Amazon Web Services ブログ
Amazon Forecastにおける継続的な予測子の精度のモニタリング
このブログは、Dan SinnreichとAdarsh Singh、Shannon Killingsworthによって書かれたContinuously monitor predictor accuracy with Amazon Forecastを翻訳したものです。
Amazon Forecastは、予測子の精度の時間の経過による変化を自動的にモニタリングできるようになりました。新しいデータが提供されると、Forecastは自動的に新しいデータセットで予測精度のメトリクスを計算し、使い続けるか、再トレーニングするか、新しい予測子を作成するかを決定するための情報を提供します。
予測子の品質をモニタリングし、時間の経過に伴う精度の劣化を特定することは、ビジネス目標を達成する上で重要です。しかし、予測精度メトリクスを継続的にモニターするために必要なプロセスは、セットアップに時間がかかり、管理も困難です。さらに、トレンドを理解し、予測子の維持、再トレーニング、再作成に関する決定を行うために、測定基準を保存し、チャート化する必要があります。これらのプロセスは、開発およびメンテナンスの負担が大きく、データサイエンスおよびアナリストのチームにとって、運用上の大きなストレスとなります。また、このような時間のかかるプロセスを行いたくないお客様(多くは必要ないときでも予測子を再トレーニングすることを好む)にとっては、時間と計算の無駄となります。
今回、Forecastは新しいデータがインポートされるたびに予測子の精度を自動的に追跡するようになりました。予測子の初期品質指標からの乖離を定量化し、傾向を可視化することでモデル品質を体系的に評価し、新しいデータが入ってきたときにモデルの維持、再トレーニング、再構築についてより多くの情報に基づいた決定を行うことができるようになりました。予測子のモニタリングは、新しい予測子の開始時に有効にするか、既存のモデルに対してオンにすることができます。この機能は、AWSマネジメントコンソールでワンクリックするか、Forecast APIを使用して有効にすることができます。
時間の経過による予測精度の変化
予測子は、ある時点での学習データセットを使って作成された機械学習モデルです。予測子が作成された後、数日、数週間、数ヶ月先に渡って継続的に使用され、実際のトランザクションを通じて生成された新しいデータを用いて時系列予測を生成します。新しいデータがインポートされると、予測子は提供された最新のデータに基づいて新しい予測データポイントを生成します。
予測子が最初に作成されるとき、Forecastは予測子の精度を定量化するために、重み付き分位損失(wQL)、平均絶対パーセント誤差(MAPE)、二乗平均平方根誤差(RMSE)などの精度メトリクスを生成します。これらの精度メトリクスは、予測子を本番稼動させるかどうかを決定するために使用されます。しかし、予測子のパフォーマンスは時間の経過とともに変動します。経済環境の変化や消費者行動の変化などの外的要因によって、予測子の基礎となる要因が変化することがあります。その他の要因としては、新しい製品、アイテム、サービスの登場、金融・経済環境の変化、データ分布の変化などがあります。
例えば、ある商品のある色が流行したときに学習させた予測子を考えてみましょう。数カ月後、新しい色が現れたり、人気が出たりして値の分布が変化することがあリます。あるいはビジネス環境に変化が起こり、長年の購買パターン(例えば、利益率の高い製品から低い製品へ)が変更されるかもしれません。これらのことを考慮すると、精度の高い予測を維持するために、予測子を再トレーニングするか、新しい予測子を作成する必要があるかもしれません。
自動化された予測子モニタリング
予測子モニタリングは、新しい時系列データが利用可能になり新しい予測を作成するために使用されると、予測子のパフォーマンスを自動的に分析するように設計されています。このモニタリングは継続的なモデルのパフォーマンス情報を提供し、このプロセスを自分でセットアップする必要がないので時間を節約できます。
予測子モニタリングが有効になっていると、新しいデータをインポートし、新しい予測を作成するたびに、パフォーマンス統計が自動的に更新されます。今までは、これらのパフォーマンス統計は予測子が最初にトレーニングされた時のみ利用可能でした。今回これらの統計は新しいデータを使って継続的に作成され、予測子のパフォーマンスを測定するためにアクティブにモニターすることができるようになりました。
これにより、新しい予測子をいつトレーニングするか、または再トレーニングするかを決定するために、予測子のパフォーマンス統計を使用することができます。例えば、平均的なwQLメトリックが最初のベースライン値から逸脱すると、新しい予測子を再トレーニングするかどうかを決定することができます。予測子の再トレーニングまたは新しい予測子の作成を決定すると、より正確な予測子を使用して新しい予測データポイントの生成を開始することができます。
次のグラフは、予測子のモニタリングの2つの例です。最初のグラフでは、平均wQLメトリックがベースライン(予測子がトレーニングされたときの初期値)から減少しており、予測精度が時間とともに上昇していることを表しています。このチャートでは、平均wQLが数日の間に0.3から0.15に低下しており、予測精度が上昇していることを意味しています。この場合、予測子は最初にトレーニングされたときよりも正確な予測を出しているので、再トレーニングする必要はありません。

次の図では、その逆で、平均のWQLが増加しており、時間の経過とともに精度が低下していることを示しています。この場合、新しいデータで予測子を再トレーニングするか、再構築することを検討する必要があります。

Forecastでは、現在の予測子を再トレーニングするか、ゼロから作り直すかを選択することができます。再トレーニングはワンクリックで実行でき、より最新のデータ、アルゴリズムの更新や改良を組み入れることができます。予測子を再構築することで、新しい入力(予測頻度、予測期間、新しいディメンションなど)を提供し、新しい予測子を作成することができます。
予測子モニタリングの有効化
予測子モニタリングは新しい予測子を作成するときに有効にするか、既存の予測子に対してオンにすることができます。このセクションでは、Forecastコンソールを使用してこれらの手順を実行する方法を示しています。また、APIを使用して予測子モニタリングを有効にし、予測子モニタリング結果を生成する一連のステップを説明するJupyterノートブック(https://github.com/aws-samples/amazon-forecast-samples/tree/main/notebooks/advanced/Predictor_Monitoring)があります。
この例では、predictor monitoring notebook (https://github.com/aws-samples/amazon-forecast-samples/blob/main/notebooks/advanced/Predictor_Monitoring/Predictor_Monitoring_Introduction.ipynb)から利用可能なタイムスライス・サンプル・データセットを使用します。この例では、タイムスタンプ、ロケーションID、ターゲット値(ロケーションIDでタイムスタンプ中に乗客を乗せたタクシーの数)を含むニューヨーク市のタクシーの10万行のデータセットを使用します。
以下のステップを実行します。
- Forecastコンソールで、ナビゲーションペインからView dataset groupsを選択します。
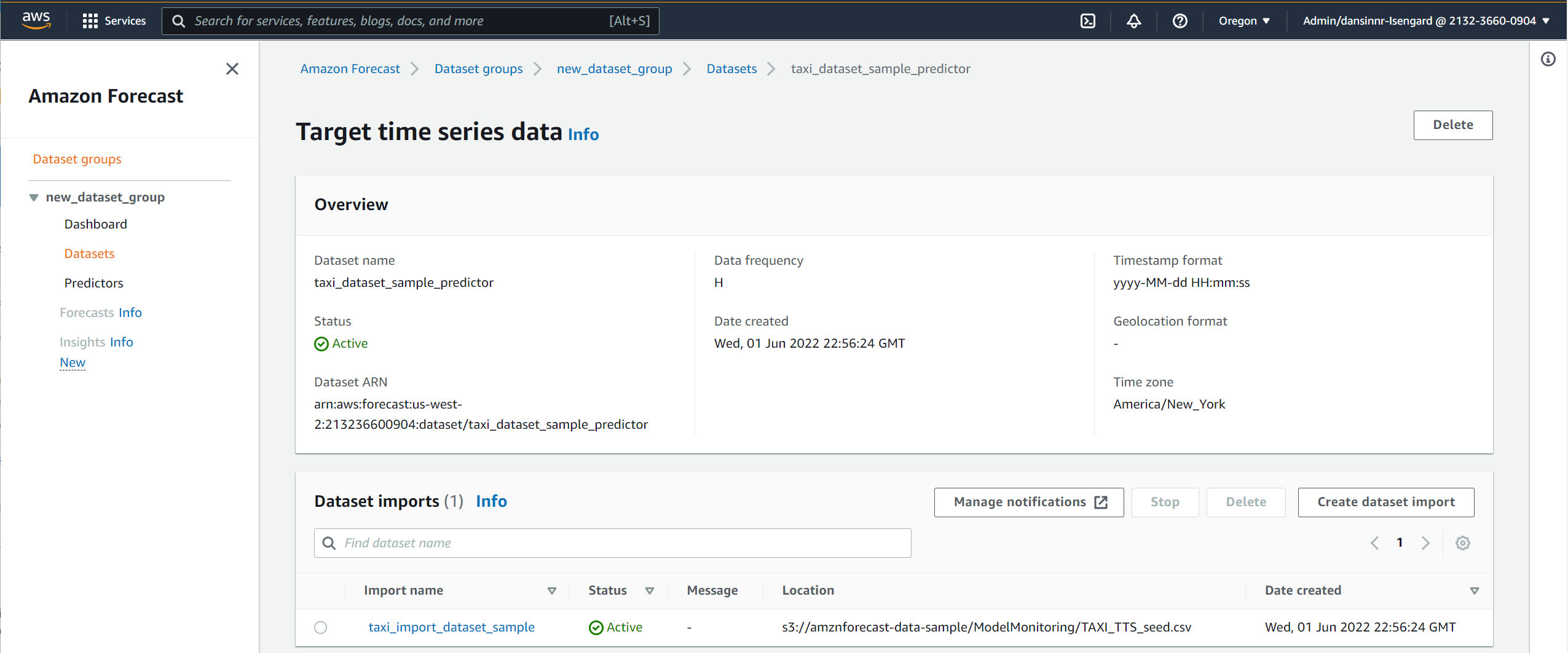
- 「Create Dataset Group」を選択し、データセットグループの詳細を入力します。データセットグループの作成後、ターゲット時系列データセットを作成するよう促されます。このデータセットは、予測子の学習と予測の作成に使用されます。
- 「Create target time series dataset」ページで、データのスキーマ、頻度、場所を入力します。
- 「Start」を選択して、ターゲットデータセットをインポートします。次に、予測子を構築し、最初のデータセットを使って再トレーニングします。
- ナビゲーションペインで、「Predictors」を選択します。
- 「Train new predictor」を選択します。

- 「Predictor settings」では、予測子の名前、どのくらいの期間をどの程度の頻度で予測したいか、予測したい分位を入力します。

- Optimization metricでは、AutoPredictorを最適化するための最適化指標を選択し、選択した特定の精度メトリクスのためにモデルをチューニングすることができます。今回はこれをデフォルトのままにしておきます。
- 予測子の説明可能性レポートを取得するには、「Enable explainability」を選択します。
- 予測子の監視を有効にするには、「Enable predictor monitoring」を選択します。
- 入力データ構成では、より正確な需要予測のために地域の気象情報と祝日を追加することができます。
- 「Create」を選択して、予測子のトレーニングを開始します。
 Forecastはこの初期データセットでPredictorをトレーニングします。予測子の監視を有効にすると、このデータセットグループに新しいデータが提供されるたびに、Forecastは更新された予測子の精度メトリクスを計算できるようになります。
Forecastはこの初期データセットでPredictorをトレーニングします。予測子の監視を有効にすると、このデータセットグループに新しいデータが提供されるたびに、Forecastは更新された予測子の精度メトリクスを計算できるようになります。 - 予測子のトレーニングが終了したらそれを選択して初期の精度メトリクスを評価します。
 「Metrics」タブは、初期の予測子のメトリクスを表示します。予測子から予測を生成したり、新しいデータをインポートしていないため、「Monitoring」タブには何も表示されません。
「Metrics」タブは、初期の予測子のメトリクスを表示します。予測子から予測を生成したり、新しいデータをインポートしていないため、「Monitoring」タブには何も表示されません。 次のステップは、新しい予測子を使った予測を生成することです。
次のステップは、新しい予測子を使った予測を生成することです。 - ナビゲーション・ペインで「Forecast」を選択します。
- インポートしたばかりの時系列データと予測子の設定に基づいて新しい予測を作成するために、「Create Forecast」を選択し ます。
- 予測名、予測子名、および計算したい追加の分位数メトリクスを設定します。
Forecastを作成した後、詳細ページでその結果を表示したりエクスポートすることができます。
Predictor monitoring: 時間の経過とともに変化する精度の評価
時間の経過とともにビジネスプロセスによって新しいデータが作成されます。例えば、更新された売上高、スタッフレベル、製造生産高などです。その新しいデータに基づいて新しい予測を作成するために、作成したデータセットにデータをインポートすることができます。
- Amazon Forecastコンソールで、Dataset groupsページで、データセットグループを選択します。

- データセットを選択します。

- 「Dataset imports」セクションで、「Create dataset import」を選択します。
- 更新されたデータについて、その保存場所などさらに詳しい情報を提供してください。
- 「Start」を選択します。
予測子モニタリングでは、Forecastはこの新しいデータを以前に生成された予測と比較し、予測子の精度メトリクスを計算します。更新された予測子品質メトリックスは、新しいデータがデータセットに追加されると継続的に計算されます。
これまでの手順に従って、時間経過とともに発生した追加トランザクションを表す追加データを継続的にインポートすることができます。
予測子モニタリングの結果を評価する
予測子モニタリング結果を見るには、最初の予測を生成した後に新しいデータを追加する必要があります。Forecastはこの新しいデータを前回の予測と比較し、モニタリングのための更新されたモデル精度値を生成します。
- 「Dataset groups」ページで、関連するデータセットグループを選択し、「Target Time Series」を選択して、新しいデータで更新します。


- 「Create Dataset Import」を選択し、新しいデータを追加します。

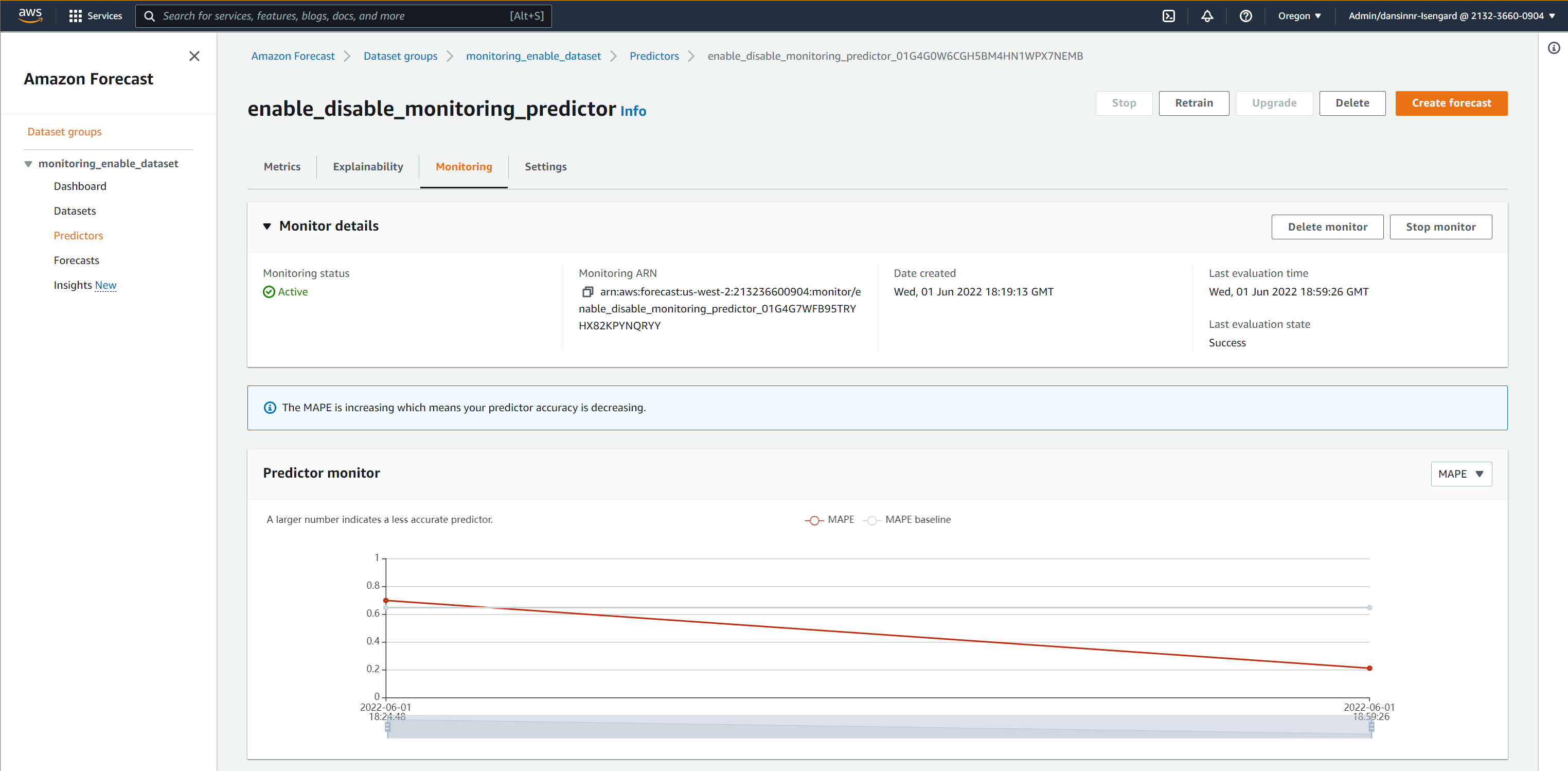
追加のデータを提供した後、予測子を開き、最初の予測子モニタリング統計を見ることができます。 - 予測子を選択し、「Monitoring」タブに移動します。

上記のステップを実行することで、同じ予測子で反復的にデータを追加して予測を継続的に行うことができます。追加データによる予測子精度の変動は、「Monitoring」タブで確認できます。

この例は,4回の追加データ更新で評価された予測子のモデル精度統計 を示しています。この予測子は,最初にトレーニングされたとき0.55のベースラインMAPEを持っ ていました。追加のデータがロードされるにつれて、MAPEは0.42に低下し、より正確な予測子であると評価され、その後のデータセットでは0.42~0.48の狭い範囲内で変動しています。
チャートを切り替えると、追加のメトリクスを表示することができます。次の例では、MASE と平均 wQL は、時間の経過とともにベースラインから同じように変動しています。
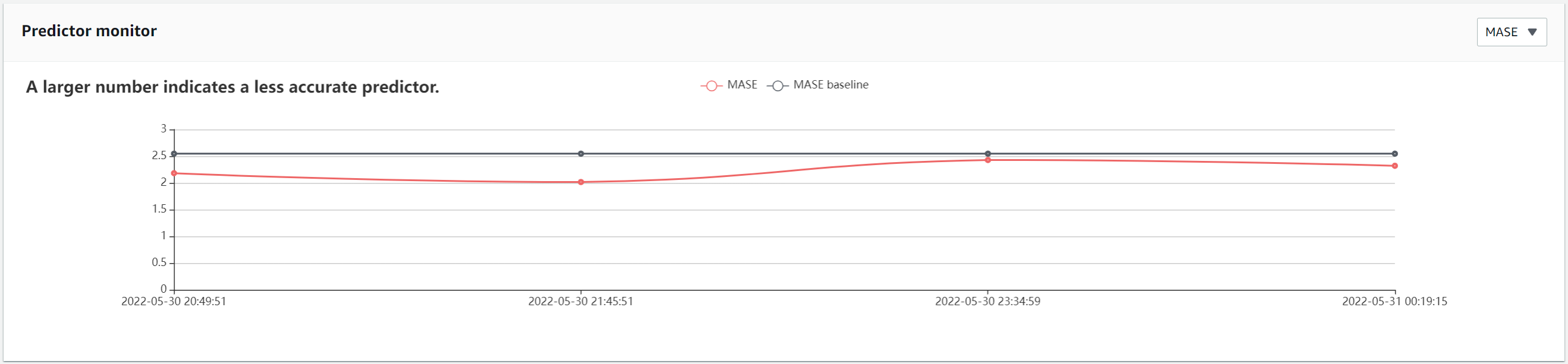

ページ下部の「モニタリング履歴」セクションには、長期にわたって追跡されたすべての予測精度メトリクスに関する完全な詳細が記載されています。

既存のPredictorでモニタリングを有効にする
既存の予測子のモニタリングを簡単に有効にすることができます。これを行うには、次の手順を実行します。
- ナビゲーション・ペインで、データセットの下の「Predictor」を選択します。
- ここから、モニタリングを有効にする方法が2つあります。
a. 「Monitoring」列で「Start Monitoring」を選択します。

b. 予測子を選択し、「Monitoring」タブの「Monitor Details」で「Start monitor」を選択します。
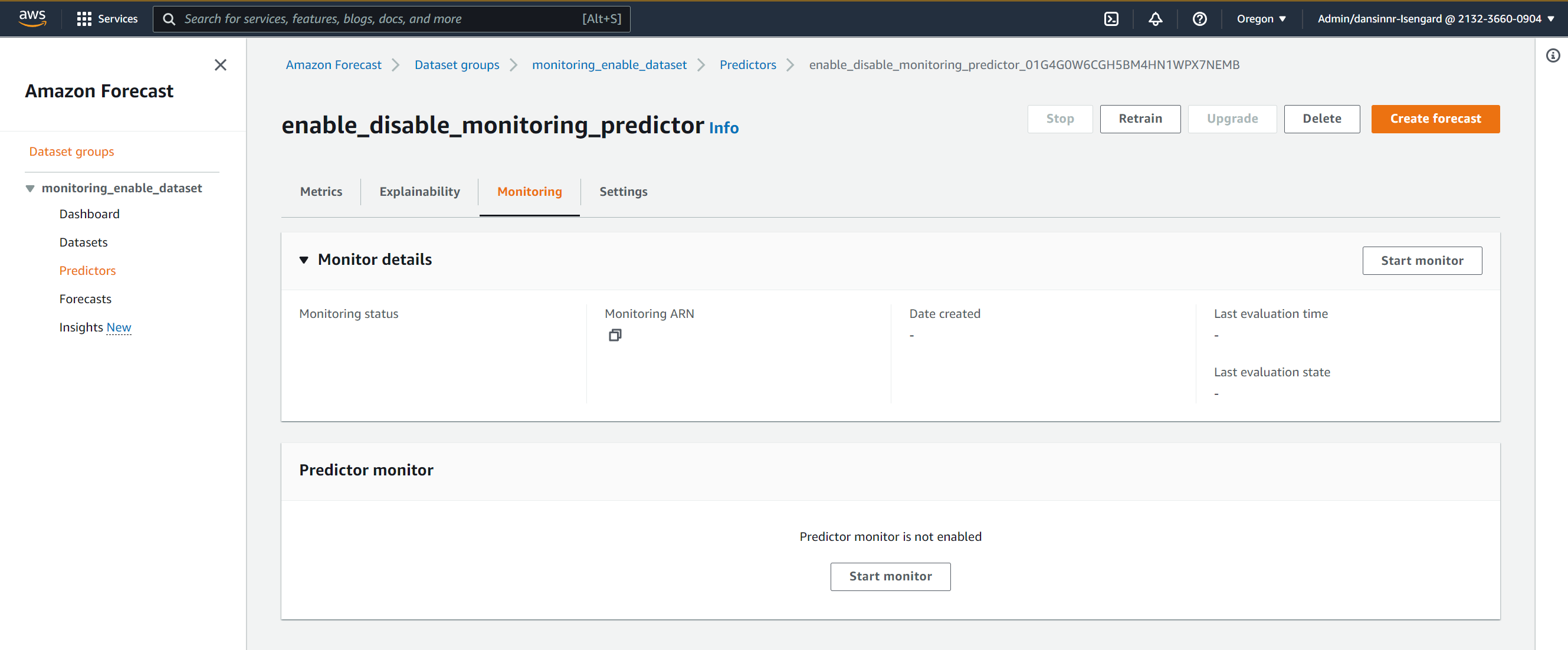
- ポップアップダイアログで、選択した予測子のモニタリングを開始するために、「Start」を選択します。

「Monitoring」タブには、予測子モニタリングが開始されたことが表示され、さらにデータをインポートすると結果が生成されるようになります。
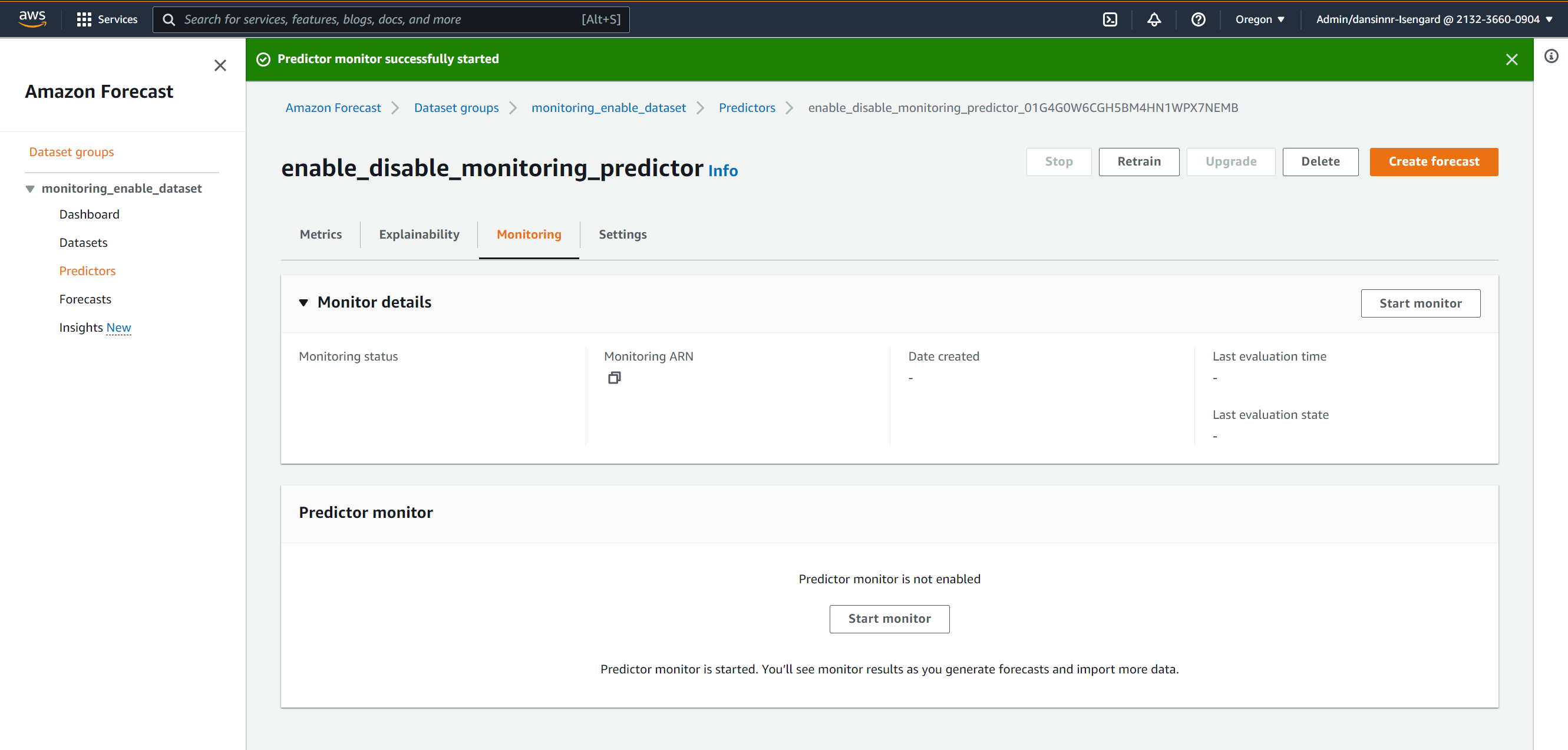
Predictorモニタリングの停止と再開
また、予測子モニタリングの停止と再開も可能です。以下を考慮してください。
- コスト – 予測子モニタリングは追加リソースを消費します。典型的な小さなデータセットでは、コストは最小限ですが、大きなデータセット(入力データセットのアイテム数、および予測期間)では増加する可能性があります。
- プライバシー – 予測のコピーはモニタリング中に保存されます。このコピーを保存したくない場合は、モニタリングを停止することができます。
- ノイズ – 予測子を実験していて、予測モニター結果にノイズを見たくない場合、予測モニターを一時的に停止して、予測子が再び安定したときに再び開始することができます。
予測子モニタリングを停止するには、次のステップを完了します。
- モニタリングが有効になっている予測子の「Monitoring」タブに移動します。
- 「Stop Monitor」を選択して、予測子のモニタリングを停止します。
- プロンプトが表示されたら、選択した内容を確認します。

次ページに予測子モニタリングが停止したことを示すメッセージが表示されます。

モニター再開を選択することで、予測子モニタリングを再開することができます。
まとめ
予測子の品質を長期にわたってモニタリングすることは、需要計画や予測の目標を達成し、最終的にはビジネス目標を達成するために重要です。しかし、予測子のモニタリングは時間のかかる作業であり、必要なワークフローを立ち上げて維持するために必要なプロセスは、運用コストの上昇につながる可能性があります。
Forecastは予測子の精度を自動的に追跡し、運用の手間を省くとともに予測子の維持、再トレーニング、再構築についてより多くの情報に基づいた意思決定を行うことができるようになりました。予測子モニタリングを有効にするには、この投稿で説明した手順を実行するか、GitHubのノートブックに従ってください。
予測子モニタリングはAutoPredictorでのみ利用可能であることに注意してください。詳細についてはこちらを参照してください。
さらに詳しい情報は、予測子のモニタリングをご参照ください。また、これらの新機能を使用するための料金を確認することをお勧めします。これらの新機能はすべて、Forecastが一般に公開されているすべてのリージョンで利用可能です。リージョンの利用可能性の詳細については、AWSリージョナルサービスを参照してください。
About the author

Dan Sinnreichは、Amazon Forecastのシニアプロダクトマネージャーです。ローコード/ノーコードの機械学習の普及と、それを用いたビジネス成果の向上に取り組んでいます。仕事以外ではホッケーをしたり、テニスのサーブを上達させようとしたり、SFを読んだりしています。
 Adarsh Singh は、Amazon Forecast チームのソフトウェア開発エンジニアとして働いています。現在の職務ではエンジニアリングの問題と、エンドユーザーに最も価値を提供するスケーラブルな分散システムの構築に注力しています。趣味はアニメ鑑賞とゲーム。
Adarsh Singh は、Amazon Forecast チームのソフトウェア開発エンジニアとして働いています。現在の職務ではエンジニアリングの問題と、エンドユーザーに最も価値を提供するスケーラブルな分散システムの構築に注力しています。趣味はアニメ鑑賞とゲーム。
 Shannon Killingsworthは、Amazon ForecastのUXデザイナーです。現在の仕事は誰でも使えるコンソール体験の作成と、コンソール体験に新しい機能を統合することです。余暇はフィットネスを楽しむ自動車愛好家です。
Shannon Killingsworthは、Amazon ForecastのUXデザイナーです。現在の仕事は誰でも使えるコンソール体験の作成と、コンソール体験に新しい機能を統合することです。余暇はフィットネスを楽しむ自動車愛好家です。
このブログは、ソリューションアーキテクトの横山誠が翻訳しました。