亚马逊AWS官方博客
新增功能 – AWS IoT Greengrass 在边缘增加了容器支持和数据流管理功能
AWS IoT Greengrass 将云功能扩展到边缘设备,即使连接时断时续,也可以几乎实时地响应本地事件。
今天,我们添加了两项功能,可帮助轻松构建物联网解决方案:
- 对使用 Greengrass Docker 应用程序部署连接器 来部署应用程序的容器支持。
- 从边缘设备收集、处理和导出数据流,并使用适用于 AWS IoT Greengrass的 Stream Manager 管理数据的生命周期。
让我们看看这些新功能如何运作及其使用方法。
将基于容器的应用程序部署到 Greengrass 核心设备
现在,您可以在 AWS IoT Greengrass 核心设备中运行AWS Lambda 函数和基于容器的应用程序。这样,使用容器镜像可以更轻松地从本地迁移应用程序,或构建包含库、其他二进制文件和配置文件等依赖项的新应用程序。这为您的应用程序提供了一致的部署环境,从而实现了跨开发环境和边缘站点的移动性。您可以通过将代码或可执行文件打包到容器镜像中来轻松部署旧版和第三方应用程序。
要使用此功能,我将使用 Docker Compose 文件描述基于容器的应用程序。我可以引用公共或私有存储库中的容器镜像,例如 Amazon Elastic Container Registry (ECR) 或 Docker Hub。 首先,我使用 Python 和 Flask 创建一个简单的 Web 应用程序,计算其可视化次数。
from flask import Flask
app = Flask(__name__)
counter = 0
@app.route('/')
def hello():
global counter
counter += 1
return 'Hello World! I have been seen {} times.\n'.format(counter)
我的 requirements.txt 文件包含单个依赖项 flask。
我使用此 Dockerfile 构建容器镜像并将其推送到 ECR。
FROM python:3.7-alpine
WORKDIR /code
ENV FLASK_APP app.py
ENV FLASK_RUN_HOST 0.0.0.0
COPY requirements.txt requirements.txt
RUN pip install -r requirements.txt
COPY . .
CMD ["flask", "run"]
这是引用我的 ECR 存储库中的容器镜像的 docker-compose.yml 文件。 Docker Compose 文件可以使用多个容器描述应用程序,但是在此示例中,我仅使用一个容器。
version: '3'
services:
web:
image: "123412341234.dkr.ecr.us-east-1.amazonaws.com/hello-world-counter:latest"
ports:
- "80:5000"
我将 docker-compose.yml 文件上传到 Amazon Simple Storage Service (S3) 存储桶。
现在,我使用 Amazon Elastic Compute Cloud (EC2) 实例作为核心设备创建一个 AWS IoT Greengrass 组。通常,您的核心设备在 AWS 云外部,但是对于边缘部署而言,使用 EC2 实例是设置和自动化开发与测试环境的好方法。
组准备就绪后,运行“空”部署,检查一切是否按预期进行。几秒钟后,第一个部署完成,开始添加连接器。

在 AWS IoT Greengrass 组的连接器部分中,选择添加连接器并搜索“Docker”。选择 Docker Application 部署,然后单击下一步。

现在,配置连接器的参数。在 S3 上选择了 docker-compose.yml 文件。AWS IoT Greengrass 组使用的AWS Identity and Access Management (IAM) 角色需要权限,然后才能从 S3 获取文件,获取授权令牌和从 ECR 下载镜像。如果您使用诸如 Docker Hub 之类的私有存储库,则可以利用与 AWS Secret Manager 的集成来简化连接器和 Lambda 函数使用本地密钥与服务和应用程序进行交互的过程。

部署更改,与我之前执行的操作类似。这次,在 AWS IoT Greengrass 核心设备上安装并启动了基于容器的新应用程序。

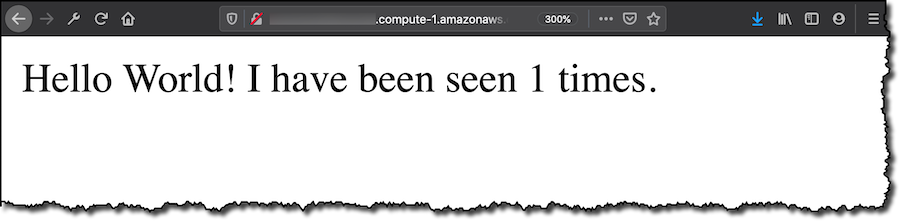
为了测试部署的 Web 应用程序,开启用作核心设备的 EC2 实例的安全组上 HTTP 端口的访问权限。连接浏览器时,会看到 Flask 应用程序开始统计访问次数。 基于容器的应用程序正在 AWS IoT Greengrass 核心设备上运行!
您可以部署比本示例中复杂得多的应用程序。让我们看看今天发布的其他功能。
将 Stream Manager 用于 AWS IoT Greengrass
对于视频处理、图像识别或从边缘传感器收集大量数据等常见用例,您通常需要构建自己的数据流管理功能。新的 Stream Manager 通过向 Greengrass Core 开发工具包添加标准化机制来简化此过程,可用于处理来自 IoT 设备的数据流,基于缓存大小或数据寿命管理本地数据保留策略,以及自动将数据直接传输到 AWS 云服务,例如 Amazon Kinesis 和 AWS IoT Analytics。
Stream Manager 还通过在每个流的基础上添加可配置的优先级、缓存策略、带宽利用率和超时来处理连接断开或时断时续的情况。在无法预测连接性或带宽受限的情况下,此新功能使您可以定义连接断开、重新连接或连接时应用程序的数据管理行为,从而确定重要数据到云的路径的优先级,并有效利用连接(如可用)。使用此功能,您可以专注于特定的应用程序用例,而不是构建数据保留和连接管理功能。
现在让我们看一下 Stream Manager 如何与实际用例一起工作。例如,我的 AWS IoT Greengrass 核心设备正在从多个设备接收大量数据。我想对正在收集的数据做两件事:
- 将所有低优先级的行数据上传到 AWS IoT Analytics,在那里我使用 Amazon QuickSight 可视化和理解我的数据。
- 根据设备的时间和位置在本地聚合数据,并将聚合的高优先级数据发送到 Kinesis 数据流,该数据流由业务应用程序处理以进行预测性维护。
使用 Greengrass Core 开发工具包中的 Stream Manager,我创建了两个本地数据流:
- 第一个本地数据流具有到 IoT Analytics 的低优先级导出,并且最多可以使用 256MB 本地磁盘(是的,这是受限设备)。如果您更喜欢速度而不是弹性,则可以使用内存来存储本地数据流。如果本地空间填充满,例如由于我失去了云连接但继续在本地缓存,我可以选择拒绝新数据或覆盖最早的数据。
- 第二个本地数据流是高优先级的导出到 Kinesis 数据流,并且可以使用多达 128MB 的本地磁盘(它是聚合数据,在相同的时间内需要的空间更少)。

以下是这种架构中数据的流动方式:
- 传感器数据由正在写入第一个本地数据流的 Producer Lambda 函数收集。
- 第二个 聚合器 Lambda 函数正在从第一本地数据流读取,执行聚合并将其输出写入第二个本地数据流。
- 一个基于 Reader 容器的应用程序(使用 Docker 应用程序部署连接器部署)正在为显示面板实时呈现聚合数据。
- Stream Manager 根据本地数据流的配置和策略来处理对云的提取,以便开发人员可以将精力集中在设备的逻辑上。
在以前的架构中使用 Lambda 函数或基于容器的应用程序只是一个示例。您可以根据自己的开发最佳实践来混合和匹配,或进行标准化。
现已推出
Docker 应用程序部署连接器和 Stream Manager 随 Greengrass 版本 1.10 一起提供。Stream Manager 在适用于 Java 和 Python 的 Greengrass Core 开发工具包中可用。我们会根据客户反馈增加对其他平台的支持。
这些新功能彼此独立,但可以像我的示例一样结合使用。它们可以简化您在边缘设备上构建和部署应用程序的方式,更轻松地在本地数据处理,并与后端的流和分析服务集成。快告诉我您打算将这些功能用在哪些方面吧!
– Danilo