Amazon Web Services ブログ
Amazon Forecastを使用するために時系列データをクラスタリングする
この記事は、“Cluster time series data for use with Amazon Forecast” を翻訳したものです。
ビッグデータの時代には、企業は大量な時系列データに直面しています。時系列データは大量なだけでなく、微妙な違いもあります。DeepAR+ や CNN-QR などの Amazon Forecast 深層学習アルゴリズムは、この大量の時系列データの共通傾向とパターンをキャプチャし、可視化できます。これらのアルゴリズムは、従来の予測方法より優れたパフォーマンスで予測を生成できます。
場合によっては、予測する時系列データセットと同様な特徴を持つデータのサブセットでモデルをトレーニングすることで、 Amazon Forecast の精度をさらに向上できる場合があります。たとえば、小売チェーンの場合を考えてみましょう。パンや牛乳などの特定の品目の需要は非常に規則的であり、予測が容易である可能性があります。対照的に、断続的な需要がある電球などの品目の予測は、正しく予測するのが難しい場合があります。小売業者は、地元スポーツチームのグッズのような、ホームゲームまでは需要が急速に拡大するものの、すぐに減少してしまう商品を販売することもあります。時系列データセットを前処理して、これらのアイテムを異なるグループに分けることで、 Amazon Forecast モデルはさまざまな需要パターンに対して、より精度の高いパターンを学習できるようになります。
このブログでは、クラスタリングと呼ばれる前処理手法の 1 つと、それが予測の改善にどのように役立つかについて学びます。
クラスタリングの概要
クラスタリングは教師なし機械学習の手法であり、類似性を測定すること(通常は距離メトリック)に基づいてアイテムをグループ化します。クラスタリングアルゴリズムは、グループ内のアイテムが互いに近接し、他のグループ内のアイテムから十分に離れるように、アイテムをグループに分割します。時系列クラスタリングのコンテキストでは、動的時間伸縮法 (DTW) は、時間次元に沿った非線形ワープパスの最適なマッチング結果に基づいて、その 2 つの時系列の類似性を測定するために、一般的に使用される距離メトリックです。
このブログ記事では、同種の時系列データを利用して Amazon Forecast モデルをトレーニングする時、前処理として、 K-means アルゴリズムを使用して、ターゲット時系列 (TTS) データの DTW を距離メトリックとして、クラスターを生成する方法について説明します。このブログ記事の内容は、実験結果をまとめたものになります。データの構成と、変動性を最もよく捉えるクラスタリングの設定に応じて、実測結果が異なる場合があります。このデモでは、num_clusters=3を設定して、時系列データセットから、「規則的」(時間の経過とともに非常に規則的な目標値の分布)、「断続的」(比較的一貫した目標値を持つ周波数の変動が大きい時系列のコレクションに対応する)、および「不規則的」(目標値と頻度の両方で変動が広い)のサブセットを見つけることを意図しています。
このブログ記事には 2 つのデモノートブックが添付されています。最初のノートブックは、オプションとしてオープンソースの UCI Online Retail II データセットをクリーニングする処理を行います。主要なノートブックは、時系列クラスタリングに関するものです。このデータセットは、 2 年間の英国での贈り物の企業間オンライン販売に関連する時系列データです。 Python のtslearnパッケージのtslearn.clusteringモジュールを活用して、 DTW Barycenter Averaging (DBA) K-means を使用して、この時系列データのクラスタリングを行います。
次のセクションでは、 GitHub Clustering Preprocessing ノートブックのリポジトリにあるノートブックと設定を詳しく説明します。この実験は、Jupyter ベースの Python ノートブックを使用してセットアップされますので、 Python と Jupyter/IPython の初心者レベルの知識が必要です。
(オプショナル) データの準備
データクリーニングと準備に関するオプションのノートブックは、 UCI Online Retail II データセットを処理し、この実験に関連する列( ‘stockCode’、 ‘invoiceDate’、および ‘Quantity’ )に対して一連のデータクリーニング処理を実行します。これらの列は、 Amazon Forecast のスキーマ ( ‘item_id’、 ‘timestamp’、 ‘target_value’ ) に対応します。時系列データをリサンプリングして、日次データに変換し、欠損値をゼロで埋めます。さらに、異常な商品コードのデータを含むいくつかの項目を削除し、クラスタリングに必要な形式に合わせてデータを変換します。
DBA K-means クラスタリング
DTW 距離の簡単な紹介から、時系列クラスタリングについての議論を始めましょう。 DTW アルゴリズムは、2つのシーケンス上の時点のペアを一致させるコストを最小限に抑え、時間次元に沿った非線形「ワープ(歪んだ)」パスを見つけることによって、 2 つの時系列間の距離を求めます。
デモのために、データセット内の時系列のペアについて次のプロットが生成されます。左側のプロットは第1時系列と第 5 時系列間の DTW パス、右側は第 6 時系列と第 10 時系列間の DTW パスを表しています。

このデモに示したように、時系列のペア間は、ワープされた (歪んだ) 時系列パスに沿って一致させます(たとえば、左上の時系列の 0 番目のインスタンスは、異なる時系列のペアに対して、厳密には t0 から t0、t1 から t1 … ではなく、左下の時系列の複数の時系列と一致します)。
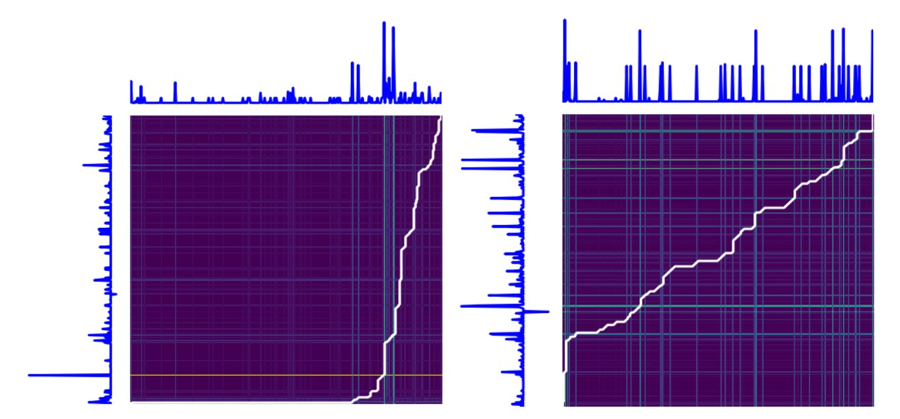
この最適経路は、さまざまな制約の下で適切なメトリックを最小化して、DTW アルゴリズムによって検出されます。次のプロットは、前の例の 2 つ時系列ペアを一致させるコスト行列に基づいて、 DTW アルゴリズムが最適経路 (白で表示) を選択する方法を示しています。左のプロットでは、 Y 軸に沿った時系列の t0 が、 X 軸に沿った時系列の多くの時点と一致していることがわかります。これは、前のプロットからの歪んだパスの正確なレプリカです。
時系列クラスタリングノートブックでは、 Barycenter Averaging を使用して DTW 距離に基づく K-means クラスタリングアルゴリズムをトレーニングします。まず、データフレームを tslearn time_series_dataset オブジェクトに変換し、時系列をゼロ平均と単位分散に正規化します。次に、以下のクラスタリング設定を適用して、tslearn.clusteringモジュールのTimeSeriesKMeansメソッドでトレーニングします。
n_jobs=-1は、トレーニングがマシン上で利用可能なすべてのコアを使用するようにします。12 コア(CPU)を搭載したマシンでは、クラスタリングモデルのトレーニングには約 30 分かかりました。実測結果は、マシンの構成によって異なる場合があります。距離メトリックに代わる他の方法として”softdtw“があります。これは、より高い計算コストで分離を改善することがあります。
次の図は、DBA K-means アルゴリズムによって検出されたさまざまなクラスターの構成と、対応する時系列のカウント(クラスタリングされる前のデータセットの時系列のカウント)を可視化したものです。また、この表現は、コンポーネントの時系列信号が重なり合ってプロットされるので、異なるクラスターの一貫性(「断続的」、「規則的」、または「不規則的」)をよく理解できます。

また、データ範囲が制限されていることにも気付くかもしれません。これは、トレーニング前の正規化ステップに、振幅に影響されないようにデータを変換したためです。詳しく調べてみると、個々のクラスター構成は均質であり、クラスターごとの時系列の分布はバランスが取れていることがわかります(おおむね 4 : 5 : 2 の割合)。
クラスターが特定されたら、データセット内の異なる時系列のラベルに基づいて TTS をサブセットに分割します。また、Amazon Forecast サービス API のスキーマと一致するように、データを列指向の時間からインデックス化された時間に再フォーマットします。これで、これらの TTS ファイルを使用して Amazon Forecast モデルをトレーニングする準備ができました。
結果
次のプロットでは、ベースライン(すべてのデータをまとめたもの)と、データセットを分割して各クラスターの AutoML モデルを別々にトレーニングするクラスター化のアプローチ(num_clusters=3)との比較を示します。次のプロットは、いくつかの代表的なサンプルを対象としており、これらのモデルから得られた p50 予測を、モデルをトレーニングする時使用しなかった 1 週間分のテストデータセットと比較します。

このプロットにあるように、クラスタリングされたデータの予測を表す緑色の線は、全データをクラスタリングせずまとめてトレーニングしたベースライン (オレンジ色) モデルよりも、トレーニングに使用しなかったテストデータセット (青色) に、わずかに良く追従しているように見えます。
クラスター数が非常に多いと過剰適合のリスクが存在するため、num_clusters=3を設定することをお勧めします。この設定は、規則的、断続的、または不規則的な需要が混在する通常の現実世界のデータセットの実験結果から見ると、うまく機能することがわかりました。データセットにさらに多様性が存在することが確認された場合、経験に基づいて、このパラメータをより適切な値にチューニングできます。また、データセットを分割しすぎると、大量データを前提とした深層学習モデルが影響される可能性があるため、時系列が 1,000 未満のデータセットに対して、クラスタリングの手法はお勧めしません。
結論
クラスタリングは、時系列データの前処理パイプラインに追加する価値がある可能性があります。クラスタリングの前処理が完了したら、 TTS データの異なるクラスタに対して複数の Amazon Forecast モデルをトレーニングするか、クラスタリング設定を全体の TTS のアイテムメタデータとして含めるかを選択できます。Amazon Forecast デベロッパーガイドは、データセットのインポート、予測のトレーニング、予測の生成の作業に役立ちます。アイテムメタデータ (IM) と関連時系列 (RTS) データがある場合、以前と同様に Amazon Forecast トレーニングにそれらを含めることもできます。一度お試しいただけると幸甚です!
参考文献
- Dua, D. と Graff, C. (2019). UCI Machine Learning Repository [http://archive.ics.uci.edu/ml]. Irvine, CA: カリフォニア大学 情報とコンピュータサイエンス学部
- UCI Online Retail II データセットレポジトリのリンク: https://archive.ics.uci.edu/ml/datasets/Online+Retail+II
- UCI Online Retail II データセットのリンク: https://archive.ics.uci.edu/ml/machine-learning-databases/00502/online_retail_II.xlsx
- tslearn の GitHub レポジトリのリンク: https://github.com/tslearn-team/tslearn
著者について
 Vivek M Agrawal は Amazon Forecast チームのデータサイエンティストです。長年にわたり、彼は機械学習に対する情熱を持って、お客様がクラウドで最先端の AI/ML ソリューションを構築するのを支援してきました。自由時間には、さまざまな料理、ドキュメンタリー、ボードゲームを楽しんでいます。
Vivek M Agrawal は Amazon Forecast チームのデータサイエンティストです。長年にわたり、彼は機械学習に対する情熱を持って、お客様がクラウドで最先端の AI/ML ソリューションを構築するのを支援してきました。自由時間には、さまざまな料理、ドキュメンタリー、ボードゲームを楽しんでいます。
翻訳は Solution Architect の Ming Yang が担当しました。原文はこちらです。