Amazon Web Services ブログ
新しい統合 SYS ビューを使用して Amazon Redshift のモニタリングを簡素化
Amazon Redshift は、クラウドにおけるフルマネージド型のペタバイト規模のデータウェアハウスサービスであり、他のどのクラウドデータウェアハウスよりも最大 5 倍優れたコストパフォーマンスを実現し、追加費用なしですぐにパフォーマンスの革新的な向上を実現できます。 何万ものお客様が Amazon Redshift を使用して毎日エクサバイト単位のデータを処理し、分析ワークロードを強化しています。
この記事では、Amazon Redshift SYS モニタリングビューについて説明し、Amazon Redshift のワークロードとリソース使用量のモニタリングを簡素化する方法について説明します。
SYS モニタリングビューの概要
SYS モニタリングビューは Amazon Redshift のシステムビューで、プロビジョニングされたクラスターやサーバーレスワークグループのクエリとワークロードのリソース使用状況をモニタリングするために使用できます。 これらには次の利点があります:
- クエリの状態、パフォーマンス指標、クエリの種類を考慮して、機能の整合性に基づいて分類されています
- パフォーマンスのトラブルシューティングに役立つように、
planning_time、lock_wait_time、remote_read_io、local_read_ioなどの新しいパフォーマンスメトリクスを導入しました - Redshift の オプティマイザで書き直されたクエリの代わりに、ユーザーが送信したクエリをログに記録することで、モニタリングビューの使いやすさが向上しています
- 少ないビューでより多くのトラブルシューティングメトリクスを提供できます
- プロビジョニングされたクラスターでもサーバーレスワークグループでも同じクエリを使用できるため、Amazon Redshift の統合的なモニタリングが可能になります
では、いくつかのSYS モニタリングビューの機能と、それらをモニタリングにどのように使用できるかを見ていきましょう。
さまざまなクエリレベルのモニタリングメトリクスを統合
次の表は、複数のシステムテーブルとビューをクエリすることで得られるさまざまなメトリクスと情報を、一つのSYSモニタリングビューにどのように統合できているかを示しています
| STL/SVL/STV | 得られる情報 | SYS モニタリングビュー | ビューのカラム |
| STL_QUERY | クエリの消費合計時間, クエリ名の短縮系, ユーザーID, トランザクションID, セッションID,クエリのステータス, データベース名 | SYS_QUERY_HISTORY |
user_id query_id query_label transaction_id session_id database_name query_type status result_cache_hit start_time end_time elapsed_time queue_time execution_time error_message returned_rows returned_bytes query_text redshift_version usage_limit compute_type compile_time planning_time lock_wait_time |
| STL_WLM_QUERY | キュー滞在時間, 実行合計時間 | ||
| SVL_QLOG | キャッシュの使用 | ||
| STL_ERROR | エラーコード、エラーメッセージ | ||
| STL_UTILITYTEXT | SELECT以外のSQL | ||
| STL_DDLTEXT | DDLステートメント | ||
| SVL_STATEMENTEXT | 全てのタイプのSQLステートメント | ||
| STL_RETURN | 結果の行数とバイト | ||
| STL_USAGE_CONTROL | クエリによって到達した使用制限 ID のリスト | ||
| STV_WLM_QUERY_STATE | WLMの現在の状態 | ||
| STV_RECENTS | 現在実行中であるか完了しているクエリ | ||
| STV_INFLIGHT | 実行中のクエリ | ||
| SVL_COMPILE | コンパイル |
SYS から STL/SVL/STV へのマッピングに関する追加情報については、SYS モニタリングビューへの移行 を参照してください。
ユーザークエリレベルのロギング
クエリのパフォーマンスを向上させるために、Redshift クエリエンジンはユーザーが送信したクエリを書き換えることができます。 ユーザーが送信したクエリの ID は、書き換えられたクエリの ID とは異なります。 この記事では、ユーザーが送信したクエリを親クエリ、書き直したクエリを子クエリと呼びます。
次の図は、親クエリレベルと子クエリレベルでのロギングを示しています。 親クエリのIDは 1000 で、子クエリのIDは 1001、1002、1003 です。

クエリのライフサイクルのタイミング
SYS_QUERY_HISTORY では、さまざまなクエリライフサイクルフェーズに関連する詳細な時間メトリクスを提供するために、カラムが拡張されています。 すべての時間はマイクロ秒単位で記録されることに注意してください。 次の表は、これらのメトリクスをまとめたものです。
| タイムメトリクス | 詳細 |
| planning_time | クエリを実行する前にクエリが費やした時間。通常、パース、分析、計画、書き換えなどのクエリライフサイクルフェーズが含まれます。 |
| lock_wait_time | 参照されている必要なデータベースオブジェクトのロックの取得にクエリが費やした時間。 |
| queue_time | リソースが実行可能になるまで、クエリがキュー内で待機していた時間。 |
| compile_time | クエリのコンパイルにかかった時間。 |
| execution_time | クエリの実行にかかった時間。 SELECT クエリの場合、これには結果が返ってくるまでの時間も含まれます。 |
| elapsed_time | クエリ実行の開始から終了までの時間。 |
ソリューションの概要
SYS モニタリングビューに慣れるために、以下のシナリオについて説明します:
- ワークロードとクエリのライフサイクルのモニタリング
- データ取り込みモニタリング
- 外部クエリのモニタリング
- クエリのパフォーマンスが遅い場合のトラブルシューティング
前提条件
この投稿の例に従うには、以下を事前に準備する必要があります:
- AWS アカウント
- プロビジョニングされた Redshift クラスター (現在のトラック) または Amazon Redshift Serverless エンドポイント
加えて、この記事で参照されているすべての SQL クエリを Redshift クエリエディタ v2 SQL ノートブックとしてダウンロードしてください。
ワークロードとクエリのライフサイクルのモニタリング
このセクションでは、ワークロードとクエリのライフサイクルをモニタリングする方法について説明します。
実行中のクエリを識別
SYS_QUERY_HISTORY では、実行中のすべてのクエリと実行履歴を一元的に確認できます。 次のクエリの例を参照してください:
次の結果になります。

実行時間の長い上位クエリを特定
次のクエリは、実行に最も時間がかかる上位 100 件のクエリを取得するのに役立ちます。 これらのクエリを分析 (可能であれば最適化) することで、全体的なパフォーマンスを向上させることができます。 これらのメトリクスは、すべての実行されたクエリを累積した統計値です。 時間の値はすべてマイクロ秒単位であることに注意してください。
次の結果になります。

クエリの種類、期間、ステータス別に毎日のクエリ数を収集
次のクエリは、さまざまなタイプのクエリが各日にどのように分布しているかを把握し、ワークロードの変化を評価して追跡するのに役立ちます:

実行中のクエリの実行詳細を収集する
実行中のクエリの実行レベルの詳細を確認するには、SYS_QUERY_DETAIL テーブルをクエリするときにis_active = 't' フィルタを使用できます。 次の例を参照してください:
実行された最新の 100 個の COPY クエリを表示するには、次のコードを使用します:
次の結果になります。

コミットとその取り消しに対するトランザクションレベルの詳細の収集
SYS_TRANSACTION_HISTORY は、コミットされたブロック、ステータス、分離レベル (SERIALIZABLE または SNAPSHOT ISOLATION) などの詳細とともに、コミットされたトランザクションに関するインサイトを提供することにより、トランザクションレベルのロギングを提供します。 また、ロールバックまたは取り消しトランザクションの詳細も記録されます。
次のスクリーンショットは、正常にコミットされたトランザクションについての詳細情報を取得する方法を示しています。


次のスクリーンショットは、ロールバックされたトランザクションについての詳細情報を取得する方法を示しています。


統計情報とバキューム
SYS_ANALYZE_HISTORY モニタリングビューには、分析クエリの最終タイムスタンプ、特定の分析クエリの実行時間、テーブル内の行数、変更された行数などの詳細が表示されます。 次のクエリ例は、すべての永続テーブルに対して実行された最新の分析クエリのリストを提供します:

SYS_VACUUM_HISTORY モニタリングビューでは、バキュームに関するすべての詳細が 1 つのビューに表示されます。 たとえば、次のコードを参照してください:

データ取り込みのモニタリング
このセクションでは、データ取り込みをモニタリングする方法について説明します。
取り込みの概要
SYS_LOAD_HISTORY は、COPY コマンドの統計に関する詳細を提供します。 このビューを使用すると、取り込みワークロードに関するインサイトをまとめることができます。 次のクエリ例は、データ取り込みが行われたテーブルごとに分類された、取り込みの概要を 1 時間ごとに示しています。



取り込みプロセス中のエラーをチェック
次の結果になります。

外部クエリのモニタリング
SYS_EXTERNAL_QUERY_DETAIL は、Amazon Redshift Spectrum やフェデレーテッドクエリを含む外部クエリの実行詳細を提供します。 このビューは、詳細をセグメントレベルで記録し、単一のモニタリングビューで外部クエリのトラブルシューティングとパフォーマンスのモニタリングに役立つインサイトを提供します。 このモニタリングビューが提供する有用なメトリクスとデータポイントは次のとおりです。
- スキャンされた外部ファイル (
scanned_files) の数と、Parquetやテキストファイルなどの外部ファイルのフォーマット (file_format) - スキャンされたデータの行数 (
returned_rows) とバイト数 (returned_bytes) - 外部クエリとテーブルによるパーティショニング (
total_partitionsとqualified_partitions) の使用 - 特定の外部オブジェクトの一覧表示 (
s3list_time) とパーティションスキャン (get_partition_time) にかかった時間の詳細なインサイト - 外部ファイルの場所 (
file_location) と外部テーブル名 (table_name) - Redshift Spectrum 用の Amazon Simple Storage Service (Amazon S3) やフェデレーテッドクエリといった外部ソースのタイプ(
source_type) - サブディレクトリの再帰スキャン (
is_recursive) またはネストされた列データ型へのアクセス (is_nested)
たとえば、次のクエリは、実行された外部クエリ数とスキャンされたデータ数の日次での概要を示しています。
次の結果になります。

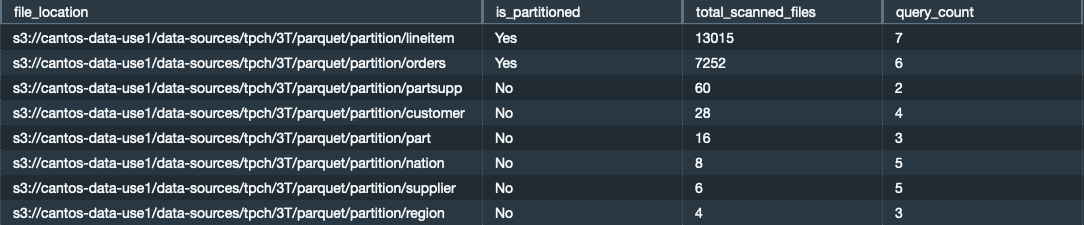
パーティションの使用
大量のデータやファイルをスキャンする外部クエリがパーティション化されているかどうかを確認できます。 パーティションを使用する場合、パーティションキーに基づいて絞り込むことによって、外部クエリがスキャンする必要があるデータの量を制限できます。 次のコードを参照してください。
次の結果になります。
外部クエリでエラーが発生した場合は、SYS_EXTERNAL_QUERY_ERROR を調べてください。SYS_EXTERNAL_QUERY_ERROR には、そのファイル内の file_location、column、および rowid のレベルで詳細が記録されます。
クエリのパフォーマンスが遅い場合のトラブルシューティング
SYS モニタリングビューを使用したクエリレベルのトラブルシューティングを行うための、ステップバイステップのガイドとして、前提条件のセクションでダウンロードした sysview_slow_query_performance_troubleshooting SQL ノートブックがあります。これを参照して、次の質問に対する回答を探してください。
- 比較対象のクエリと、実行したクエリのクエリテキストは似ていますか ?
- クエリは結果キャッシュを使用していますか ?
- クエリのライフサイクル (キューイング、コンパイル、プランニング、ロック待機) のどの部分がクエリの実行時間に最も影響を与えていますか ?
- クエリプランは変更されましたか ?
- クエリは多くのデータブロックを読み込んでいますか ?
- クエリがディスク領域を使っていませんか?もしそうであればそれはローカルストレージですか、リモートストレージですか?
- データ (分散) と時間 (実行時間) の点で、大きく偏っているクエリですか ?
- ジョインまたはネストループで処理される行が増えていますか ?
- 統計情報が古くなっていることを示すアラートはありますか ?
- クエリに関係するテーブルに対して最後に VACUUM と ANALYZE が実行されたのはいつですか ?
クリーンアップ
Redshift のプロビジョニングされたクラスターまたは Redshift サーバーレスワークグループをこの記事のために作成し、ワークロードに対して必要なくなった場合は、それらを削除して追加コストの発生を防ぐことができます。
まとめ
この記事では、Redshift SYS モニタリングビューを使用して、プロビジョニングされたクラスターとサーバーレスワークグループのワークロードをモニタリングする方法について説明しました。 SYSモニタリングビューでは、ワークロードのモニタリングが簡素化され、統一されたビューからさまざまなクエリレベルのモニタリング用のメトリクスにアクセスできます。また、プロビジョニングされたクラスターとサーバーレスワークグループの両方で、同じ SYS モニタリングビュークエリを使用できます。 また、SYS モニタリングビューを使用した主要なモニタリングおよびトラブルシューティングシナリオについても説明しました。
Redshift のワークロードには、新しい SYS モニタリングビューを使い始めることをお勧めします。
著者について
 Urvish Shah は Amazon Redshift のシニアデータベースエンジニアです。 彼はデータベース、データウェアハウス、アナリティクス分野で10年以上働いてきました。 仕事以外では、料理、旅行、娘との時間を楽しんでいます。
Urvish Shah は Amazon Redshift のシニアデータベースエンジニアです。 彼はデータベース、データウェアハウス、アナリティクス分野で10年以上働いてきました。 仕事以外では、料理、旅行、娘との時間を楽しんでいます。
 Ranjan Burman は AWS のアナリティクススペシャリストソリューションアーキテクトです。 Amazon Redshift を専門とし、お客様がスケーラブルなアナリティクスソリューションを構築できるよう支援しています。 彼はさまざまなデータベースおよびデータウェアハウステクノロジーで 16 年以上の経験があります。 クラウドソリューションによる顧客の問題の自動化と解決に情熱を注いでいます。
Ranjan Burman は AWS のアナリティクススペシャリストソリューションアーキテクトです。 Amazon Redshift を専門とし、お客様がスケーラブルなアナリティクスソリューションを構築できるよう支援しています。 彼はさまざまなデータベースおよびデータウェアハウステクノロジーで 16 年以上の経験があります。 クラウドソリューションによる顧客の問題の自動化と解決に情熱を注いでいます。
翻訳はソリューションアーキテクトの小役丸が担当しました。原文はこちらです。