分散型機械学習 (ML) ワークロードの実行に関しては、AWS はマネージドサービスとセルフサービスサービスの両方を提供しています。Amazon SageMaker は、エンジニアリング、データサイエンス、および研究チームが時間を節約し、運用オーバーヘッドを削減できるマネージドサービスです。AWS ParallelCluster は、コンピューティングインフラストラクチャをより直接的に制御したいお客様向けのオープンソースのセルフサービスクラスター管理ツールです。この記事では、AWS で分散 ML を実行する方法について説明します。Amazon SageMaker を使用した分散トレーニングの詳細については、以下の「Horovod を使用した TensorFlow 分散トレーニングの起動」と「マルチリージョンサーバーレス分散トレーニング」の記事を参照してください。
AWS ParallelCluster は、AWS クラウドでのハイパフォーマンスコンピューティング (HPC) クラスターのデプロイと管理に役立つ、AWS がサポートするオープンソースのクラスター管理ツールです。AWS ParallelCluster を使用すると、データサイエンティストと研究者は、必要なコンピューティングリソースと共有ファイルシステムを自動的にセットアップすることで、伸縮自在にスケーリングされた AWS リソースで使い慣れた作業環境を再現できます。Jupyter、Conda、MXNet、PyTorch、TensorFlow などの広くサポートされているデータサイエンスおよび ML ツールにより、低オーバーヘッドのスケーリングによる柔軟でインタラクティブな開発が可能になります。これらの機能により、AWS ParallelCluster 環境は、分散モデルの開発とトレーニングをサポートする ML 研究環境に最適です。
AWS ParallelCluster は、コンピューティングリソースのオンデマンド割り当てを中心に構築されたスケーラブルな研究ワークフローを可能にします。AWS ParallelCluster は、単一のハイパワー GPU 対応ワークステーションで作業し、潜在的に十分に活用するのではなく、GPU 対応コンピューティングワーカーのオンデマンドフリートを管理します。これにより、並列トレーニング実験の簡単なスケールアップと、リソースが不要な場合の自動スケールダウンが可能になり、コストを最小限に抑え、研究者の時間を節約できます。アタッチされた Amazon FSx ファイルシステムは、開発中に従来の高性能 Lustre ファイルシステムを利用しますが、モデルとデータを低コストの Amazon S3 にアーカイブします。
次の図は、AWS ParallelCluster ベースの研究環境を示しています。自動スケーリングされた Amazon EC2 リソースはリモートストレージにアクセスし、モデルとデータは S3 にアーカイブされます。
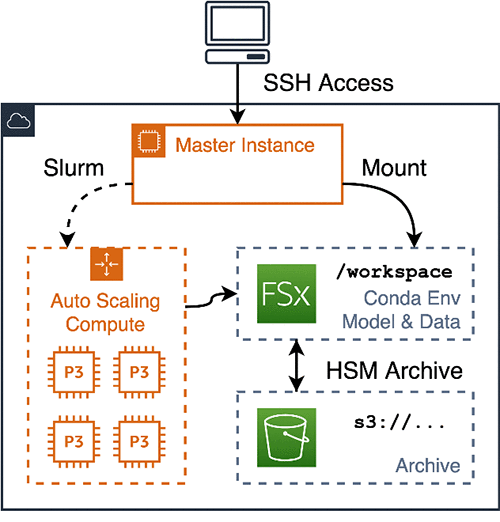
この記事では、このアーキテクチャを実装する完全な AWS ParallelCluster 環境をセットアップ、実行、および分解する方法を示します。この記事では、言い換えタスクでの BERT モデルの微調整 と英独機械翻訳モデルのトレーニングという 2 つの NLP チュートリアルを行います。これには次の手順が含まれます。
- AWS ParallelCluster の設定とセットアップ
- ML と NLP パッケージの Conda ベースのインストール
- 初期インタラクティブモデルトレーニング
- 並列モデルのトレーニングと評価
- データのアーカイブとクラスターの分解
チュートリアルでは標準ツールを使用してワークフローをレイアウトし、研究要件に合わせてワークフローを調整できます。
前提条件
この記事では、m5 と p3 EC2 インスタンス、それに Amazon FSx と Amazon S3 ストレージの組み合わせを使用します。さらに、GPU 対応のインスタンスをトレーニングに使用しているため、このチュートリアルではアカウントを AWS の無料利用枠から外します。開始する前に、次の前提条件を満たしてください。
- AWS アカウントをセットアップし、管理者権限を持つアクセストークンを作成する。
- ターゲット AWS リージョンで、少なくとも 1 つの
m5.xlarge、3 つの p3.2xlarge、および 3 つの p3.8xlarge オンデマンドインスタンスの割り当ての増加をリクエストする。
クライアントとクラスターのセットアップ
専用の Conda 環境で aws-parallelcluster クライアントを使用して、ワークステーションの 1 回限りのセットアップと設定を開始します。後で作業を再現するために必要な正確な依存関係のセットを含むサブプロジェクトごとに分離環境を設定するときに、このパターンを再利用します。
Conda のインストール
ベース Miniconda 環境の 1 回限りのインストールを実行し、シェルを初期化して Conda を有効にします。この記事は macOS ワークステーションから機能します。ご希望のプラットフォームのダウンロード URL を使用してください。この設定により、基本環境がセットアップされ、対話型シェルでアクティブ化されます。次のコードをご覧ください。
@work:~$ wget -O miniconda.sh \
"https://repo.anaconda.com/miniconda/Miniconda3-latest-MacOSX-x86_64.sh" \
&& bash miniconda.sh -p ~/.conda \
&& ~/.conda/bin/conda init
クライアント環境のセットアップ
pcluster_client という Conda 環境を使用して、AWS ParallelCluster と AWS CLI ツールをインストールします。この環境は、クライアントとシステム環境を分離します。最初に、環境名と依存関係のバージョンを指定して environment.yml ファイルを作成します。conda env update を呼び出して、ライブラリをダウンロードしてインストールします。次のコードをご覧ください。
(base) @work:~$ cat > pcluster_client.environment.yml <<EOF
name: pcluster_client
dependencies:
- python=3.7
- pip
- conda-forge::jq
- conda-forge::awscli
- pip:
- aws-parallelcluster >= 2.4
EOF
(base) @work:~$ conda env update -f pcluster_client.environment.yml
pcluster の設定とストレージの作成
AWS ParallelCluster を設定するには、conda activate で pcluster_client 環境を設定し、デフォルトの設定フローで aws と pcluster を設定します。詳細については、「AWS ParallelCluster の設定」を参照してください。
設定中に、id_rsa 公開キーを AWS にアップロードし、プライベートキーをローカルに保存します。プライベートキーは pcluster インスタンスへのアクセスに使用します。次のコードをご覧ください。
(base) @work:~$ conda activate pcluster_client
(pcluster_client) @work:~$ aws configure
[...]
(pcluster_client) @work:~$ aws ec2 import-key-pair \
--key-name $USER --public-key-material file://~/.ssh/id_rsa.pub
{
"KeyFingerprint": [...]
[...]
}
(pcluster_client) @work:~$ pcluster configure
[...]
AWS ParallelCluster を設定したら、次のコードを使用して、データとモデルの永続ストレージ用の S3 バケットを作成します。
(pcluster_client) @work:~$ export AWS_ACCOUNT=$(aws sts get-caller-identity | jq -r ".Account")
(pcluster_client) @work:~$ export S3_BUCKET=pcluster-training-workspace-$AWS_ACCOUNT
(pcluster_client) @work:~$ aws s3 mb s3://$S3_BUCKET
make_bucket: pcluster-training-workspace-[...account id...]
次のコードを使用して、GPU 対応クラスターと Amazon FSx ファイルシステムの設定エントリを追加します。
(pcluster_client) @work:~$ cat >> ~/.parallelcluster/config <<EOF
[cluster p3.2xlarge]
key_name = $USER
vpc_settings = public
scheduler = slurm
base_os = centos7
fsx_settings = workspace
initial_queue_size = 1
max_queue_size = 3
master_instance_type = m5.xlarge
compute_instance_type = p3.2xlarge
Amazon FSx
shared_dir = /workspace
storage_capacity = 3600
import_path = s3://$S3_BUCKET
export_path = s3://$S3_BUCKET
imported_file_chunk_size = 1024
EOF
クラスターの作成とブートストラップ
設定後、クラスターをオンラインにします。このコマンドは、永続的なマスターインスタンスを作成し、Amazon FSx ファイルシステムをアタッチし、p3 クラスの Auto Scaling グループをセットアップします。クラスターの作成が完了したら、Miniconda を再度セットアップします。今回は、すべてのマスターノードと計算ノードでアクセス可能な /workspace ファイルシステムにインストールします。次のコードをご覧ください。
(pcluster_client) @work:~$ pcluster create -t p3.2xlarge training
Beginning cluster creation for cluster: training
Creating stack named: parallelcluster-training
Status: [...]
(pcluster_client) @work:~$ pcluster ssh training
[centos@ip-172-31-48-17 ~]$ wget -O miniconda.sh \
"https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh" \
&& bash miniconda.sh -p /workspace/.conda \
&& /workspace/.conda/bin/conda init
[centos@ip-172-31-48-17 ~]$ exit
計算クラスターには、単一の m5 クラスインスタンスが含まれ、p3.2xlarge インスタンスは slurm job manager を介して利用できます。インタラクティブな salloc セッションを使用して、srun コマンドを介して p3 リソースにアクセスできます。自動スケーリングクラスター戦略の重要な意味は、クラスター全体ですべてのコードとデータが利用できですが、接続された GPU へのアクセスは srun を介してアクセスする計算ノードに制限されることです。これは nvidia-smi への呼び出しを介して実証できます。これは、アタッチされたリソースのステータスを報告します。次のコードをご覧ください。
(pcluster_client) @work:~$ pcluster ssh training
# Execution on the master node can not access gpu resources.
(base) [centos@ip-172-31-48-17 ~]$ hostname
ip-172-31-48-17
(base) [centos@ip-172-31-48-17 ~]$ nvidia-smi
NVIDIA-SMI has failed [...]
# Use salloc to bring a compute node online, then use calls to srun to
# execute commands on the GPU-enabled compute node.
(base) [centos@ip-172-31-48-17 ~]$ salloc
salloc: Required node not available (down, drained or reserved)
salloc: Pending job allocation 2
salloc: job 2 queued and waiting for resources
salloc: job 2 has been allocated resources
salloc: Granted job allocation 2
(base) [centos@ip-172-31-48-17 ~]$ srun hostname
ip-172-31-48-226
(base) [centos@ip-172-31-48-17 ~]$ srun nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 418.56 Driver Version: 418.56 CUDA Version: 10.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr.ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla V100-SXM2... Off | 00000000:00:1E.0 Off | 0 |
| N/A 34C P0 39W / 300W | 0MiB / 16130MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
(base) [centos@ip-172-31-48-17 ~]$ exit
exit
salloc: Relinquishing job allocation 2
AWS ParallelCluster は、計算 Auto Scaling グループの自動管理を実行します。これにより、salloc の有効期間中、計算ノードが実行され、使用可能になり、ジョブが終了してから数分後にアイドル状態の計算ノードが終了します。
モデルのトレーニング
初期 GPU 対応インタラクティブトレーニング
最初の研究タスクでは、標準の自然言語プロセスワークフローを実行し、事前にトレーニングされた BERT モデルを特定のサブタスクに合わせて微調整します。モデルの依存関係を使用して作業環境を確立し、事前にトレーニングされたモデルとトレーニングデータをダウンロードし、GPU でトレーニングを微調整します。PyTorch の事前トレーニング済み BERT サンプルの詳細については、GitHub repo を参照してください。
まず、プロジェクトの 1 回限りのセットアップを実行します。これは、ライブラリ依存関係のある Conda 環境とトレーニングデータのあるワークスペースです。プロジェクトの依存関係を指定する environment.yml を記述し、conda env update を呼び出して環境を作成およびインストールし、conda env activate を呼び出します。トレーニングデータを /workspace/bert_tuning にフェッチします。次のコードをご覧ください。
(base) [centos@ip-172-31-48-17 ]$ mkdir /workspace/bert_tuning
(base) [centos@ip-172-31-48-17 ]$ cd /workspace/bert_tuning
(base) [centos@ip-172-31-48-17 bert_tuning]$ cat > environment.yml <<EOF
name: bert_tuning
dependencies:
- python=3.7
- pytorch::pytorch=1.1
- scipy=1.2
- scikit-learn=0.21
- pip
- requests
- tqdm
- boto3
- pip:
- pytorch_pretrained_bert==0.6.2
EOF
(base) [centos@ip-172-31-48-17 bert_tuning]$ conda env update
[...]
# To activate this environment, use
#
# $ conda activate bert_tuning
(base) [centos@ip-172-31-48-17 bert_tuning]$ conda activate bert_tuning
(bert_tuning) [centos@ip-172-31-48-17 bert_tuning]$ wget \
https://gist.githubusercontent.com/W4ngatang/60c2bdb54d156a41194446737ce03e2e/raw/17b8dd0d724281ed7c3b2aeeda662b92809aadd5/download_glue_data.py
(bert_tuning) [centos@ip-172-31-48-17 bert_tuning]$ python download_glue_data.py --data_dir glue
Downloading and extracting Cola...
[...]
Completed!
依存関係をダウンロードしたら、トレーニングスクリプトを取得し、対話型セッションで微調整を実行します。文書化された非クラスターの例との唯一の違いは、トレーニングスクリプトを直接呼び出すのではなく、salloc --exclusive srun を使用してトレーニングを実行することです。/workspace Amazon FSx ファイルシステムにより、計算ノードは Conda 環境にインストールされたライブラリとモデル定義、トレーニングデータ、モデルチェックポイントにアクセスできます。前と同様に、トレーニングの実行に GPU 対応ノードを割り当てます。これは、実行が完了した後に終了します。次のコードをご覧ください。
(bert_tuning) [centos@ip-172-31-48-17 bert_tuning]$ wget \
https://raw.githubusercontent.com/huggingface/pytorch-pretrained-BERT/v0.6.2/examples/run_classifier.py
(bert_tuning) [centos@ip-172-31-48-17 bert_tuning]$ salloc --exclusive srun \
python run_classifier.py \
--task_name MRPC \
--do_train \
--do_eval \
--do_lower_case \
--data_dir glue/MRPC/ \
--bert_model bert-base-uncased \
--max_seq_length 128 \
--train_batch_size 32 \
--learning_rate 2e-5 \
--num_train_epochs 3.0 \
--output_dir mrpc_output
salloc: Required node not available (down, drained or reserved)
salloc: Pending job allocation 3
salloc: job 3 queued and waiting for resources
salloc: job 3 has been allocated resources
salloc: Granted job allocation 3
06/12/2019 02:15:36 - INFO - __main__ - device: cuda n_gpu: 1, distributed training: False, 16-bits training: False
[...]
Epoch: 100%|██████████| 3/3 [01:11<00:35, 35.90s/it]
[...]
Evaluating: 100%|██████████| 51/51 [00:01<00:00, 41.42it/s]
06/12/2019 02:17:48 - INFO - __main__ - ***** Eval results *****
06/12/2019 02:17:48 - INFO - __main__ - acc = 0.8455882352941176
06/12/2019 02:17:48 - INFO - __main__ - acc_and_f1 = 0.867627742865973
06/12/2019 02:17:48 - INFO - __main__ - eval_loss = 0.42869279022310297
06/12/2019 02:17:48 - INFO - __main__ - f1 = 0.8896672504378283
06/12/2019 02:17:48 - INFO - __main__ - global_step = 345
06/12/2019 02:17:48 - INFO - __main__ - loss = 0.15244172460035138
salloc: Relinquishing job allocation 3
(bert_tuning) [centos@ip-172-31-48-17 bert_tuning]$ exit
マルチ GPU トレーニング
salloc の使用は、インタラクティブなモデル開発、短いトレーニングジョブ、およびテストに役立ちます。ただし、現代の研究の大部分は、モデルの開発と調整のために複数の長期実行トレーニングジョブを必要とします。より計算集約的な実験をサポートするには、クラスターをマルチ GPU コンピューティングインスタンスに更新し、非対話型トレーニングに sbatch を使用します。実験のために複数のトレーニングジョブをキューに入れ、AWS ParallelCluster に実行のためにコンピューティンググループをスケールアップさせ、実験の完了後にスケールダウンさせます。
ワークステーションから、マルチ GPU クラスターの設定を追加し、残りのシングル GPU ノードをシャットダウンし、クラスター設定をマルチ GPU p3.8xlarge コンピューティングインスタンスに更新します。次のコードをご覧ください。
(pcluster_client) @work:~$ cat >> ~/.parallelcluster/config <<EOF
[cluster p3.8xlarge]
key_name = $USER
vpc_settings = public
scheduler = slurm
base_os = centos7
fsx_settings = workspace
initial_queue_size = 1
max_queue_size = 3
master_instance_type = m5.xlarge
compute_instance_type = p3.8xlarge
EOF
(pcluster_client) @work:~$ (
pcluster stop training
pcluster update training -t p3.8xlarge
pcluster start training
)
Stopping compute fleet : training
Updating: training
Calling update_stack
Status: parallelcluster-training - UPDATE_COMPLETE
Starting compute fleet : training
(pcluster_client) @work:~$ pcluster ssh training
(base) [centos@ip-172-31-48-17 ~]$ salloc srun nvidia-smi
salloc: Granted job allocation 4
Wed Jun 12 06:02:25 2019
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 418.56 Driver Version: 418.56 CUDA Version: 10.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr.ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla V100-SXM2... Off | 00000000:00:1B.0 Off | 0 |
| N/A 47C P0 52W / 300W | 0MiB / 16130MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 1 Tesla V100-SXM2... Off | 00000000:00:1C.0 Off | 0 |
| N/A 46C P0 52W / 300W | 0MiB / 16130MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 2 Tesla V100-SXM2... Off | 00000000:00:1D.0 Off | 0 |
| N/A 49C P0 58W / 300W | 0MiB / 16130MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 3 Tesla V100-SXM2... Off | 00000000:00:1E.0 Off | 0 |
| N/A 47C P0 57W / 300W | 0MiB / 16130MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
salloc: Relinquishing job allocation 4
この記事では、FairSeq NLP フレームワークを使用して、トランスフォーマーベースの英語からドイツ語への翻訳モデルを再トレーニングします。前と同様に、新しいワークスペースと環境をセットアップし、トレーニングデータをダウンロードします。次のコードをご覧ください。
(base) [centos@ip-172-31-48-17 ~]$ mkdir /workspace/translation
(base) [centos@ip-172-31-48-17 ~]$ cd /workspace/translation
(base) [centos@ip-172-31-48-17 translation]$ cat > environment.yml <<EOF
name: translation
dependencies:
- python=3.7
- pytorch::pytorch=1.1
- pip
- tqdm
- pip:
- fairseq==0.6.2
EOF
(translation) [centos@ip-172-31-48-17 translation]$ conda env update && conda activate translation
(translation) [centos@ip-172-31-48-17 translation]$ wget \
https://raw.githubusercontent.com/pytorch/fairseq/v0.6.2/examples/translation/prepare-iwslt14.sh \
&& bash prepare-iwslt14.sh
[...]
(translation) [centos@ip-172-31-48-17 translation]$ fairseq-preprocess \
--source-lang de --target-lang en \
--trainpref iwslt14.tokenized.de-en/train \
--validpref iwslt14.tokenized.de-en/valid \
--testpref iwslt14.tokenized.de-en/test \
--destdir data-bin/iwslt14.tokenized.de-en
[...]
| Wrote preprocessed data to data-bin/iwslt14.tokenized.de-en
トレーニングデータをダウンロードして前処理した後、トレーニングスクリプトを記述し、クイックインタラクティブトレーニング実行を開始して、スクリプトが起動し、いくつかのエポックのトレーニングが成功したことを確認します。最初のジョブは CUDA_VISIBLE_DEVICES を介した単一の GPU に制限され、約 60 秒/エポックでトレーニングする必要があります。およそ 1 エポック経過した後、ctrl-C で割り込みます。基礎となるモデルは分散データ並列トレーニングをサポートしているため、単一のワーカーで追加の GPU を使用したほぼ線形のパフォーマンススケーリングが期待できます。4 つすべてのデバイスを使用した 2 番目のジョブのトレーニングは、約 15〜20 秒/エポックでトレーニングし、効果的なマルチ GPU スケーリングを確認し、再度割り込みます。次のコードをご覧ください。
(translation) [centos@ip-172-31-48-17 translation]$ mkdir -p checkpoints/transformer
(translation) [centos@ip-172-31-48-17 translation]$ (cat > train_transformer && chmod +x train_transformer) <<EOF
#!/bin/bash
fairseq-train data-bin/iwslt14.tokenized.de-en \
-a transformer_iwslt_de_en --optimizer adam --lr 0.0005 -s de -t en \
--label-smoothing 0.1 --dropout 0.3 --max-tokens 4000 \
--min-lr '1e-09' --lr-scheduler inverse_sqrt --weight-decay 0.0001 \
--criterion label_smoothed_cross_entropy --max-update 50000 \
--warmup-updates 4000 --warmup-init-lr '1e-07' \
--adam-betas '(0.9, 0.98)' --fp16 \
--save-dir checkpoints/transformer
EOF
(translation) [centos@ip-172-31-48-17 translation]$ CUDA_VISIBLE_DEVICES=0 salloc --exclusive \
srun -X --pty ./train_transformer
[...]
| training on 1 GPUs
[...]
^C
[...]
KeyboardInterrupt
(translation) [centos@ip-172-31-48-17 translation]$ salloc --exclusive \
srun -X --pty ./train_transformer
[...]
| training on 4 GPUs
[...]
^C
[...]
KeyboardInterrupt
最初の検証後、sbatch を実行して完全なトレーニング実行をスケジュールします。sinfo コマンドは実行中のクラスターに関する情報を提供し、squeue はバッチジョブのステータスを表示します。ジョブログの tail を使用すると、トレーニングの進行状況を監視でき、squeue によって報告された計算ノードアドレスへの ssh アクセスにより、リソース使用率を確認できます。前と同様に、AWS ParallelCluster はバッチトレーニングジョブ用にコンピューティングクラスターをスケールアップし、バッチトレーニングの完了後に GPU 対応インスタンスをリリースします。次のコードをご覧ください。
(translation) [centos@ip-172-31-48-17 translation]$ sbatch --exclusive \
--output=train_transformer.log \
./train_transformer
Submitted batch job 9.
(translation) [centos@ip-172-31-21-188 translation]$ sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
compute* up infinite 1 alloc ip-172-31-20-225
(translation) [centos@ip-172-31-21-188 translation]$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
9 compute sbatch centos R 0:22 1 ip-172-31-20-225
(translation) [centos@ip-172-31-21-188 translation]$ tail train_transformer.log
[...]
| loaded checkpoint checkpoints/transformer/checkpoint_last.pt (epoch 5 @ 1413 updates)
| epoch 006 | loss 7.268 | [...]
| epoch 006 | valid on 'valid' subset | loss 6.806 | [...]
(translation) [centos@ip-172-31-21-188 translation]$ ssh -t ip-172-31-20-225 watch nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 418.56 Driver Version: 418.56 CUDA Version: 10.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr.ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla V100-SXM2... Off | 00000000:00:1B.0 Off | 0 |
| N/A 63C P0 214W / 300W | 3900MiB / 16130MiB | 83% Default |
+-------------------------------+----------------------+----------------------+
| 1 Tesla V100-SXM2... Off | 00000000:00:1C.0 Off | 0 |
| N/A 64C P0 175W / 300W | 4110MiB / 16130MiB | 82% Default |
+-------------------------------+----------------------+----------------------+
| 2 Tesla V100-SXM2... Off | 00000000:00:1D.0 Off | 0 |
| N/A 60C P0 164W / 300W | 4026MiB / 16130MiB | 65% Default |
+-------------------------------+----------------------+----------------------+
| 3 Tesla V100-SXM2... Off | 00000000:00:1E.0 Off | 0 |
| N/A 62C P0 115W / 300W | 3994MiB / 16130MiB | 74% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 41837 C ...ntos/.conda/envs/translation/bin/python 3889MiB |
| 1 41838 C ...ntos/.conda/envs/translation/bin/python 4099MiB |
| 2 41839 C ...ntos/.conda/envs/translation/bin/python 4015MiB |
| 3 41840 C ...ntos/.conda/envs/translation/bin/python 3983MiB |
+-----------------------------------------------------------------------------+
ジョブの完了には約 80〜90 分かかります。これで、インタラクティブな翻訳を介してモデルを評価できます。次のコードをご覧ください。
(translation) [centos@ip-172-31-21-188 translation]$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
(translation) [centos@ip-172-31-21-188 translation]$ fairseq-interactive \
data-bin/iwslt14.tokenized.de-en \
--path checkpoints/transformer/checkpoint_best.pt --beam 5 --remove-bpe <<EOF
hallo welt
EOF
Namespace([...])
| [de] dictionary: 8848 types
| [en] dictionary: 6632 types
| loading model(s) from checkpoints/transformer/checkpoint_best.pt
| Type the input sentence and press return:
S-0 hallo welt
H-0 -0.32129842042922974 hello world .
P-0 -0.8112 -0.0095 -0.4157 -0.2850 -0.0851
Jupyter とその他の HTTP サービス
インタラクティブなノートブックベースの開発は、データ探索、モデル分析、およびプロトタイプ作成に頻繁に使用されます。AWS ParallelCluster ワーカーで実行されているノートブックサーバーを起動してアクセスできます。jupyterlab をプロジェクトのワークスペース環境に追加し、srun をノートブックに追加します。次のコードをご覧ください。
(translation) [centos@ip-172-31-48-17 translation]$ conda install jupyterlab
[...]
# unset XDG_RUNTIME_DIR and listen on node name to allow ssh tunnel.
(translation) [centos@ip-172-31-48-17 translation]$ \
XDG_RUNTIME_DIR= \
salloc --exclusive srun -X --pty bash -c \
'jupyter lab --ip=$SLURMD_NODENAME'
[...]
The Jupyter Notebook is running at:
http://ip-172-31-21-236:8888/?token=[...token...]
別のターミナルで、Jupyter によって報告されたノードアドレスとアクセストークンを使用してノートブックワーカーへの pcluster ssh トンネルを設定し、ローカルブラウザーを開きます。次のコードをご覧ください。
(pcluster_client) @work:~$ pcluster ssh training -L 8888:ip-172-31-21-236:8888 -N&
(pcluster_client) @work:~$ jobs
[1]+ Running. pcluster ssh training -L 8888:ip-172-31-21-236:8888 -N &
(pcluster_client) @work:~$ open http://localhost:8888/?token=[...token...]
同様のアプローチを使用して、クラスター環境で tensorboard などのツールを実行できます。
ストレージとクラスターの分解
モデルのトレーニングと評価を完了した後、Amazon FSx の階層ストレージサポートを介して / workspace ファイルシステムを Amazon S3 にアーカイブできます。詳細については、「データリポジトリの使用」を参照してください。hsm_archive アクションが約 60〜90 分で完了したら、次のコードを使用して AWS CLI 経由で s3 エクスポートバケットの内容を確認します。
(pcluster_client) @work:~$ pcluster ssh training
# Find and archive all files in the /workspace
(base) [centos@ip-172-31-48-17 translation]$ \
find /workspace -type f -print0 \
| xargs -0 -n 16 sudo lfs hsm_archive
# Returns 0 when all archive operations are complete
(base) [centos@ip-172-31-48-17 translation]$ \
find /workspace -type f -print0 \
| xargs -0 -n 16 -P 8 sudo lfs hsm_action | grep "ARCHIVE" | wc -l
0
(base) [centos@ip-172-31-48-17 translation]$ exit
(pcluster_client) @work:~$ aws s3 ls \
s3://pcluster-training-workspace-$(aws sts get-caller-identity | jq -r ".Account")
PRE bert_tuning/
PRE translation/
(pcluster_client) @work:~$ pcluster delete training
Deleting: training
[...]
後で同じ設定で pcluster create を呼び出すと、クラスターが復元され、S3 アーカイブから /workspace が事前入力されます。
複数のクラスター
AWS ParallelCluster を使用して、複数の同時計算クラスターを管理できます。たとえば、CPU クラスターと GPU クラスターの混在を使用して、重要な CPU バウンド処理を伴う前処理または分析タスクをサポートできます。さらに、これにより、単一の共有 AWS ワークスペースで複数の研究者に独立したクラスターを提供できます。
このワークフローをマルチクラスター設定に適応させるのは比較的簡単です。スタンドアロンの Amazon FSx ファイルシステムをセットアップし、amazon-fsx-workshop/lustre GitHub リポジトリの既存の CloudFormation テンプレートを介してそのライフサイクルを管理します。エクスポートプレフィックスを指定し、次のコードで ~/.parallelcluster/config を更新します。
Amazon FSx
shared_dir = /workspace
fsx_fs_id = <filesystem id>
複数のクラスターが /workspace ファイルシステムを共有するようになり、個々のクラスターのライフタイムから切り離されました。任意のクラスターから lfs hsm_archive の呼び出しを使用して、潜在的に毎晩の cron を介して、ファイルシステムの内容を S3 にバックアップできます。
容量管理
AWS ParallelCluster は、標準の Auto Scaling グループを介して EC2 インスタンスのコンピューティングクラスターを管理します。これにより、クラスターをスケーリングする際の容量管理に既存の AWS ネイティブツールを使用できます。AWS ParallelCluster は、cluster_type 設定を介してコンピュートフリート内でスポットインスタンスを使用するための組み込みサポートを備えており、利用可能な場合はリザーブドインスタンスの容量を使用します。On-Demand Capacity Reservations を使用して、AWS ParallelCluster がターゲットコンピューティングフリートサイズに合わせて迅速にスケーリングできるようにすることができます。
結論
コンピューティングインフラストラクチャをより直接的に制御したい場合は、AWS ParallelCluster ベースのワークフローが、機械学習の応用研究に理想的な作業環境を提供します。迅速なクラスターのセットアップ、スケーリング、および更新により、適切なインスタンスタイプの識別や並列トレーニング実行のマルチインスタンススケーリングなど、モデリングタスクのインタラクティブな調査が可能になります。Conda 環境と高性能の Amazon FSx ファイルシステムは、使い慣れたファイルインターフェイスを提供し、S3 への再現可能なアーカイブモデルアーティファクトの重要であるが差別化されていない重いリフティングを透過的に処理します。
AWS ParallelCluster の設定およびインタラクティブでスケーラブルな ML または HPC 研究環境の構築の詳細については、AWS ParallelCluster ユーザーガイドまたは aws-parallelcluster GitHub リポジトリを参照してください。
著者について
 Alex Ford は AWS のアプライドサイエンティストです。彼は、機械学習と自然科学が交わる地点の新興アプリケーションに情熱を注いでいます。余暇には、カスカディア沈み込み帯の地理と地質を調査し、インデックスバソリスをこよなく愛しています。
Alex Ford は AWS のアプライドサイエンティストです。彼は、機械学習と自然科学が交わる地点の新興アプリケーションに情熱を注いでいます。余暇には、カスカディア沈み込み帯の地理と地質を調査し、インデックスバソリスをこよなく愛しています。