Blog AWS Indonesia
Bagaimana Canva menghemat biaya pada Amazon S3 lebih dari $3 juta dollar setiap tahun
Canva adalah layanan desain online yang memberikan pengguna tool untuk mendesain, mengedit, dan mempublikasikan apa pun yang dapat mereka impikan. Canva menjalankan sebagian besar workload produksinya di AWS, menggunakan beberapa layanan inti, termasuk Amazon S3, Amazon ECS, Amazon RDS, dan Amazon DynamoDB. Berjalan di AWS telah membantu Canva bergerak cepat dalam mengikuti lompatan basis pengguna yang signifikan selama 10 tahun terakhir. Sejak diluncurkan pada tahun 2013, situs Canva telah berkembang dari awal yang sederhana menjadi lebih dari 100 juta pengguna aktif bulanan, yang telah menciptakan lebih dari 15 miliar desain bersama-sama! Canva sekarang memiliki pengguna di 190 negara, yang mendesain dalam lebih dari 100 bahasa berkat penerjemahan luar biasa yang dilakukan oleh tim Internasionalisasi kami.
Desain Canva biasanya dimulai dari template, memungkinkan kreator dengan mudah mengambil gambar, grafik, animasi, dan video dari library kami yang berisi lebih dari 75 juta stok foto dan grafik. Namun, jumlah ini relatif kecil dibandingkan dengan jumlah total konten yang kami simpan. Ini karena Canva memungkinkan setiap brand untuk membuat dan mempublikasikan template, media, dan konten mereka sendiri, yang mengarah ke masifnya konten buatan pengguna yang perlu kami simpan di suatu tempat!

Template dari sebuah brand untuk sebuah presentasi Canva
Amazon S3 memberi kami solusi penyimpanan yang andal, durabilitas yang terjamin, dan berbiaya rendah. Secara khusus, Amazon S3 menyediakan berbagai storage class yang dirancang untuk pola akses dan workload yang berbeda. Memahami perbedaan antara storage class S3 ini sangat penting untuk pengoperasian yang hemat biaya pada skala besar. Di seluruh lingkungan produksi Canva, kami menyimpan lebih dari 230 petabyte data di Amazon S3, dan sebuah bucket S3 terbesar kami mencapai 45 petabyte! Dalam posting blog ini, kita akan membahas bagaimana kami dapat memiliki visibilitas atas data dengan jumlah sebesar ini dan bagaimana memindahkan data sebesar besar ini ke Amazon S3 Glacier Instant Retrieval yang dapat memenuhi kebutuhan penggunaan kami dan menghemat jutaan dolar setiap tahun.
Storage class di Amazon S3
Amazon S3 memiliki beberapa storage class yang dapat Anda pilih berdasarkan data akses, ketahanan, dan persyaratan biaya dari workload Anda, seperti yang ditunjukkan pada diagram berikut.
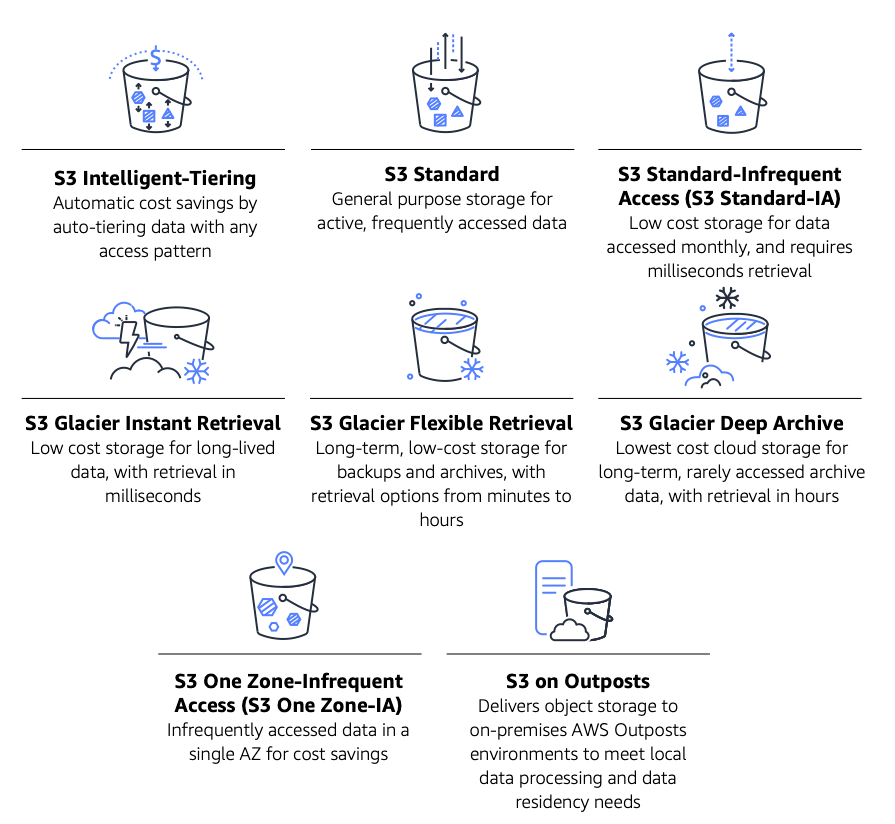
Gambar 1. Storage class di Amazon S3
Untuk library umum template, stok foto, dan grafik Canva, storage class S3 Standard paling cocok untuk kami. Banyak pengguna sering mengakses konten ini setiap hari, jadi menyimpannya di storage class yang dioptimalkan untuk data yang sering diakses berfungsi dengan sempurna. Sebaliknya, desain pengguna dan gambar serta media yang mereka upload cenderung diakses dalam waktu singkat. Pengguna datang ke Canva, membuat desain mereka, mempresentasikan atau mencetaknya, dan biasanya tidak sering kembali ke desain lama setelah selesai. Untuk jenis konten ini, kami secara historis memilih untuk menggunakan storage class S3 Standard-Infrequent Access (S3 Standard-IA) karena lebih hemat biaya daripada S3 Standard sambil tetap menawarkan waktu pengambilan yang cepat. Kami menyederhanakan sedikit di sini, jadi jika Anda tertarik dengan gambaran yang lebih lengkap tentang pola akses basis pengguna kami yang beragam, bacalah posting blog terbaru kami “Memahami Basis Pengguna yang Beragam dengan Segmentasi Frekuensi Berskala”.
Untuk beberapa kasus penggunaan tertentu, seperti arsip log dan backup, kami juga menggunakan S3 Glacier Flexible Retrieval. S3 Glacier Flexible Retrieval sangat ideal untuk data yang dapat diambil dalam beberapa menit hingga beberapa jam. Persyaratan ini dapat diterima untuk arsip log dan backup, yang mungkin hanya perlu diakses pada saat tertentu saja dan jarang, tetapi umumnya storage class ini tidak cocok untuk konten yang sering diakses contohnya adalah konten buatan pengguna seperti yang kita miliki dengan template, stock foto, dan grafik.
Ketika AWS meluncurkan S3 Glacier Instant Retrieval pada November 2021, AWS menawarkan kombinasi terbaik dari dua tipe kondisi untuk data yang jarang diakses, yaitu penyimpanan arsip berbiaya rendah, dan pengambilan cepat dalam milidetik. Jadi tentu saja, ini mendorong kami untuk bertanya berapa banyak yang dapat kami hemat dengan memigrasikan data kami yang jarang diakses ke storage class S3 Glacier Instant Retrieval ini. Dan bucket mana yang harus kami migrasi?
Memahami data yang dimiliki
Meskipun kami tahu konten buatan pengguna kami cenderung diakses segera setelah dibuat, kami tidak sepenuhnya yakin akan detailnya. Kami sebelumnya menggunakan S3 lifecycle policy yang akan mentransisikan data dari S3 Standard ke S3 Standar-IA setelah 30 hari tetapi belum menganalisis penghematan itu. Tool yang baru dirilis yang dapat memberi kita pemahaman akan hal ini adalah S3 Storage Class Analysis, yang dapat kita aktifkan pada level bucket. Storage Class Analysis menyajikan beberapa grafik yang memberikan gambaran berharga.
Grafik berikut mereferensikan data yang disimpan dalam S3 Standard saja dan menunjukkan total byte yang disimpan dan tingkat pengambilan dipecah berdasarkan usia data (yaitu, hari sejak data dibuat). Total byte yang disimpan turun secara drastis setelah 30 hari karena lifecycle yang disebutkan sebelumnya. Tingkat pengambilan juga turun drastis setelah 15 hari pertama, sejalan dengan pola akses yang diharapkan yang kami sebutkan sebelumnya.
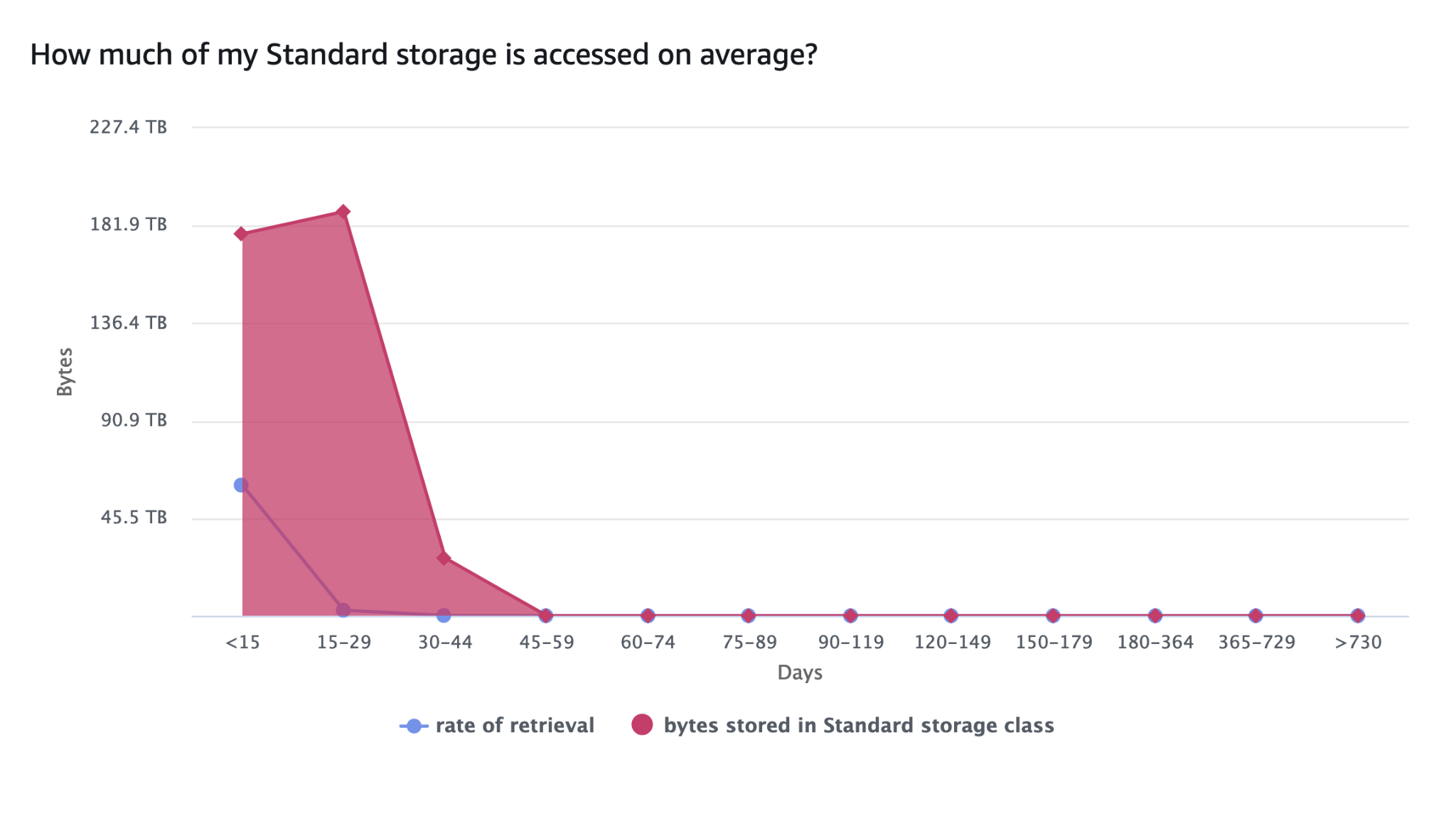
Gambar 2: Pola akses dari Amazon S3 Standard dari waktu-ke-waktu
Grafik berikutnya menunjukkan informasi yang sama, tetapi untuk data yang disimpan dalam S3 Standard-IA. Byte yang disimpan tampak agak aneh, tetapi melihat dari dekat sumbu Hari, lihat bahwa periode waktu menjadi lebih lama (15 hari pertama, lalu 30, lalu 180, lalu 365). Jika Anda meratakan grafik ini agar memiliki periode waktu yang sama, itu akan terlihat sangat mirip dengan pertumbuhan pengguna Canva dari waktu ke waktu. Namun yang penting, tingkat pengambilan terlihat cukup datar di semua periode waktu.

Gambar 3: Pola akses storage Amazon S3 Standard-IA dari waktu-ke-waktu
Grafik terakhir dalam analisis kami menunjukkan jumlah total data yang diakses di seluruh bucket di setiap storage class. Dalam bucket tertentu ini, sekitar 10% dari total data disimpan dalam S3 Standard, sementara 90% disimpan dalam S3 Standard-IA. Grafik menunjukkan bahwa 60-70% dari semua data yang diakses berasal dari S3 Standard, sedangkan 30-40% berasal dari S3 Standard-IA. Ini sangat sesuai dengan model harga S3 untuk storage class ini. S3 Standard memiliki biaya penyimpanan yang lebih tinggi per GB, tetapi biaya akses data yang sangat rendah, sementara S3 Standard-IA (dan S3 Glacier Instant Retrieval) memiliki biaya penyimpanan per GB yang lebih rendah tetapi biaya akses data yang lebih tinggi.
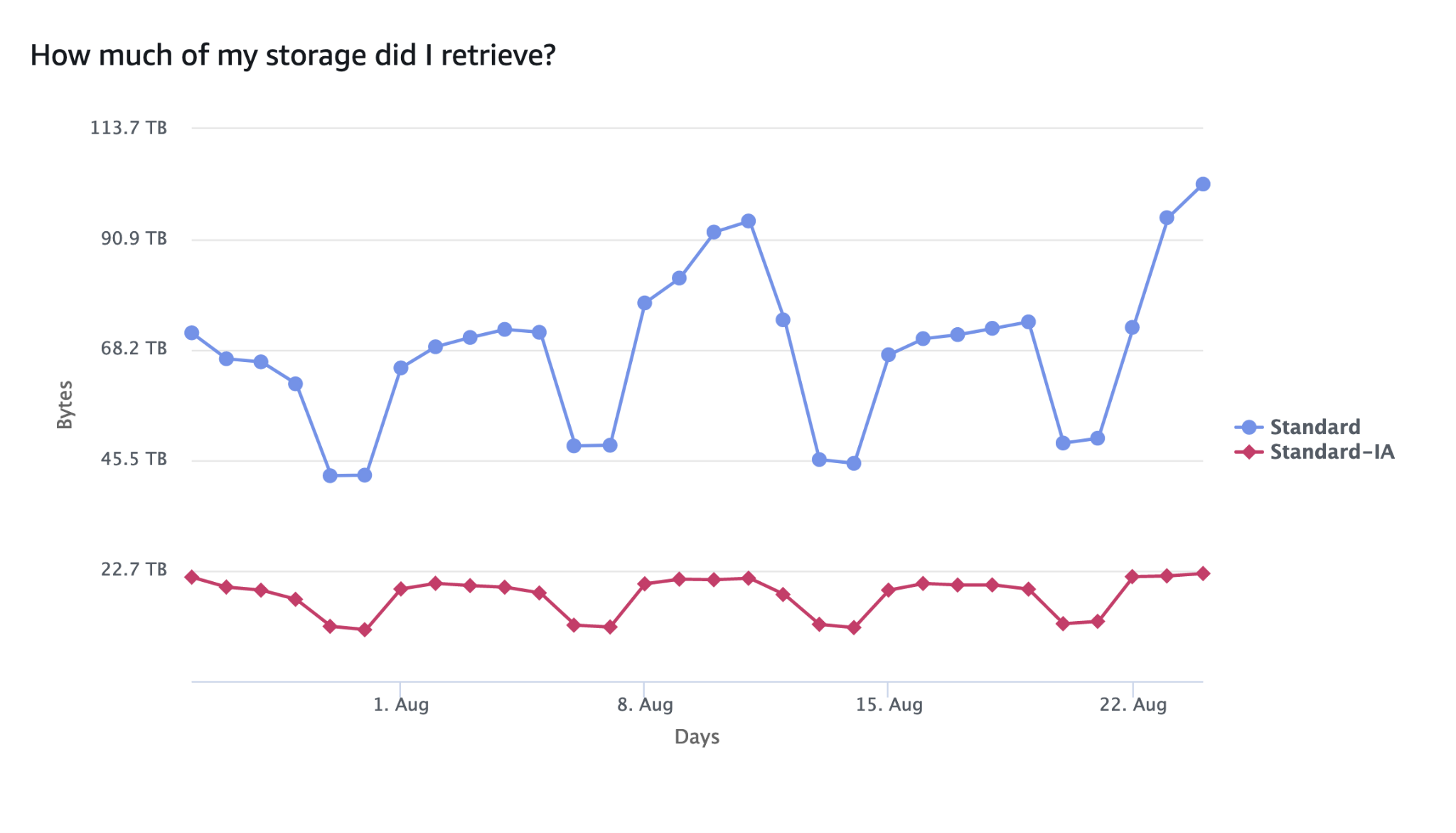
Gambar 4: Akses Amazon S3 storage class relatif terhadap pola akses dari waktu-ke-waktu
Pola akses data ini adalah tipikal untuk banyak bucket yang kami gunakan untuk menyimpan konten buatan pengguna. Jadi tentunya kita bisa menambahkan lifecycle policy, mentransisikan semuanya ke S3 Glacier Instant Retrieval dan mengubahnya dalam sehari, bukan? Yah, seperti semua yang ada di software, itu tergantung.
Biaya untuk transisi
Saat mentransisikan objek antar S3 storage class, Anda membayar per request. Misalnya, memindahkan objek ke S3 Glacier Instant Retrieval memerlukan biaya $0,02 per 1.000 objek. Namun, data S3 kami di Canva berisi lebih dari 300 miliar objek, jadi transisi semuanya tanpa memikirkannya akan menelan biaya lebih dari $6 juta. Ini adalah alasan lain mengapa penting untuk memaksimalkan visibilitas biaya penyimpanan dan memiliki pemahaman yang baik tentang pola data Anda.
Menariknya, biaya transisi ini didasarkan pada jumlah objek yang kita pindahkan. Pada saat yang sama, potensi penghematan dari S3 Glacier Instant Retrieval sebagian besar berasal dari jumlah total data di storage class. Selain itu, biaya untuk mentransisikan semua data adalah one-time fee, sementara penghematan dari perubahan storage class ini berlangsung seterusnya.
Ini berarti kami dapat menghitung perkiraan waktu yang diperlukan untuk berpindah dari S3 Standard ke S3 Glacier Instant Retrieval untuk mencapai break even point berdasarkan ukuran objek rata-rata dalam bucket. Misalnya, jika Anda perlu mentransisikan sejumlah kecil objek yang sangat besar, hasilnya terjadi dengan cepat. Di sisi lain, transisi sejumlah besar objek kecil dapat memakan waktu berbulan-bulan sebelum mencapai break even point. Kami melakukan analisis yang sama untuk S3 Standard-IA karena kami sudah memiliki sejumlah besar data di storage class tersebut untuk penghematan biaya.

Gambar 5: Amazon S3 Standard ke Amazon S3 Glacier Instant Retrieval breakeven (bulan) dan Amazon S3 Standard-IA ke Amazon S3 Glacier Instant Retrieval breakeven (bulan)
Sumbu x grafik dimulai di sebelah kiri pada 128 KB karena itu adalah ukuran minimum objek yang dapat ditagih (pada billing) di S3 Standard-IA dan S3 Glacier Instant Retrieval (bahkan jika objek Anda lebih kecil dari 128 KB, Anda masih ditagih untuk 128 KB). Oleh karena itu, waktu untuk mencapai break even point ketika berpindah dari S3 Standard-IA ke S3 Glacier Instant Retrieval adalah konstan untuk objek di bawah 128 KB karena semua objek ditagih sebagai 128 KB. Anda dapat melihat ini di grafik berikut.
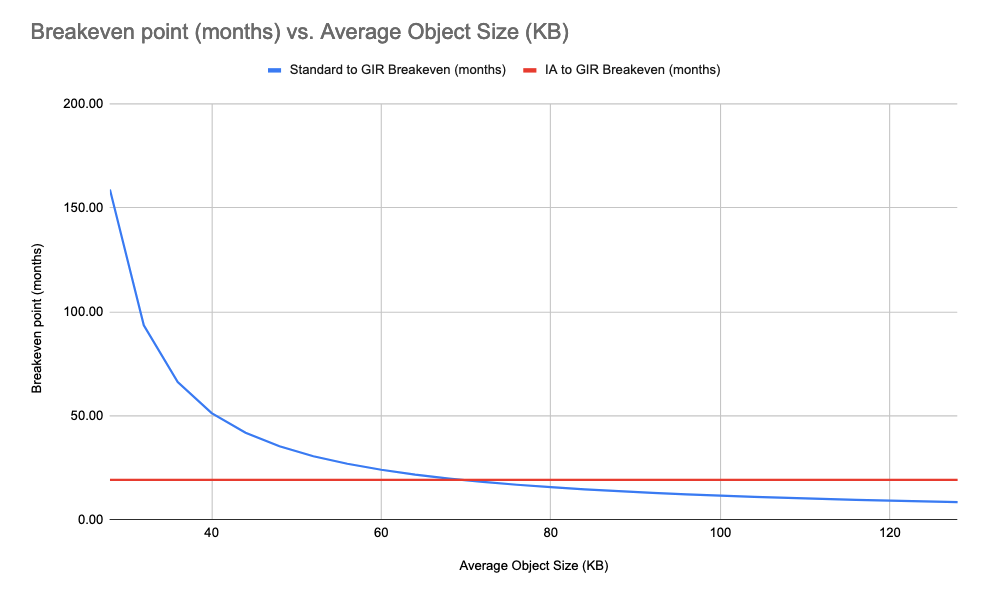
Gambar 6: Amazon S3 Standard ke Amazon S3 Glacier Instant Retrieval breakeven (bulan) dan Amazon S3 Standard-IA ke Amazon S3 Glacier Instant Retrieval breakeven (bulan) vs ukuran rata-rata objek (KB)
Grafik ini menjelaskan break even point untuk objek yang lebih kecil dari 128 KB. Penting untuk dicatat lagi bahwa objek di S3 Standard-IA dan S3 Glacier Instant Retrieval selalu ditagih seolah-olah berukuran 128 KB. Oleh karena itu, ada titik (sekitar 20 KB) di mana lebih hemat biaya untuk menyimpan objek dalam S3 Standard daripada menyimpannya di S3 Standard-IA atau S3 Glacier Instant Retrieval.
Yang penting adalah bahwa kita akan melihat return of investment positif lebih cepat dari memindahkan objek S3 Standard-IA ke S3 Glacier Instant Retrieval pada bucket dengan ukuran objek yang rata-rata lebih besar. Ketika kami melakukan analisis ini, kami memutuskan untuk menargetkan bucket (dengan pola penggunaan yang sesuai dari bagian sebelumnya) dengan ukuran objek rata-rata 400 KB atau lebih terlebih dahulu karena bucket ini akan menunjukkan return of investment positif dalam waktu 6 bulan atau kurang.
Kesimpulan
Upaya yang diperlukan untuk melakukan migrasi diatas sangat sedikit, yang merupakan impian dari engineer! Kami mengaplikasikan lifecycle policy ke setiap bucket, dan dengan cepat memigrasikan hampir 80 miliar objek dalam waktu kurang lebih dua hari. Pada saat menulis blog ini, sekitar 130 petabyte dari total 230 petabyte data Canva di S3 berada di S3 Glacier Instant Retrieval. Kami menyadari bahwa pemilihan storage class tersebut mengurangi biaya pada data pengguna kami yang jarang diakses. Pilihan terbaik ada pada keduanya yaitu S3 Standard-IA dan S3 Glacier Flexible Retrieval.
Canva menghemat sekitar $300.000 per bulan ($3,6 juta per tahun) berkat perubahan ini, dan mengingat jumlah data buatan pengguna yang kami simpan terus bertambah, penghematan ini terus bertambah seiring waktu. Sangat penting untuk diingat bahwa penghematan ini mengharuskan kami untuk terlebih dahulu memahami pola akses untuk data kami, serta satu kali pengeluaran sebesar $1,6 juta untuk mentransisikan sekitar 80 miliar objek. Secara keseluruhan ini berarti bahwa kami melihat ROI positif hanya beberapa bulan setelah melakukan transisi, yang masih terbilang cukup fantastis!
AWS telah menjadi mitra yang hebat dalam hal ini dan terus berinvestasi dalam storage class yang sesuai untuk kebutuhan, untuk membantu pelanggan dengan kasus penggunaan dalam skala apa pun. Terima kasih telah membaca posting blog ini! Jangan ragu untuk meninggalkan komentar Anda di bagian komentar.
Konten dan opini yang ada dalam posting ini adalah dari pihak ketiga dan AWS tidak bertanggung jawab terhadap konten dan akurasi dari posting ini.
Artikel ini diterjemahkan dari artikel asli dengan judul “How Canva saves over $3 million annually in Amazon S3 costs” yang ditulis oleh Josh Smith, Engineering Lead for the Core Data team di Canva.