Amazon Web Services ブログ
Amazon SageMaker を使用して画像を分類する
イメージ分類と画像内の物体検出が最近注目されてきていますが、アルゴリズム、データセット、フレームワーク、およびハードウェアの機能の向上が組み合わさった結果です。こうした改良のおかげで技術が一般大衆化し、イメージ分類のためのソリューションが独自で作成できるようになったのです。
画像内の物体検出は、以下の画像が示すように、こうしたアクティビティを実行するアプリケーションの中でも最も重要な機能です。
- 人の進路と物体追跡
- 実際の店舗で、商品の再配置を警告する
- 視覚的な検索 (画像を入力して検索する)
イメージ分類および物体検出に使う技術は、深層学習 (DL) に基づいているのが現状です。DL は、多層のニューラルネットワーク (NN) あるいはディープニューラルネットワークを処理するためのアルゴリズムに焦点を当てた機械学習 (ML) のサブ領域です。一方、ML は人工知能 (AI) のサブ領域で、コンピューターサイエンスの分野です。

誰でもこれらの技術にアクセスできますが、実際のビジネスプロセスをサポートするエンドツーエンドのソリューションとして、これらの要素をつなぎ合わせて使うことはまだ難しい状況です。Amazon Rekognition は、非常に正確な顔分析と画像や動画の顔認識ができるシンプルな API を装備しており、すぐに利用できるサービスなので、最初に選ぶならよい選択肢かもしれません。さらに、顔を検出、分析、比較することができるため、多岐にわたるユーザー検証、人数計算、公共の安全といったユースケースにも利用できます。Amazon Rekognition のドキュメントを読めば、シンプルな API 呼び出しでこれらの機能全てをアプリケーションに簡単に追加できることが分かります。
ただし、ビジネス上でカスタムでのイメージ分類が必要な場合は、機械学習モデルを作成するためのパイプライン全体をサポートするプラットフォームが必要です。Amazon SageMaker は、そのためのものです。Amazon SageMaker は、ML モデル開発の全ての手順、つまりデータ検索と構築、トレーニング、および ML モデルのデプロイをサポートする、完全マネージド型のサービスです。Amazon SageMaker を使用すると、どんなビルトインアルゴリズムでも選択でき使用することができるので、市場投入までの時間と開発コストを削減できます。詳細は、「Amazon SageMaker でビルトインアルゴリズムを使用する」をご参照ください。
カスタムの画像識別子を作成する
このブログ記事は、服装品やアクセサリーを識別するための画像識別子の作成を目標としています。これらのアイテムの画像がいくつかあり、それらを見て、何の物体が各画像に含まれているかを言う (予測する) モデルが必要だとしましょう。Amazon SageMaker はすでにビルトインのイメージ分類アルゴリズムを装備しています。これで、データセット (画像コレクションと各オブジェクトのそれぞれのラベル) を準備し、モデルのトレーニングを開始するだけです。
公開データセットを使用します。これは Fashion-MNIST と呼ばれる ML アルゴリズムをベンチマークするための新しい画像データセットです。データセットは、6 万例のトレーニングセットと 1 万例のテストセットで構成されています。各例は、ラベルまたはクラスに関連付けられた、28×28 のグレースケール画像です。データセットには、T シャツまたはトップス、ズボン、プルオーバー、ドレス、コート、サンダル、シャツ、スニーカー、バッグ、アンクルブーツの 10 種類のクラスがあります。次の画像は、データセットのサンプルを示しています。

データセットと Amazon SageMaker は、ファッション予測モデルをトレーニングするのに役立ちます。しかし、計算に必要なリソースはどのくらいですか ? また、モデルを本番環境に導入するにはどれくらいの時間がかかるでしょうか?
P2.xlarge のようなインスタンスには、12 GB の VRAM を搭載した NVIDIA Tesla K80 GPU が付属しています。GPU は、トレーニングアルゴリズムが足し算や乗算のような行列演算を実行する DL に最適です。GPU は並列タスクに特化した複数のコアがあるため、GPU は CPU よりもはるかに高速でこれらの処理を実行できます。Resnet152 をトレーニングした Tesla K80 を使えば (これについては下記でご説明します)、以下のパフォーマンスグラフに示すように、毎秒約 20 枚の画像処理が可能です。
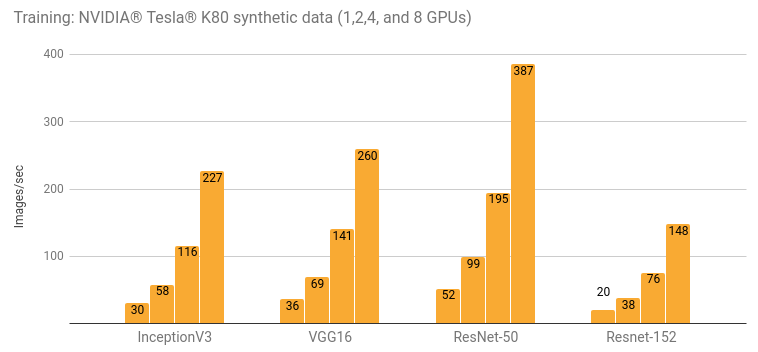
モデルを 100 万枚の画像のデータセットでトレーニングし、目標レベルの 91% の精度に達成するには、100 エポック (またはトレーニングアルゴリズムによるデータセットに 1 回のパス) が必要であるとします。この設定では、トレーニングを完了するのに、1 エポックあたり約 14 時間、あるいは合計で 58 日かかるでしょう。
これより速くできるでしょうか?もちろん。どうやって?
- NVIDIA Tesla V100 のようなより性能の良い GPU を使用して、インスタンスタイプを P2 から P2 に変更します。Tesla V100 は K80 より 14 倍高速です。このアップグレードにより、トレーニングの時間が大幅に短縮できます。
- 複数の GPU を装備する P2 または P3 インスタンスを使用します。例えば、16xlarge インスタンスには 8 つの V100 GPU が備わっています。トレーニング作業負荷を 8 つの GPU に分散することで、市場投入までの時間を比例して減らすことができます。
- 複数のトレーニングインスタンスを起動します。モデルをトレーニングするための巨大なデータセットがあり、8 つの GPU を備えたインスタンスで必要以上に時間がかかっているとします。tensorflow.TensorFlow クラスの train_instance_count パラメータを設定することによって、2 つ以上のインスタンスでトレーニングジョブを実行するよう Amazon SageMaker に指示できます。負荷を複数の GPU に分散しながら、インスタンス内でジョブを並列化できるだけでなく、複数のインスタンスにまたがる GPU のファームを使用することも可能です。詳細は、「ステップ 2: TensorFlow カスタムコードを使用して Amazon SageMaker でモデルをトレーニングする」をご参照ください。
- 転移学習と呼ばれる技術を適用する転移学習は、すでに数時間トレーニングを行ったモデルを使用します。モデルをカスタマイズして、ニーズにあわせて再トレーニングすることができます。
ご覧のように、Amazon SageMaker は、毎日の ML パイプラインシナリオをサポートする、柔軟な環境を提供できるような設定が可能です。
転移学習を理解する
先に進む前に、Resnet を見てみましょう。これは、イメージ分類において高い精度を得られる NN トポロジーです。2015 年に ImageNet Large Scale Visual Recognition Challenge で最高の物体識別子に選ばれ、コンピュータビジョン問題に最もよく使用される NN の 1 つです。
Resnet のようなトポロジーは、畳み込みニューラルネットワーク (CNN) と呼ばれ、ネットワークの入力層が入力画像に対して畳み込み演算を実行します。畳み込みは、動物の視覚野をエミュレートする数学的関数です。CNN には、画像フィルタを学習する畳み込みレイヤーがいくつかあります。これらのフィルタは、エッジ、パーツ、ボディなどの入力画像から特徴を抽出します。これらの特徴は、隠しレイヤーまたは内部レイヤーから出力レイヤーにルーティングされます。イメージ分類において、出力レイヤーはカテゴリごとに 1 つの出力を持ちます。
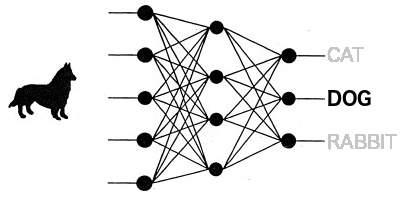
以下の画像に示すように、犬を分類できるようトレーニングしたニューラルネットワークを考えてみましょう。畳み込みレイヤーは、犬の画像からいくつかの特徴を抽出し、残りのレイヤーは、これらの特徴を高い修正度で最後のレイヤーの正しい出力にルーティングします。
転移学習は、新しいモデルのトレーニングに必要な時間を短縮するために利用できる技術です。モデルを最初からトレーニングする代わりに、事前にトレーニングした修正済みモデルを使用して、データセット内でトレーニングを継続することができます。それゆえ、転移学習と呼ばれているのです。つまり、1 つの NN が学習した知識が、別の NN に転送されていくのです。
例えば、車種 / モデル / 年を分類できるモデルが必要で、事前にトレーニングしてあるモデルがすでにある場合、この新しい問題を解決する新しいモデルを作成するには、モデルを少し変更して、独自のデータセットで再トレーニングすることは合理的と言えるでしょう。
イメージ分類のための Amazon SageMaker ビルトインアルゴリズムは、すでに転移学習用に実装されています。与えられたパラメーターを真に設定するだけで、モデルにこの技術を適用できます。
イメージ分類のための、エンドツーエンドソリューションを作成する
これまでに見てきた内容で、ビジネス上のどんな問題を解決できそうか分かってきたと思いますが、では実際にどうすればいいのでしょうか ?
実践的な Jupyter ノートブックをダウンロードし、実験の詳細を見てみましょう。ここでは、ファッション用画像識別子のための ML 開発パイプラインの中の、最も重要な部分だけを見ていきます。まず最初に、データセットを準備します。
データセットを準備する
Amazon SageMaker のビルトインイメージ分類アルゴリズムでは、データセットを RecordIO でフォーマットする必要があります。RecordIO は、画像を NN にストリームとして入力するのに効率的なファイル形式です。Fashion MNIST は IDX でフォーマットされているため、未加工画像をファイルシステムに抽出する必要があります。その後、未加工画像を RecordIO に変換し、最後に Amazon Simple Storage Service (Amazon S3) にアップロードします。
データセットの準備:
- データセットをダウンロードします。
- IDX から 28×28 ピクセルの未加工の JPEG グレースケール画像に画像を展開します。
- カテゴリごとに 1 つずつ、10 の異なるディレクトリに画像を整理します。
- RecordIO tool (im2rec) を使用して、2 つの .lst ファイルを作成します。1 つは、データセットのトレーニング部分用ファイルです (70%)。もう 1 つはテスト用です (30%)。
- .lst ファイルから両方の .rec ファイルを生成します。
- 両方の .rec ファイルを Amazon S3 バケットにコピーします。
データセットを IDX から未加工の JPEG ファイルに変換するには、IDX ファイルを samples というディレクトリに保存し、python-mnist と呼ばれる Python パッケージを使用する必要があります。
次に Amazon S3 バケットに .rec ファイルをアップロードします。
環境をセットアップします。
Amazon SageMaker の使用に慣れていない場合は、AWS エバンジェリスト、Randall Hunt のこちらのブログ記事を参考にしてください。上記のブログ記事では、Jupyter ノートブックインスタンスをセットアップする方法をしっかり学べます。Jupyter ノートブックインスタンスは、ML モデルを作成するための「操縦席」なのです。
Jupyter ノートブックインスタンスに付随するロールが、Amazon S3 にアクセスする権限を持っていることを確認してください。そのインスタンスが、選択した Amazon S3 バケットに読み書きします。
今度は、トレーニング環境のハイパーパラメータを選択します。これらのパラメータは、モデルのトレーニング方法と、その結果としてトレーニングしたモデルの動作を決定します。
- num_layers: ネットワークの隠れ / 内部レイヤーの数。小さい画像が [20, 32, 44, 56, 11] のような小さい数字を選んだ場合。
- image_shape: 画像の幅と高さピクセルあたりのチャンネル数。ここで、3, 28, 28 では、3 はカラーチャンネル (RGB) の数で、28, 28 は画像の幅と高さのピクセルを表しています。
- num_classes: モデルが分類可能なクラスの数。
- mini_batch_size: 各バッチが含む画像の数。GPU が持つ VRAM の大きさに応じて、このサイズを増減することができます。サイズが大きいとメモリ不足の例外が発生し、トレーニングが失敗する可能性があります。
- epochs: トレーニングアルゴリズムがデータセット全体を何回通過するか。選択したアルゴリズムに応じて、エポックはそれぞれ、各エポックのデータセットのランダムサンプルのみを取得します。
- learning_rate: トレーニングアルゴリズムがモデルを最適化しようとするペース。学習率が低くなると、より正確な精度が得られ、モデルのトレーニングには時間がかかります。学習率が高くなると、モデルの精度が向上しません。この属性のちょうどよいバランスを見つける必要があります。
- use_pretrained_model: 1 に設定すると転移学習が有効になります。Amazon SageMaker は、ImageNet 11K カテゴリを持つ事前にトレーニングした Resnet を取得し、シナリオに合わせてカスタマイズできます。
これらのハイパーパラメータを全て設定したら、インスタンス、好ましくは強力な GPU を備えた P2 または P3 インスタンスを選択し、モデルのトレーニングを開始します。
モデルをトレーニングする
Amazon SageMaker は、Docker コンテナに基づいたプラットフォームです。ビルトインアルゴリズムはどれも、アルゴリズム自体とともに、ライブラリ、フレームワーク、バイナリの全てを準備してある Docker イメージです。このアルゴリズムは、プラットフォームを可能な限り適応性のあるものにします。好きな技術を使って、独自の ML アルゴリズムを設計したいなら、アルゴリズムで Docker イメージを作成し、Amazon SageMaker から呼び出すだけです。
この場合、必要なアルゴリズムがすでに含まれている画像を使用します。この画像は、モデルをトレーニングし、トレーニングしたモデルを本番でエンドポイントとして公開するジョブを作成するために使用します。Amazon SageMaker 環境が実行しているリージョンによっては、異なるレジストリを選択する必要があります。
- us-west-2:dkr.ecr.us-west-2.amazonaws.com/image-classification:latest
- us-east-1:dkr.ecr.us-east-1.amazonaws.com/image-classification:latest
- us-east-2:dkr.ecr.us-east-2.amazonaws.com/image-classification:latest
- eu-west-1:dkr.ecr.eu-west-1.amazonaws.com/image-classification:latest
次に、ジョブ記述を作成する必要があります。ジョブ記述は、SageMaker がジョブを開始できるように、Amazon SageMaker へ送信するよう設定した全てのパラメータとハイパーパラメータを含んだ構造を表しています。このプロセスの結果は、選択した Amazon S3 バケットに保存されるトレーニング済みモデルです。
次の図に示すように、トレーニングプロセスの各ステップを CloudWatch Logs and Metrics でモニタリングできます。Amazon SageMaker コンソールで実行中のジョブをクリックし、Monitor セッションに移動します。どのくらいの GPU メモリが使われているか、GPU または CPU 使用率がどれくらいであるかを確認するには、Amazon CloudWatch メトリクスに行きます。
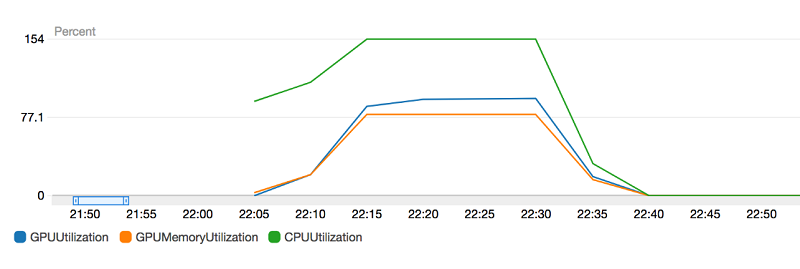
GPU メモリ使用量は、約 77% です。良好な GPU メモリ使用率は 85% から 93% の間であるため、バッチサイズを増やしてトレーニングセッションをスピードアップすることができます。
Amazon CloudWatch Logs には、トレーニングアルゴリズムの全ての出力が表示されます。モデルが収束しつつあるか、すでに処理されているバッチ / エポックがいくつあるか、などが分かります。

上の画像では、「検証精度」という情報を見ることができます。これは、トレーニングに関する最も重要な情報の 1 つです。トレーニングの精度が検証精度と大きく異なる場合、恐らくモデルは過学習しており、よい状態ではありません。「検証精度」が高いことは、モデルが良好な形式に収束しており、トレーニングデータセットに含まれていない新しい画像に対しても一般化できることを示します。
モデルをテストし、デプロイする
ご参考までに、40 のエポックの 1 つだけの GPU k80 を持つ 1 つの p2 インスタンスにある FashionMNIST では、画像識別子をトレーニングするのに約 5 時間かかりました。この特定のケースでは、CloudWatch Logs で確認できるように、モデルは 91.10% の精度に達しました。ただし、トレーニングアルゴリズムでは、エポックごとにデータセット全体を使用するのではなく、バッチごとにデータセットの一部を無作為に選択することが重要です。最終的なパフォーマンスは改善しますが、1 つのジョブから別のジョブへのトレーニング結果にはわずかなばらつきがあります。つまり、同じトレーニングプロセスを複数回実行した場合、おおよそのエポックで、そのレベルの精度に達することができるということです。
ビジネスケースによっては、それほど正確なモデルが必要ない場合もあります。ある特定のケースだと、80% で十分であるとしましょう。つまり、トレーニングの時間を減らすことができ、結果的にコスト削減につながるのです。一方、高精度のモデルが必要な場合は、モデルを収束させるために、例えばより大きなデータセットやさらなるエポックが必要かもしれず、トレーニングコストは上昇します。ご覧のとおり、このプロセスにはトレードオフがあるのです。
それでは、そのモデルを本番環境にデプロイしてみましょう。Jupyter ノートブックにあるように、3 つの手順で行います。
- Amazon SageMaker モデルカタログで使用できるモデルのジョブ出力を変換します。
- エンドポイント構成を作成します。このステップでは、予測をサポートするインスタンスを決定します。まず GPU を搭載したマシンでモデルをトレーニングし、それから CPU のみのマシンにデプロイすることが可能です。それを実践してみましょう。CPU のみのインスタンスにモデルをデプロイすると、コストを削減できます。
- 前に定義したエンドポイント構成を使用して、モデルをデプロイします。Amazon SageMaker がインスタンスを作成し、選択したアルゴリズムでコンテナをデプロイします。そのコンテナで、トレーニング済みモデルがホストされます。その後、API を使用してそのエンドポイントにリクエストを送信できます。
デプロイしたモデルの API 呼び出しの例を、次に示します。
このコードをいくつかのサンプル画像で実行すると、次のような結果が得られます。

Fashion-MNIST は、黒の背景色を持つ 28×28 のグレースケール画像で構成されています。実際のビジネスケースのシナリオでは、実物の服を分類できるようトレーニングしたモデルを取得するには、より大きなカラー画像のデータセットが必要かもしれません。上記の画像は Fashion-MNIST のものではありません。そのため、元のデータセットの制限のために、元のデータセットの画像とできるだけ類似するように前処理しています。
エンドポイントまたはデプロイしたモデルも、CloudWatch によってデフォルトでモニタリングされます。Amazon SageMaker コンソールでご希望のエンドポイントをクリックすると、次の情報が表示されます。
- ランタイムログ (CloudWatch Logs)
- 呼び出しメトリック (呼び出し数、モデル遅延時間、4XX および 5XX エラーなど)
- インスタンスメトリック (CPU / メモリ使用量、および GPU / GPU メモリ使用量)
エンドポイントは、デフォルトで保護されています。ユーザーが AWS Identity and Access Management (IAM) ポリシーの形式で正しい権限を受け取るまで、誰もそれを呼び出すことはできません。ユーザーがエンドポイントを起動できるようにするには、次のようなポリシーを構成する必要があります。
エンドポイントをアプリケーションユーザーに公開する別の方法は、API Gateway を使用して API に含めることです。API Gateway に、すでにアプリケーションに定義してある全てのセキュリティコントロールを委任し、同じ方法で環境を管理することができます。
まとめ
Amazon SageMaker は、イメージ分類に関するニーズに応える強力なソリューションを生み出すことが可能なのです。Amazon SageMaker は、ML パイプラインをサポートするための柔軟で弾力あるインフラストラクチャを提供できるため、製作プロセスとビジネス問題に集中することが可能となります。
Jupyter ノートブックを手に入れて、新しい画像識別子を使って、さらに良くなったアプリケーションとユーザー体験を感じてみてください。
今回のブログ投稿者について
 Samir Araújo は、AWS の AI ソリューションアーキテクトです。AWS プラットフォームを使用して、お客様がビジネス上の課題を解決するための AI ソリューションを作成しています。コンピュータビジョン、自然言語処理、推論などに関連する AI プロジェクトに取り組んでいます。自由な時間には、ハードウェアやプログラミングのプロジェクトで遊ぶのが好きで、特にロボット工学に興味があります。
Samir Araújo は、AWS の AI ソリューションアーキテクトです。AWS プラットフォームを使用して、お客様がビジネス上の課題を解決するための AI ソリューションを作成しています。コンピュータビジョン、自然言語処理、推論などに関連する AI プロジェクトに取り組んでいます。自由な時間には、ハードウェアやプログラミングのプロジェクトで遊ぶのが好きで、特にロボット工学に興味があります。