Amazon Web Services ブログ
Amazon Neptune を使用して顧客識別グラフを作成する
顧客識別グラフは、プライバシー保護に準拠した方法を用いて、クッキー、デバイス識別子、IP アドレス、E メール ID、および内部エンタープライズ ID などの複数の識別子を既知の個人または匿名プロファイルにリンクすることにより、顧客と見込み顧客の単一の統合ビューを提供します。また、デバイスやマーケティングチャネル全体での顧客の行動や好みをキャプチャします。これは中央ハブとして機能し、ターゲットを絞った広告、顧客体験のパーソナライズ、およびマーケティング効果の測定を可能にします。
この記事では、AWS で顧客識別グラフを作成する方法の概要を説明し、主要なビジネスドライバー、課題、ユースケース、顧客の成功事例、およびソリューションの利点を確認します。また、ソリューション、サンプルデータモデル、AWS CloudFormation テンプレート、および開発を開始するために使用できるその他の技術コンポーネントについても説明します。
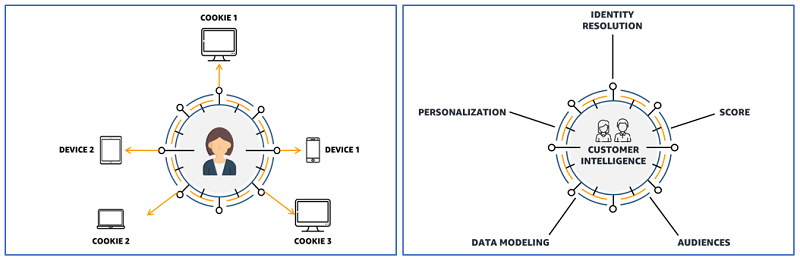
次の図は、デバイス識別子、クッキー、ブラウザ、動作など、特定のユーザーに関するデータのコレクションを顧客識別グラフプラットフォームで示しています。これにより、ID 解決、スコアリング、パーソナライズ用のオーディエンスセグメントの作成が行えるようになります。
ソリューションは、クラウドの専用グラフデータベースである Amazon Neptune で構築します。Amazon Neptune は何十億もの相互接続された関係を保存およびナビゲートするのに理想的で、リアルタイムの広告およびマーケティングアプリケーション向けにミリ秒のレイテンシーをサポートします。このソリューションは、機械学習モデルの構築、トレーニング、開発のためのフルマネージドプラットフォームである Amazon SageMaker も使用しています。このソリューションでは、ホストされた Jupyter ノートブックを提供できる Amazon SageMaker を使用して、顧客識別グラフデータをロードし、一般的なユースケースに対してクエリします。
プライバシー保護に準拠したカスタマーエクスペリエンス
マーケティング担当者、広告主、デジタルプラットフォームは、顧客のニーズを特定、理解、予測し、さらにプライバシー保護に準拠した方法を使用してエクスペリエンスのパーソナライズを大規模に行う必要があります。
このような期待に応えることは、多くの面で困難に直面します。ビジネスの観点からは、マーケティング、販売、ロイヤルティなどの企業サイロからデータを集約する必要があります。テクノロジーの観点から見ると、グローバルに拡張できる安全で柔軟なデータベースプラットフォームが必要です。これにより、デバイス、顧客 ID、チャネル、および設定間の相互に関連する何十億もの関係について、リアルタイムの顧客識別および行動グラフを継続的に維持できます。
AWS で顧客識別グラフソリューションを構築する
顧客識別グラフソリューションにより、参照アプリケーションがもたらされます。そのため、独自のビジネスルールを使って、コスト効率が高く、スケーラブルで、安全で、可用性の高い顧客データプラットフォームを構築できます。顧客シグナルにリアルタイムで応答して、広告およびマーケティングアプリケーションとカスタマージャーニーオーケストレーションを自動化できます。
このソリューションにより、マーケッター、アドテック、マーテック、ゲーム、メディア、およびエンターテインメント企業は、何百万もの顧客プロファイルの何十億もの関係から洞察をリアルタイムでキャプチャしてアクティブ化できます。Zeta Global、NBCUniversal、Activision Blizzard などのお客様は、Amazon Neptune を使用して識別グラフを作成し、消費者のジャーニーをキャプチャして、何百万ものユーザーのために広告、コンテンツ、ゲーム内体験をパーソナライズしています。
このソリューションには、サンプルデータモデル、CloudFormation テンプレート、Amazon SageMaker ノートブックが含まれており、データベースで一般的なユースケースをクエリすることができます。完全な顧客識別グラフソリューションは、通常、取り込みパイプライン、データ検証、クレンジング、ID 解決アルゴリズム、ID グラフデータベース、およびオーディエンスセグメンテーションで構成されています。この記事では、Neptune データベースへのデータの取り込み、相互に関連するプロファイルをキャプチャするためのデータモデリング、およびクエリメカニズムに焦点を当てます。これにより、クロスデバイスグラフ、オーディエンスセグメンテーションなどのユースケースをサポートます。
ユースケース
このソリューションの一般的なユースケースを次に示します。
- クロスデバイスと関心グラフ – カスタマージャーニーとデバイス全体で費やした時間を分析して、特定のユーザーの関心を見つます。これにより、広告をパーソナライズします
- 決めかねている消費者を納得させる – 以前訪問したウェブサイトに基づいて e コマースサイトの訪問者を特定します
- ブランドごとのオーディエンスセグメンテーション – ブランドとカテゴリの関心またはアフィニティスコアに基づいて特定のオーディエンスを作成します
- インタレストベース広告 – 以前特定のウェブサイトで示した関心に基づいて広告をターゲティングします
- 購入インサイトへのアーリーアダプターパス – 最初のサイト訪問から製品購入の確定まで、ウェブサイトで顧客がたどった経路を分析します
- 類似顧客を特定 – ある製品を購入した一般的なオーディエンスの特性をクエリします
グラフデータベースは、顧客識別グラフを構築して相互に関連する何十億もの関係をキャプチャしてリンクし、ユースケースをサポートするのに最適です。従来のリレーショナルデータベース管理システム (RDBMS) は、トランザクションの整合性を必要とするエンタープライズアプリケーションを構築するのに理想的です。ただし、顧客デバイスグラフなどの高度に接続されたデータセットをキャプチャし、大規模なミリ秒のレイテンシーをサポートするようには設計されていません。同様に、SaaS ソリューションは、複数の関係をキャプチャしてモデル化するための柔軟性が限られています。対照的に、グラフデータベースは、1 対多および多対多の関係を簡単にモデル化し、柔軟に再設計し、物理ストレージレベルで関係を格納して、低レイテンシークエリをサポートします。
顧客識別グラフソリューションは、Neptune に基づいて構築されています。Neptune は、高速で信頼性が高い、完全マネージド型グラフデータベースサービスです。これにより、高度に接続されたデータセットと連携するアプリケーションの構築と実行が容易になります。Neptune の中核にあるのは、何十億もの関係を保存し、ミリ秒単位のレイテンシーでグラフをクエリするために最適化された、専用の高性能グラフデータベースエンジンです。
ソリューションの概要
Neptune で顧客識別グラフを作成するには、次の 3 つの主要コンポーネントが必要です。
- 顧客識別グラフデータモデル – まず、データを収集して、グラフデータベース (Neptune) にロードできる形式のグラフデータモデルに変換する必要があります。この記事では、ナレッジグラフに必要なデータ要素とそのデータの潜在的なソースについても説明します。
- Jupyter ノートブックと Python ライブラリ – グラフを簡単にクエリし、データを探索し、結果を視覚化する方法が必要です。これには、Jupyter ノートブックを使用します。これは、多くのデータエンジニアやデータサイエンティストが使用する一般的なフレームワークです。Amazon SageMaker は、フルマネージド型の Jupyter ノートブック環境を提供します。これは、ノートブックインスタンス機能を介して利用できます。
- Neptune クラスターと Amazon SageMaker ノートブックインスタンスの作成: Neptune クラスターを作成し、データをロードして、Amazon SageMaker ノートブックインスタンスを事前に構築された CloudFormation スタックに接続します。
顧客識別グラフデータモデル
前述のように、顧客識別グラフは、デバイス識別子、ブラウザ、クッキー、アクセスしたサイトや最近使用したモバイルアプリの履歴など、特定のユーザーに関するデータのコレクションです。また、さまざまなアカウントプロファイルを通じてもたらされる情報に基づいて、ユーザーに関する既知の人口統計を含めることもできます。このすべてのデータは高度に関連付けられていて、広告とマーケティングの取り組みをパーソナライズしてターゲティングするための洞察をもたらします。
この関連データは、次のように、いくつかの場所で探すことができます。
- ウェブおよびクリックストリームログ。これらは、ユーザーの行動に関する優れた情報源です
- クッキーまたはデバイス ID (iOS の IDFA や Android デバイスの Android ID など)。これらは、モバイルアプリケーションを通じて公開されます
これらのデータセットを収集した後、さまざまな要素を特定のユーザー ID またはユーザーのグループに照合して関連付ける方法を決定する必要があります。
この記事では、「CIKM Cup 2016 Track 1: Cross-Device Entity Linking Challenge」のオープンデータセットを使用しています。生データセットには、デバイスのリストからのウェブサイト訪問を匿名化した 3 つの CSV ファイルと JSON ファイルが含まれています。1 人のユーザーに複数のデバイスをリンクできます。
データセット自体は、それほど興味深いものではありません。データは、ハッシュキーを使用して高度に難読化され、匿名化されます。次の図は、データを視覚化したものです。これには、特定のユーザーごとの永続的な ID、一時的な ID で表されるユーザーのデバイス ID またはクッキー、デバイスにリンクされたウェブサイト訪問 (または一時的な ID) が含まれます。このオープンデータセットに含まれているデータは、ウェブサーバーのログやクリックストリームデータを介して見つけられるものと非常によく似ています。

このデータセットは、iOS および Android デバイスユーザーの主な関心事や地域ごとの関心事など、顧客の識別と行動に関する限られた洞察を提供します。顧客識別グラフの実際の例をシミュレートするために、データセットには次の属性も含まれています。
- ユーザー属性 – デバイスのオペレーティングシステム、ブラウザの種類、E メール (オプトイン用)
- ID グループ – 世帯またはオーディエンスセグメントにグループ化された永続的な ID、およびスポーツ愛好家やガジェットオタクなどのアフィニティグループ
- ウェブサイトグループ – ニュースや政治、スポーツ、ショッピング、自動車など、メインコンテンツのテーマや主題で分類されたウェブサイト
- ユーザーの場所 – オプトインされた IP アドレス。これにより、ユーザーの市と州の情報を取得
- 時間とデータの属性 – 時間、曜日や季節ごとの顧客の行動パターン
次の図は、作成済みの部分と組み合わせたオープンデータセットの完全な図です。

前述のように、この記事では、さまざまな永続 ID を ID グループにリンクするために使用する ID 解決アルゴリズムは提供していません。大規模な ID 解決アーキテクチャでは、顧客識別グラフの一部を使用して ID 解決ワークフローを推進できます。この記事では、IDグループが作成され、データセットの一部として提供されます。
使いやすいように、データセットは次の場所にある Amazon Simple Storage Service (Amazon S3) に保存されています。
各 CSV ファイルは、前述のデータモデルからの頂点 (ノード) とエッジのセットを表しています。使用する CSV 形式は、Neptune bulk load API を使うために必要な形式に準拠しています。これにより、このデータを Amazon S3 から Neptune に直接ロードできます。
Jupyter ノートブックと Python ライブラリ
Jupyter ノートブックは、ブラウザから Python コードを実行するための基礎となる Python コンソールのウェブフロントエンドで構成されています。これは、Apache TinkerPop/Gremlin と RDF/SPARQL の両方の Python ライブラリとうまく連携します。これらは、Neptune がサポートする 2 つのグラフフレームワークとクエリ言語です。この記事では、Apache TinkerPop と Gremlin を使用してデータセットをモデル化し、クエリを実行します。Gremlin には、Jupyter ノートブック内で直接使用して顧客識別グラフをクエリできる gremlin-python クライアントがあります。
ノートブック内のコードを簡略化するために、スクリプトのカスタム Python ライブラリは、各ユースケースの視覚化データの多くを生成するのに役立ちます。視覚化データは、networkx と呼ばれる Python ライブラリを使用して生成されます。このようなライブラリは、Clearcode と共同で開発されました。同社は、広告およびマーケティングテクノロジーアプリケーションの開発を専門とする AWS テクノロジーパートナーです。
Neptune クラスターと Amazon SageMaker ノートブックインスタンスを作成する
この記事では、必要なリソースとインフラストラクチャを作成し、データを Neptune に自動的にロードする CloudFormation テンプレートを提供します。スタックは以下のリソースを作成します。
- 3 つのサブネットと VPC Amazon S3 エンドポイントを持つ Neptune VPC
- 適切なサブネット、パラメータ、およびセキュリティグループを持つ、単一の r4.xlarge インスタンスを含む Neptune クラスター
- Neptune が Amazon S3 からデータをロードすることを許可するIAM ロール
- Amazon SageMaker Jupyter ノートブックインスタンス、IPython Gremlin 拡張モジュール、Gremlin コンソール、および一部のサンプルノートブックコンテンツ
次の図は、ソリューションのアーキテクチャを示しています。

本ソリューションでデプロイする Neptune および Amazon SageMaker のリソースにはコストが発生します。Amazon SageMaker がホストするノートブックを使用すると、Amazon EC2 インスタンスと Amazon SageMaker ノートブックに対して料金がかかります。Neptune の場合、コストは、クラスター内で使用される Neptune インスタンス、クラスター内のデータによって消費されるストレージ容量、インスタンスとストレージ間の I/O で構成されています。
この記事では、バルクロード用の r5.12xlarge を備えた Neptune クラスターと、ml.m4.xlarge Amazon SageMaker ノートブックインスタンスを使用します。ソリューションをデプロイした後、示された例を実行するのに十分なリソースを提供しながら、Neptune インスタンスを r5.2xlarge にスケールダウンしてコストを節約できます。r5.2xlarge にスケールダウンすることにより、このソリューションの実行にかかるコストは 1 時間あたり約 2 USD になります。
- お客様が希望するリージョンに対応するスタックを起動します。
リージョン 表示 起動 米国東部 (オハイオ) 表示 
米国東部 (バージニア北部) 表示 米国西部 (オレゴン) 表示 欧州 (アイルランド) 表示 スタックを起動すると、[スタックのクイック作成] ページが開きます。
- [機能] の下で、AWS Identity and Access Management (IAM) を作成するために必要な権限をスタックに与える 2 つのチェックボックスをオンにします
- [スタックの作成] を選択します。
 スタックを起動してデータを Neptune にロードするのに約 1 時間かかります。
スタックを起動してデータを Neptune にロードするのに約 1 時間かかります。 - スタックの準備ができたら、AWS CloudFormation コンソールで、デプロイした CloudFormation スタックのルートスタックを選択します (スタックの名前を変更していない場合は、
Identity-Graph-Sampleという名前になっているはずです)。 - [出力] タブで、SageMakerNotebook 出力を見つけ、提供されたリンクを選択します。
これにより、CloudFormation スタックが作成した Amazon SageMaker ノートブックの Jupyter コンソールが起動します。

- 下の Jupyter ウィンドウで Neptune ディレクトリを開き、[
identity-graph] サブディレクトリを選択します。 identity-graph-sample.ipynbノートブックを選択します。

identity-graph-sample.ipynbノートブックに接続したら、このチュートリアルの最初のセクションのデータを読み、各ユースケースを実行できます。ノートブックの各コードブロックを実行するには、コードブロックを強調表示して、[実行] を選択します。演習ごとにロードされる依存関係があるため、必ず各コードブロックを順番に実行してください。後の演習の中には、前の演習の出力に依存しているものもあります。
 残りの例についてはこのノートブックを通して説明します。まず、Neptune にロードしたデータセットの形状とサイズを示す例から始めます。次に、前に示した顧客識別グラフのユースケースに進みます。
残りの例についてはこのノートブックを通して説明します。まず、Neptune にロードしたデータセットの形状とサイズを示す例から始めます。次に、前に示した顧客識別グラフのユースケースに進みます。
まとめ
この記事では、Neptune をグラフデータベースとして使用して、顧客識別グラフをホストする方法を示しました。顧客識別グラフは、より大きな ID 解決アーキテクチャの一部として使用できます。この記事の CloudFormation テンプレートを使用するか、GitHub リポジトリでデータセット、Python ライブラリ、Jupyter ノートブックのソースコードを確認できます。
お客様の導入事例
以下は、ソリューションを使用してユーザーエクスペリエンスをパーソナライズしたお客様の導入事例です。お客様は re:Invent 2019 で経験を共有しました。
Zeta Global は、マーケティング担当者が顧客とつながり、パーソナライゼーションを推進するのに役立つデータ駆動型のマーケティングテクノロジープラットフォームです。同社は、Neptune を使用して AWS で顧客識別グラフと洞察プラットフォームを構築しました。同社の ID 解決データストアには、24 時間年中無休の高可用性システムに 10 億の顧客プロファイルがあり、1 日あたり 4 億 5000 万のクエリを受信し、平均応答時間は 35 ミリ秒です。詳細については、YouTube の動画「Reimagining advertising analytics and identity resolution at scale」をご覧ください。
NBCUniversal は、Neptune を使用してユーザーのコンテンツエクスペリエンスをパーソナライズし、レガシーシステムと比べて最大 40% のコスト削減を実現しました。詳細については、YouTube で「Real-world customer use cases with Amazon Neptune」をご覧ください。
Activision Blizzard のコンシューマーテクノロジーチームは、re:Invent 2019 でプレゼンテーションを行い、Amazon Neptune を使用して Call of Duty のプレイヤージャーニーと状態のデータを保存し、数百万人のプレイヤーが機械学習ベースのパーソナライズされたプレイヤーエクスペリエンスを享受できる方法を紹介しました。詳細については、「Call of Duty が ML を使用してプレイヤーエンゲージメントをパーソナライズする方法」を参照してください。
開発者向けのリソース
以下に、顧客識別グラフと Amazon Neptune の使用を開始するために必要なリソースを示します。まだ行っていない場合は、上記の Launch Stack リンクを参照して、識別グラフサンプルアプリケーションを起動してください。このアプリケーションで使用されているコードの詳細については、GitHub をご覧ください。
- Amazon Neptune リソース
- GitHub の AWS 上のグラフデータベース用のリファレンスアーキテクチャ
- ベストプラクティス: Neptune を最大限に活用する
- Neptune グラフデータモデル
- GitHub 上の Amazon Kinesis Data Streams から Amazon Neptune への書き込み
著者について

Rajesh Wunnava は、AWS のデジタル広告とマーケティングの業界ソリューションのグローバルヘッドです。彼は、代理店、アドテック、およびマーテックのお客様のニーズに応えるための業界戦略と AWS ソリューションの開発を担当しています。彼は、データおよびテクノロジー機能を通じて、広告、メディア、およびエンターテインメント業界で 15 年以上貢献してきた経験があります。AWS に入社する前は、Nielsen/Gracenote で製品広告およびパーソナライゼーションの VP を務めていました。他にも、Mindshare と Warner Music Group で製品およびテクノロジーを担当した経験を持っています。

Taylor Riggan はAWS のグラフデータベースを専門とするシニアスペシャリストソリューションアーキテクトです。彼はあらゆる規模のお客様と協力して、リファレンスアーキテクチャの作成、サンプルソリューション、実践的なワークショップの開催を通じてお客様が専用の NoSQL データベースを学習し使用できるように支援しています。