Amazon Web Services ブログ
Category: Amazon Redshift
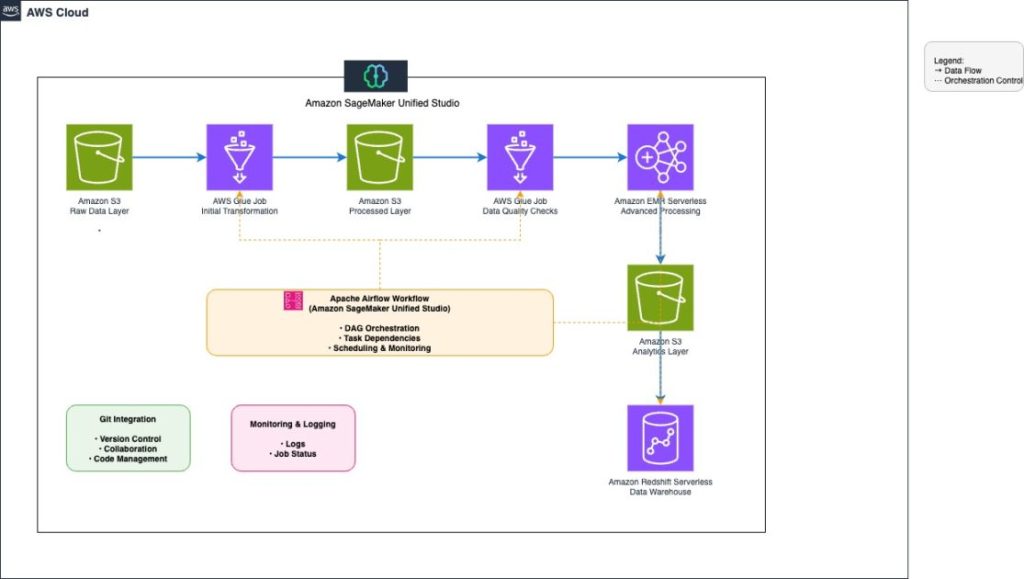
Amazon SageMaker ワークフローによるスケーラブルなエンドツーエンド ETL パイプラインのオーケストレーション
本記事では、Amazon SageMaker Unified Studio ワークフローでコードベースのエンドツーエンド ETL パイプラインを構築・管理する方法を紹介します。AWS Glue、Amazon EMR Serverless、Amazon Redshift Serverless、Amazon MWAA を組み合わせ、EC の顧客行動分析を例に、データ取り込みから変換、品質チェック、データウェアハウスへのロード、日次スケジュール実行まで、単一の統合 UI で構築する手順を解説します。

Fivetran の Managed Data Lake Service の CDC で実現する業務システムから Apache Iceberg へのリアルタイムデータ連携
本記事は アマゾン ウェブ サービス ジャパン合同会社 ソリューションアーキテクト 疋田、畠 と、Fivetr […]
Vanguard が Amazon Redshift マルチウェアハウスアーキテクチャで分析基盤を刷新
Vanguard の Financial Advisor Services 部門が、Amazon Redshift のマルチウェアハウスアーキテクチャを活用して分析基盤を変革した事例を紹介します。単一クラスターから、プロビジョンドクラスターと Serverless を組み合わせたワークロード分離アーキテクチャへの移行により、ETL の SLA 遵守率 100%、月間 50 万以上のクエリ対応、BI ダッシュボード 25 倍増を実現しました。さらに、データメッシュアーキテクチャへの進化についても解説します。

Amazon Redshift と AWS IAM Identity Center できめ細かなアクセス許可を複数のウェアハウスに展開する
本記事では、Amazon Redshift フェデレーテッドアクセス許可と AWS IAM Identity Center を使用して、複数のデータウェアハウスのきめ細かなアクセス許可をスケーラブルに管理する方法を紹介します。Enterprise Data Warehouse (EDW) でセキュリティポリシーを一度定義すれば、Sales や Marketing のコンシューマーウェアハウスに自動適用されるアーキテクチャを解説します。

AWS Weekly Roundup: 20 周年を迎えた Amazon S3、Amazon Route 53 Global Resolver の一般提供など (2026 年 3 月 16 日)
Amazon S3 の一般提供が開始されたのは、20 年前の先週にあたる 2006 年 3 月 14 日でした […]

Amazon Redshift Templates で運用を標準化する
本記事では、Amazon Redshift の新機能 Redshift Templates を紹介します。COPY コマンドのパラメータを再利用可能なデータベースオブジェクトとして保存し、データロード操作の標準化、一貫性の向上、保守の簡素化を実現する方法を、業界別のユースケースとともに解説します。
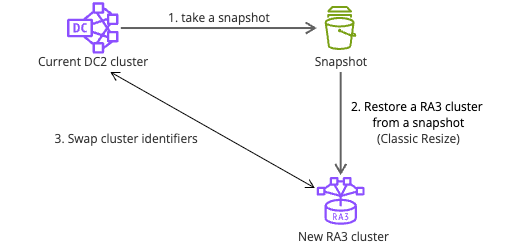
Amazon Redshift DC2 インスタンスからの移行アプローチ:お客様事例
本記事では、小売業の大手企業が Amazon Redshift DC2 から RA3 インスタンスへ移行した事例を紹介します。Blue-Green デプロイメントアプローチで安全に移行し、ETL クエリパフォーマンスの向上とストレージ容量の拡大を実現しました。マテリアライズドビューや AutoMV などの RA3 固有の機能を活用し、コスト効率を維持しながら全体的なクエリパフォーマンスを最適化した方法を解説します。

Amazon Redshift Serverless のキューベース QMR できめ細かなリソース制御を実現する
Amazon Redshift Serverless のキューベース Query Monitoring Rules (QMR) を使用して、ワークロードごとに専用キューを作成し、リソース使用量をきめ細かく制御する方法を学びます。クエリの自動中止、ログ記録、制限により、ビジネスクリティカルなクエリを保護し、コストを管理できます。
寄稿:東京証券取引所が挑む膨大な取引データの処理 – AWS 活用で実現した次世代データ分析基盤
本稿は、株式会社日本取引所グループ(以下「JPX」)傘下の株式会社東京証券取引所(以下「東証」)による「膨大な […]
Amazon Q Business と Amazon Bedrock によるSAP データ価値の最大化 – パート 2
このシリーズのパート1では、Amazon Q BusinessとAmazon Bedrockの力を組み合わせて、SAP Early Watch Reportsから実用的なインサイトを得る方法、およびBusiness Data Automationを使用したIntelligent Document ProcessingをSAPシステムの請求書データ処理に使用する方法を検討しました。この投稿では、Amazon Bedrock Knowledge Bases for Structured Dataを使用して、SAPデータに関する質問に自然言語形式で回答する方法を実演します。