Amazon Web Services ブログ
Category: Amazon Redshift

AWS Glue Data Catalog のテーブル統計自動収集機能の紹介 – Amazon Redshift と Amazon Athena のクエリパフォーマンス向上
AWS Glue Data Catalog で、新しいテーブルの統計情報を自動的に生成できるようになりました。この機能により、Amazon Redshift Spectrum と Amazon Athena のコストベースオプティマイザー (CBO) がクエリを最適化し、パフォーマンス向上とコスト削減を実現します。

Amazon Redshift で Apache Iceberg データをクエリするためのベストプラクティス
Amazon Redshift で Apache Iceberg データをクエリする際のベストプラクティスを紹介します。テーブル設計、パーティション化、列選択、統計生成、メンテナンス戦略、マテリアライズドビュー、レイトバインディングビューの活用方法について詳しく説明します。
Amazon S3 ストレージレンズにパフォーマンスメトリクスの追加、数十億のプレフィックスのサポート、S3 Tables へのエクスポートが追加されました
2025 年 12 月 2 日、ストレージのパフォーマンスと使用パターンをより深く理解できる Amazon S […]
Amazon Bedrock Knowledge BasesでSAPおよびエンタープライズデータから新たな可能性を解き放つ
生成AI(Generative AI)の力とエンタープライズデータインテリジェンスを組み合わせた新しいソリューションを見てみましょう。この記事では、Amazon Bedrock Knowledge Basesが組織のSAPおよびエンタープライズデータの活用方法をどのように革新し、イノベーション、効率性、戦略的意思決定のための新たな可能性を創出しているかを探ります。自然言語クエリから自動化されたドキュメント処理、インテリジェントなインサイト生成まで、このソリューションが企業のSAP投資をAI時代の戦略的資産に変革する方法をご紹介します。

AWSとパートナーソリューションによるセキュアなデータメッシュの構築
このブログでは、AWS ネイティブの分析サービスとサードパーティエンジンを同時に活用することを目的としたデータメッシュアーキテクチャを実装するための 3 つの重要な要件を探ります:(1)クロスカタログメタデータフェデレーション、(2)クロスアカウント&クロスエンジンでの認証と認可、(3)分散ポリシーの反映
AWS をデータプロデューサーとコンシューマーの両方として実用的な実装パターンを検討し、Databricks や Snowflake などのパートナーとの統合アプローチを代表例として紹介します。
これらのパターンは、組織が企業全体のガバナンスを維持しながら、データメッシュの中核原則をサポートする柔軟で安全かつスケーラブルなデータアーキテクチャをどのように構築するかを示しています。

Amazon Redshift DC2 ノードタイプから Amazon Redshift Serverless へのアップグレード
Amazon Redshift dense compute (DC2) インスタンスから Amazon Redshift Serverless へデータウェアハウスをアップグレードすることでこれらの利点が得られ、ユーザーエクスペリエンスの向上と運用の簡素化を実現し、より効率的でスケーラブルなデータ分析ソリューションを提供します。
この記事では、DC2 インスタンスから Amazon Redshift Serverless へのアップグレードプロセスをご紹介します。

Amazon Redshift DC2 から RA3 および Amazon Redshift Serverless へのアップグレードのベストプラクティス
Amazon Redshift はコンピュート集約型ワークロードに最適化された DC2(Dense Compute)ノードタイプを提供していました。しかし、これらはコンピュートとストレージを独立してスケーリングする柔軟性に欠け、現在利用可能な多くの最新機能をサポートしていませんでした。分析需要の増大に伴い、多くのお客様が DC2 から RA3 または Amazon Redshift Serverless へアップグレードしています。これらは独立したコンピュートとストレージのスケーリングを提供し、データ共有、ゼロ ETL 統合、Amazon Redshift ML による組み込みの人工知能および機械学習(AI/ML)サポートなどの高度な機能を備えています。
この記事では、ターゲットアーキテクチャと移行戦略を計画するための実践的なガイドを提供し、アップグレードオプション、主要な考慮事項、および成功したシームレスな移行を促進するためのベストプラクティスをカバーしています。
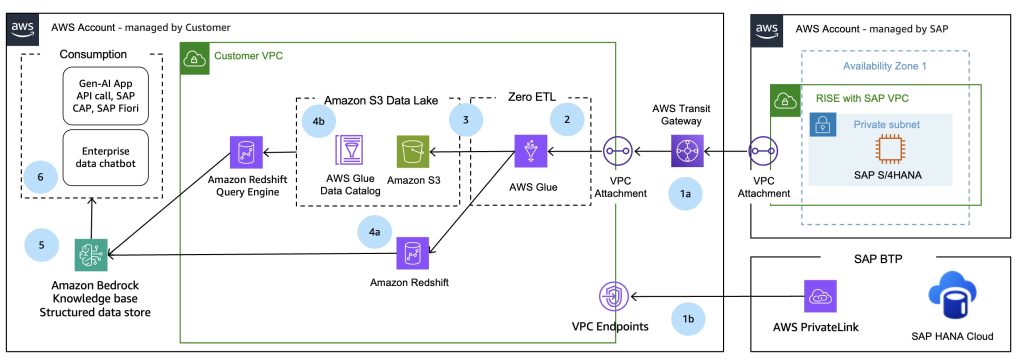
Zero-ETL: AWS によるデータ統合の課題への取り組み
このブログ記事では、Amazon Web Services (AWS) の Zero-ETL を活用することで、データ統合を簡素化すると同時に、パフォーマンスの向上やコストの最適化も実現する方法を紹介します。

Amazon Redshift のユーザー管理を AWS IAM Identity Center に移行して認証を最新化する
Amazon Redshift のローカルユーザー管理を AWS IAM Identity Center に移行する方法を紹介します。RedshiftIDCMigration ユーティリティを使用して、ユーザー、グループ、ロールを IAM Identity Center に移行し、一元化された認証と SSO 機能を実現できます。
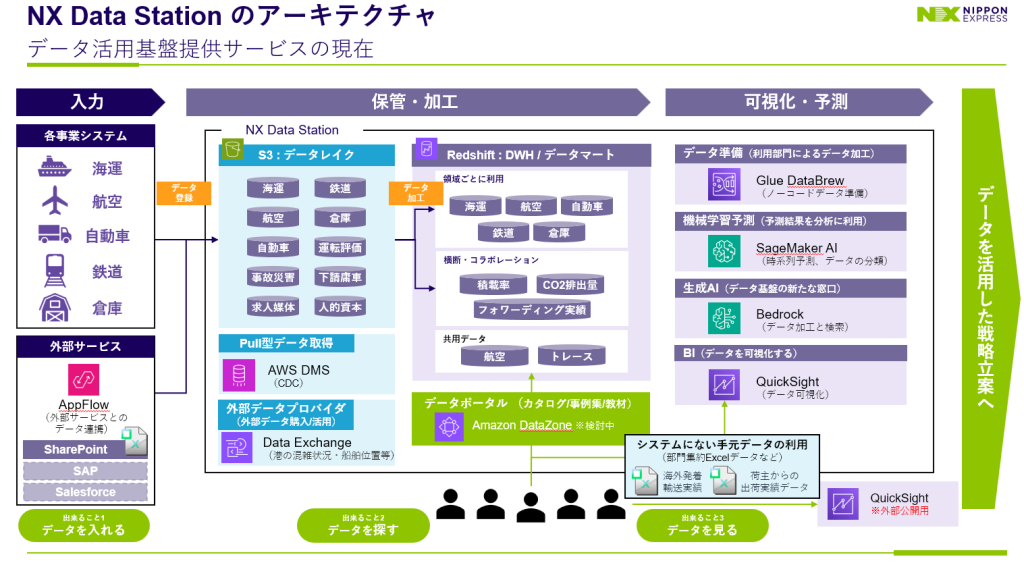
物流業界のチャレンジを支えるデータ活用 – Nippon Express の事例から
物流業界において、特にデータを活用した改善は、物流DXとして総合物流施策大綱でも長年にわたり強く推奨されてきました。このような状況を受けて多くの物流企業がデータ活用を経営戦略の重要項目として位置付けているものの、実態としては有効な施策が打ち出せずにいるケースが多く見受けられます。
本記事ではそういった課題に悩まれる物流事業担当者向けに、データ活用の成功モデルとして日本通運株式会社(以下Nippon Express)のデータ分析基盤「NX Data Station」を解説します。同社は既存リソースを最大限に活用しながら、コスト効果の高いデータ分析基盤を構築し、データを基に業務効率化と意思決定の質向上を実現しています。
記事は2025年7月15日に開催された Amazon SageMaker Roadshow でのNX情報システム および キヤノンITソリューションズ のセッション内容をもとに記載しています。