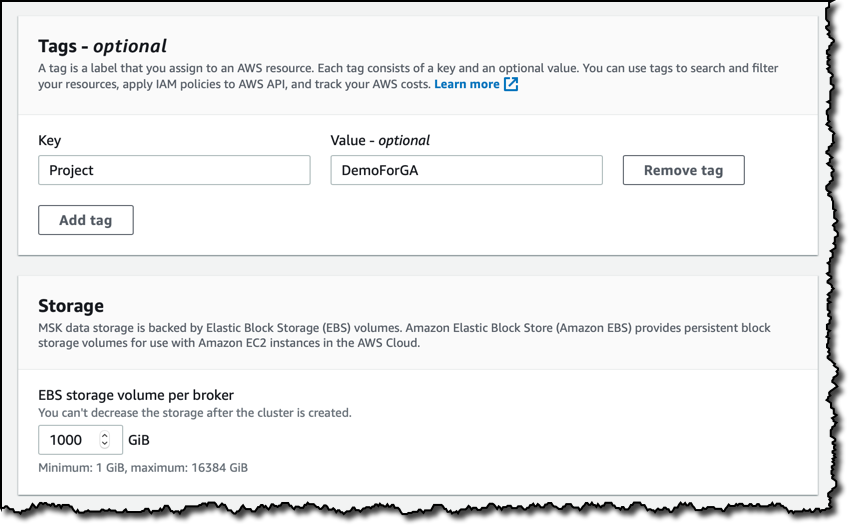
我选择在集群中使用加密,并允许在客户端和代理之间传输 TLS 和纯文本流量。对于静态数据,我使用 AWS 托管的客户主密钥 (CMK),但您可以使用 KMS 在您的账户中选择 CMK 以进行进一步控制。您可以使用私有 TLS 证书来验证连接到您的集群的客户端身份。此功能要使用 ACM 的私有证书颁发机构 (CA)。现在,我未选中此选项。

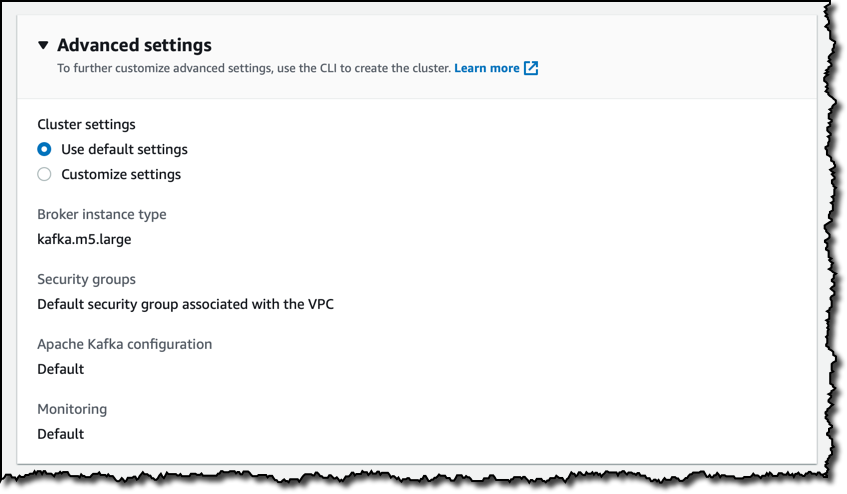
在高级设置中,我保留默认值。例如,我可以在这里为我的代理选择不同的实例类型。其中一些设置可以使用 AWS CLI 进行更新。
我创建集群并通过集群摘要监控状态,包括我在通过 CLI 或 SDK 进行交互时可以使用的 Amazon 资源名称 (ARN)。
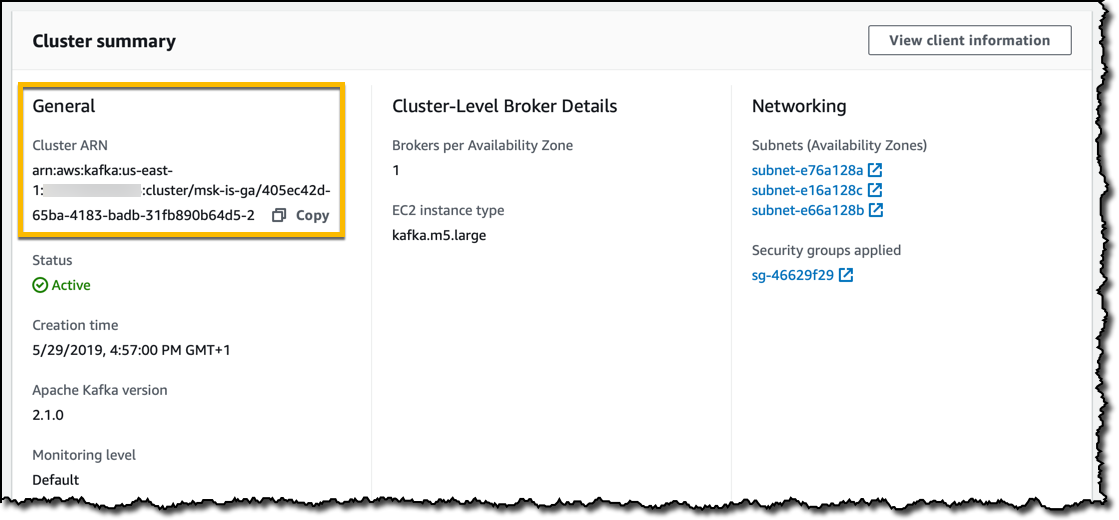
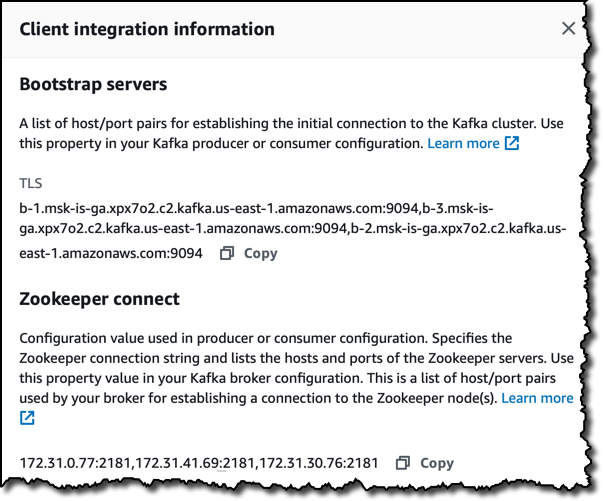
当状态为活动状态时,客户端信息部分会提供连接到集群的特定详细信息,例如:
- 我可以使用 Kafka 工具连接到集群的引导服务器。
- 主机和端口的 Zookeeper 连接列表。
我可以使用 AWS CLI 获取类似信息:
aws kafka list-clusters用于查看特定区域中集群的 ARNaws kafka get-bootstrap-brokers --cluster-arn <ClusterArn>用于获取 Kafka 引导服务器aws kafka describe-cluster --cluster-arn <ClusterArn>用于查看有关集群的更多详细信息,包括 Zookeeper 连接字符串
快速演示如何使用 Kafka
为了开始使用 Kafka,我在同一个 VPC 中创建了两个 EC2 实例,一个是创建者,一个是使用者。为了将它们设置为客户端计算机,我从 Apache 网站或任何镜像下载并提取 Kafka 工具。 Kafka 需要 Java 8 才能运行,所以我安装了 Amazon Corretto 8。
在创建者实例上的 Kafka 目录中,我创建了一个主题,用于将数据从创建者发送到使用者:
bin/kafka-topics.sh --create --zookeeper <ZookeeperConnectString> \
--replication-factor 3 --partitions 1 --topic MyTopic
然后我启动了一个基于控制台的创建者:
bin/kafka-console-producer.sh --broker-list <BootstrapBrokerString> \
--topic MyTopic
在使用者实例的 Kafka 目录中,我启动了一个基于控制台的使用者:
bin/kafka-console-consumer.sh --bootstrap-server <BootstrapBrokerString> \
--topic MyTopic --from-beginning
下面是快速演示的录制内容,我在其中创建主题,然后从创建者(顶级终端)向该主题的使用者(底部终端)发送消息:

定价和可用性
定价根据 Kafka 代理小时和配置的存储小时计算。集群使用的 Zookeeper 节点无需支付任何费用。 AWS 数据传输率适用于进出 MSK 的数据传输。您不需要为区域中集群内的数据传输付费,包括代理之间的数据传输以及代理和 ZooKeeper 节点之间的数据传输。
您可以使用 MirrorMaker(随开源 Kafka 一起提供)等工具将现有 Kafka 集群迁移到 MSK,从而将数据从您的集群复制到 MSK 集群。
上游兼容性是 Amazon MSK 的核心原则。我们对 Kafka 平台的代码更改将发布回开源。
Amazon MSK 已在以下区域推出:美国东部(弗吉尼亚北部)、美国东部(俄亥俄)、美国西部(俄勒冈)、亚太地区(东京)、亚太地区(新加坡)、亚太地区(悉尼)、欧洲(法兰克福)、欧洲(爱尔兰)、欧洲(巴黎)和欧洲(伦敦)。
您会如何使用 Amazon MSK 来简化流应用程序的构建并将其迁移到云呢?我拭目以待!