亚马逊AWS官方博客
新增功能 – Amazon Kinesis Data Analytics for Java
客户使用 Amazon Kinesis 来收集、处理和分析实时流数据。通过这种方式,他们可以快速处理来自业务、基础设施或客户的信息。 例如,Epic Games 可以针对其热门在线游戏“堡垒之夜”提取的游戏事件每秒超过 150 万。
通过 Amazon Kinesis Data Analytics,您能够使用标准 SQL 实时处理数据。虽然 SQL 能够让用户无需学习新的框架或语言就能轻松快速地查询大量流数据,但许多客户还是希望能够使用通用编程语言构建更复杂的数据处理应用程序。
通过 Amazon Kinesis Data Analytics 使用 Java
今天,我们在 Amazon Kinesis Data Analytics 中添加了 Java 支持。 现在,开发人员可以使用他们自己的 Java 代码来创建强大的实时应用程序来处理流数据,例如持续转换数据并加载到其数据湖中、生成指标以产生实时游戏排行榜、应用机器学习模型来处理来自联网设备的数据流等。
要使用这一新功能,开发人员需要使用开源库构建应用程序。这些开源库中包含用于通用数据处理功能的内置运算符,让应用程序能够整理、转换、聚合和分析任意规模的数据。以下库都已开放源代码,您可以在任何位置运行它们:
- Apache Flink:用于处理数据流的开源框架和引擎。
- 适用于 Java 的 AWS 开发工具包:提供适用于许多 AWS 服务的 Java API。
开发人员可以在他们选择的集成开发环境 (IDE) 中使用这些 Java 库。通过这些库,只需使用一行代码就能集成下列 AWS 服务:
- 流数据源:Amazon Kinesis Data Streams
- 流目的地:Amazon S3、Amazon DynamoDB、Amazon Kinesis Data Streams、Amazon Kinesis Data Firehose
除了预建的 AWS 集成外,Java 库还包括更多连接到 Cassandra、ElasticSearch、RabbitMQ、Redis 等工具的连接器,并能够构建自定义集成。
构建 Kinesis Data Streams Java 应用程序
我准备了一个简单的 Java 应用程序示例,用来实现在数据处理时“强制”对单词进行计数。我发送输入的一些文本段落,然后我每 5 秒钟就会得到每个单词被输出的次数。
首先,我创建两个 Kinesis Data Streams:
- TextInputStream:我将向其发送输入记录
- WordCountOutputStream:我将在此读取 Java 应用程序的输出

下面是 word-count Java 应用程序的代码。在 Kinesis Data Streams 中执行读取和写入操作时,我使用的是 Apache Flink 项目中的 Kinesis 连接器。
public class StreamingJob {
private static final String region = "us-east-1";
private static final String inputStreamName = "TextInputStream";
private static final String outputStreamName = "WordCountOutputStream";
private static DataStream<String> createSourceFromStaticConfig(
StreamExecutionEnvironment env) {
Properties inputProperties = new Properties();
inputProperties.setProperty(ConsumerConfigConstants.AWS_REGION, region);
inputProperties.setProperty(ConsumerConfigConstants.STREAM_INITIAL_POSITION,
"LATEST");
return env.addSource(new FlinkKinesisConsumer<>(inputStreamName,
new SimpleStringSchema(), inputProperties));
}
private static FlinkKinesisProducer<String> createSinkFromStaticConfig() {
Properties outputProperties = new Properties();
outputProperties.setProperty(ConsumerConfigConstants.AWS_REGION, region);
FlinkKinesisProducer<String> sink = new FlinkKinesisProducer<>(new
SimpleStringSchema(), outputProperties);
sink.setDefaultStream(outputStreamName);
sink.setDefaultPartition("0");
return sink;
}
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> input = createSourceFromStaticConfig(env);
input.flatMap(new Tokenizer())
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1)
.map(new MapFunction<Tuple2<String, Integer>, String>() {
@Override
public String map(Tuple2<String, Integer> value) throws Exception {
return value.f0 + "," + value.f1.toString();
}
})
.addSink(createSinkFromStaticConfig());
env.execute("Word Count");
}
public static final class Tokenizer
implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
String[] tokens = value.toLowerCase().split("\\W+");
for (String token : tokens) {
if (token.length() > 0) {
out.collect(new Tuple2<>(token, 1));
}
}
}
}
}该应用程序最重要的部分是输入对象的操作,我在其中应用了几个 DataStream Transformations:
- 首先使用了一个数据框,其中包含输入流的字符串。
- 在 FlatMap 中使用 Tokenizer 将句子拆分成“单词”,每个单词后面跟着数字“1”。
- 应用 KeyBy 运算符对涉及“单词”的流进行逻辑分区。
- 使用 5 秒钟的翻转窗口。
- 在窗口中进行聚合,为每个单词加上数字“1”来对它们进行计数。
- 为每个记录使用简单的 Map,将单词和数字连接成一个逗号分隔值 (CSV) 字符串,发送到输出流。
这里出现的一个最强大的运算符之一就是 KeyBy。它让您能够按特定密钥实时重新整理特定流。这种类型的密钥更新可实现进一步的下游运算,例如聚合、计数等。这让您可以在同一应用程序中的不同密钥设置 streaming map-reduce。
我使用 Maven 构建 Java 应用程序,并将输出 JAR 加载到我想部署应用程序的区域中的 Amazon Simple Storage Service (S3) 存储桶。在 Kinesis Data Analytics 控制台中,我创建一个新的应用程序并选择“Flink”作为运行时:
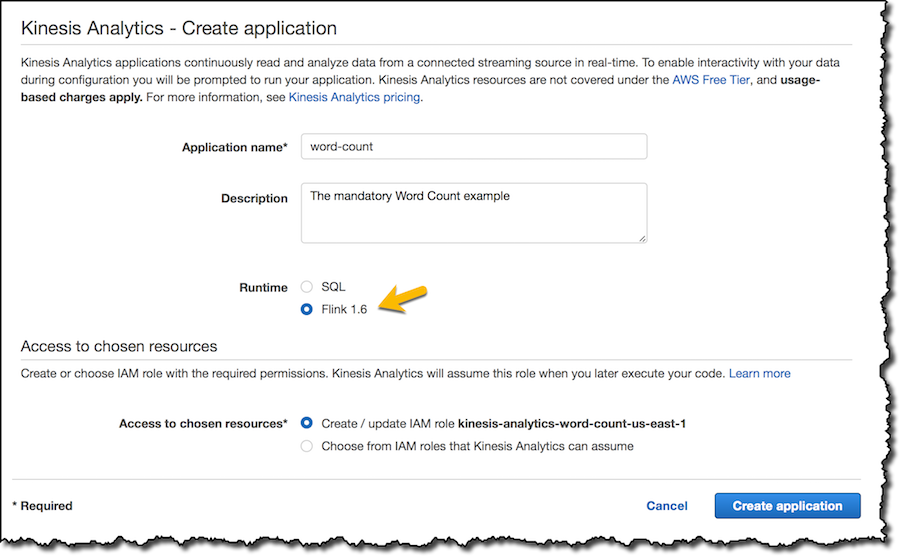
然后我配置应用程序,以便在我的 S3 存储桶中使用代码。控制台会更新应用程序的 IAM 角色,以便获得读取代码的权限。

您也可以选择在应用程序的配置中添加键/值属性。您可以在应用程序中读取这些属性,从而在部署时提供自定义设置。
监控部分我保留了默认指标。我启用了 Amazon CloudWatch 日志记录,仅用于记录错误级别的日志。

不要忘记为控制台创建的 IAM 角色添加权限,以便 Kinesis Analytics 应用程序能够从用于输入和输出的流(本文示例中为 TextInputStream 和 WordCountOutputStream)中读取和写入数据。
现在我可以使用“运行”按钮启动应用程序,然后当其运行时,我会使用准备好的脚本在输入流中输入一些文本(我使用的是 Amazon Kinesis 平台的描述):
$ python put_records.py TextInputStream Amazon Kinesis makes it easy to collect, process, and analyze real-time, streaming data...
我的应用程序的行为汇总在“Application Graph”(应用程序图形)的控制台中,该图形以可视化形式展示了数据流由运算符和中间结果组成(使用多个流的复杂应用程序其图形会更有趣):

我使用以 Python 语言编写的 Lambda 函数来读取输出流。我使用的是 AWS Lambda 的 Kinesis 记录聚合与取消聚合模块提供的函数,它能够自动“取消聚合”由 Amazon Kinesis 创建器库 (KPL) 聚合的记录。
正如预期,在 CloudWatch Logs 控制台中,我得到了单词列表及它们被使用的次数,由 Lambda 函数每 5 秒更新一次:

定价和可用性
使用 Amazon Kinesis Data Analytics for Java,您只需按实际用量付费。 定价类似 Amazon Kinesis Data Analytics for SQL,但稍有不同。
对于 Java 应用程序,您需要为每个应用程序额外支付一个 Amazon Kinesis 处理单元 (KPU) 的费用,用于应用程序编排。Java 应用程序还需支付运行应用程序存储和持久应用程序备份所需的费用。运行应用程序存储用于 Amazon Kinesis Data Analytics 有状态处理功能,并且每月按 GB 收费。持久的应用程序备份为可选项,为应用程序提供时间点恢复功能,每月按 GB 收费。
例如,在美国东部(弗吉尼亚北部),每 KPU 小时的定价为 0.11 USD,您需要支付运行应用程序存储费用(每月每 GB 0.10 USD)和持久应用程序备份费用(每月每 GB 0.023 USD)。
现已推出
Amazon Kinesis Data Analytics for Java 现已在美国东部(弗吉尼亚北部)、美国东部(俄亥俄)、美国西部(俄勒冈)、欧洲西部(爱尔兰)推出。
在本文中,我仅仅触及了在 Amazon Kinesis Data Analytics 中添加 Java 支持后实现的流处理功能的皮毛。我认为这款强大的工具有助于实现新的使用案例。快来告诉我您打算用它来构建什么样的应用程序吧!