Amazon Web Services ブログ
Drop が Apache Spark の Amazon EMR ランタイムを使用してコストを半分にし、結果取得までの速度を 5.4 倍にした方法
これは、Drop のソフトウェアエンジニアである Michael Chau 氏と AWS ビッグデータスペシャリストソリューションアーキテクトの Leonardo Gomez 氏によるゲスト投稿です。彼らは、次のように述べています。「Drop には、一度に 1 回の報酬で、消費者の生活を向上させるという使命があります。パーソナライズされたコマースプラットフォームを通じて、適切なブランドを適切なタイミングでインテリジェントに表示し、会員の暮らしを以前よりも素晴らしいものにしています。機械学習を利用し、200 を超えるパートナーブランドと消費者をマッチングさせることで、2 つの主要な目標を実現しています。すなわち、購入からポイントを獲得し、そのポイントをすぐに特典と引き換えることができるようにすることです。トロントを本拠地としながら、グローバルな考え方をもって活動する Drop は、北米全体で 300 万人を超える会員のために、次世代のエクスペリエンスを構築しています。詳細については、www.joindrop.com をご覧ください」
概要
Drop では、データレイクインフラストラクチャが、製品とビジネスに関して、データに基づく意思決定を改善する上で不可欠な役割を果たしています。重要な機能は、膨大な量の生データを処理し、当社のデータレイクの標準化されたファイル形式とパーティション構造に準拠した調整済みデータセットを生成する機能です。当社のビジネスインテリジェンス、実験分析、機械学習 (ML) システムは、これらの変換されたデータセットを直接使用します。
この投稿では、Amazon EMR を使用するためにデータレイクのバッチ ETL パイプラインを設計および実装した方法と、Apache Spark ランタイムを数時間から数分に削減し、運用コストを 50% を超えて節約するためにアーキテクチャにおいて繰り返し実行したさまざまな方法について詳しく説明します。
パイプラインの構築
Drop のデータレイクは、ダウンストリームのビジネスインテリジェンス、実験分析、および ML システムが不可欠に依拠している会社のデータインフラストラクチャ全体における中心的かつ信頼できる情報源として機能します。当社のデータレイクの目標は、さまざまな情報源から膨大な量の生データを取り込み、ダウンストリームシステムが Amazon Simple Storage Service (Amazon S3) を介してアクセスできる信頼性の高い、調整されたデータセットを生成することです。これを実現するために、Lambda アーキテクチャ処理モデルに準拠するようにデータレイクのバッチ ETL パイプラインを構築し、Apache Spark と Amazon EMR の組み合わせを使用して、Amazon S3 レイクに到達する未加工の取り込みデータを調整されたカラムナデータセットに変換しました。このパイプラインを設計および実装するとき、当社は、以下の指針と考慮事項を核としました。
- 技術スタックをシンプルに保つ
- Infrastructure as Code を用いる
- 一時的なリソースを利用する
技術スタックをシンプルに保つ
既存の実績のある AWS テクノロジーを使用し、大きな影響をもたらすサービスのみを採用することで、技術スタックをシンプルに保つことを目指しました。Drop は元来 AWS ショップであるため、これまでの経験、新しい機能のプロトタイプを迅速に作成できる能力、Amazon のエコシステム内で他のサービスを使用することによる固有の統合がもたらすメリットを考慮すれば、AWS テクノロジーを使用し続けることは理にかなっています。
技術スタックをシンプルに保つためのもう 1 つの取り組みは、新しく採用されたオープンソースの Apache Hadoop テクノロジーのオーバーヘッドと複雑さを制限することでした。当社のエンジニアリングチームは当初、これらのテクノロジーを使用した経験が少なかったため、実績のあるフルマネージド型のサービスを使用することで、スタックへの追加の技術的オーバーヘッドを軽減するための努力を意識的に行ってきました。当社は、パイプラインの運用において必要になったときにサービスを使用できるため、Amazon EMR をべき等データパイプラインの一部として統合しました。これにより、不要なときにもサービスを維持している必要がなくなりました。こうして、運用クラスターを常に維持することによる技術的なオーバーヘッドを減らすことができました。
Infrastructure as Code を用いる
当社では、データレイクパイプラインの運用を管理およびスケジュールするために、Apache Airflow を使用しています。Airflow を使用すると、ワークフロー全体と Infrastructure as Code を Airflow Directed Acyclic Graphs (DAG) を介して構築できます。この重要な決定により、エンジニアリングの開発とデプロイのプロセスが簡素化され、データインフラストラクチャのすべての側面におけるバージョン管理が実現しました。
一時的なリソースを利用する
運用コストを削減するために、当社では重要な意思決定をしました。それは、一時的なリソースを利用してデータ処理パイプラインを構築するということです。運用で必要となる場合にのみ EMR クラスターを起動し、ジョブの完了時に終了するようにパイプラインを設計することにより、アイドル状態のリソースについての支払いを要することなく、Amazon Elastic Compute Cloud (Amazon EC2) のスポットインスタンスおよびオンデマンドインスタンスを使用できます。このアプローチにより、アイドル状態のクラスターに関連するコストを大幅に削減できました。
バッチ ETL パイプラインの概要
次の図は、バッチ ETL パイプラインアーキテクチャを示しています。
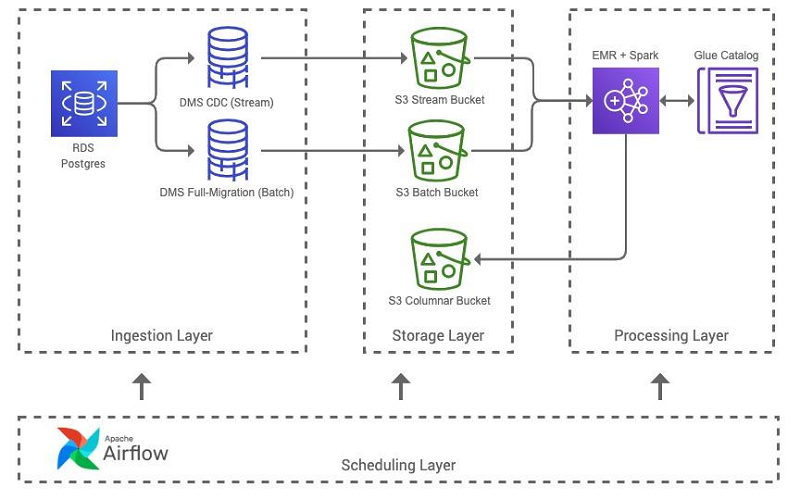
パイプラインには次のステップが含まれます。
- Lambda アーキテクチャデータモデルの核となる要件は、データセットのバッチおよびストリームのデータソースの両方にアクセスできることです。バッチ ETL パイプラインは、主に、AWS Database Migration Service (AWS DMS) を使用して、Amazon Relational Database Service (Amazon RDS) Postgres データベースからバッチおよびストリーム形式でデータを取り込みます。パイプラインは、Airflow を使用して包括的なバッチスナップショットの完全移行 AWS DMS タスクを開始し、1 分間のレイテンシー変更データキャプチャ (CDC) ファイルの継続的なレプリケーション AWS DMS タスクを使用してストリームデータを取り込みます。バッチ形式とストリーム形式の両方のデータが Amazon S3 のレイクに集められ、AWS Glue クローラーを使用して AWS Glue データカタログにカタログ化されます。
- バッチ ETL パイプラインの Apache Airflow DAG は一連のタスクを実行します。最初に、Lambda アーキテクチャの Spark アプリケーションを Amazon S3 にアップロードし、EMR クラスターを起動し、最終的には Amazon EMR のステップとして Spark アプリケーションを実行します。データセットの特性に応じて、調整されたデータセットを生成するために必要な Amazon EMR リソースが調整されます。結果のデータセットを Apache Parquet 形式で生成するには、十分な CPU とメモリをクラスターに割り当てる必要があります。
- Amazon EMR のすべてのステップが完了すると、クラスターが終了し、新しく作成されたデータセットが AWS Glue クローラーを使用してクロールされ、データカタログ内のデータセットのメタデータが更新されます。これで、出力データセットは、コンシューマーシステムが Amazon S3 を介してアクセスできるようになったほか、Amazon Athena または Amazon Redshift Spectrum を使用してクエリできるようになりました。
EMR パイプラインの進化
当社のエンジニアリングチームは、ランタイムと運用コストを削減するために、バッチ ETL パイプラインのアーキテクチャにおけるイテレーションを絶えず繰り返しています。以下のイテレーションと注目に値する機能強化により、このパイプラインに依存するエンドユーザーに加えて、ダウンストリームシステムにも非常に大きな効果がもたらされました。
AWS Glue から Amazon EMR への移行
バッチ ETL パイプラインの最初のイテレーションでは、初期段階での社内における Hadoop に関する経験が限られていたため、Amazon EMR ではなく AWS Glue を使用して Spark アプリケーションを処理しました。AWS Glue は、「サービスとしての ETL」機能と簡素化されたリソース割り当てにより、最初の魅力的なソリューションでした。AWS Glue ソリューションは、望ましい結果をもたらしてくれました。しかし、Hadoop テクノロジーの経験を積むにつれて、Amazon EMR を使用することによってパイプラインのパフォーマンスを改善し、運用コストを削減できる機会があることを認識するに至りました。
AWS Glue から Amazon EMR への移行はシームレスで、必要だったのは、EMR クラスターの設定と AWS Glue ライブラリを使用する Spark アプリケーションへの小さな変更のみでした。これにより、次の運用上のメリットが実現されました。
- クラスターのブートストラップとリソースのプロビジョニングにかかる時間が短縮されました。AWS Glue クラスターのコールドスタート時間は 10〜12 分ですが、EMR クラスターのコールドスタート時間は 7〜8 分であることがわかりました。
- 同等のリソースを使用しながら、コストを 80% 削減できました。標準の AWS Glue ワーカータイプを、DPU 時間あたり 0.44 USD のコストで、リソースに相当する m5.xlarge Amazon EMR インスタンスタイプに交換しました。これには、1 インスタンスにつき 1 時間あたり約 0.085 USD のスポットインスタンスの料金が適用されます。
ファイルコミッター
元のパーティション化戦略では、Spark の動的書き込みパーティション化機能を使用して、実行ごとに書き込まれるファイルの数を削減しようとしました。次のコードを参照してください。
sparkSession.conf.set(“spark.sql.sources.partitionOverwriteMode”, “dynamic”)
この戦略は、パイプラインのパフォーマンスにうまく反映されませんでした。クラウドオブジェクトストアの使用に関する制限と考慮事項をすぐに経験することとなりました。Spark アプリケーションのファイル書き込み戦略を、既存のディレクトリを完全に上書きし、Amazon EMR EMRFS S3 に最適化されたコミッターを使用することに転換することで、重要なパフォーマンスの向上を実現できました。データセットがほぼテラバイトであるシナリオでは、この最適化されたファイルコミッターのデプロイにより、数時間かかっていたランタイムが 30 分未満に短縮されました! Amazon EMR 5.30.0 には、動的partitionOverwriteMode に役立つ最適化が含まれていることも大事な点です。
Amazon EMR バージョンの 5.28 以降へのアップグレード
当社のデータセットは数十億行を超えることが多いため、大規模なバッチファイルに対して数十万のストリームファイルを比較および処理する必要がありました。入力データソースが与えられた場合にこれらの Spark 操作を実行する機能を使用すると、データのクエリと処理に高いコストがかかります。
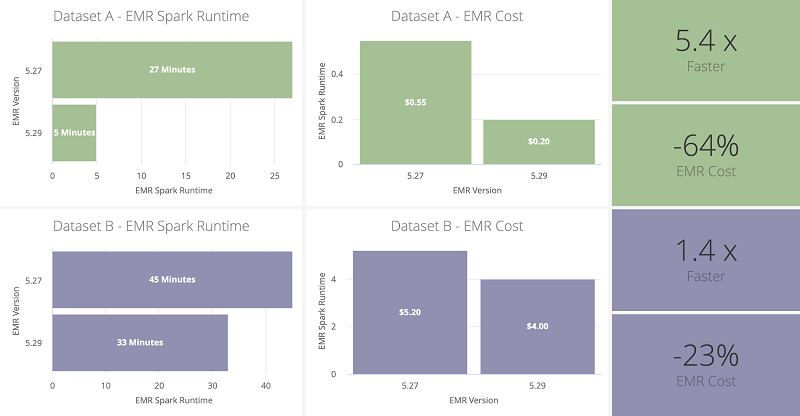
パイプラインの全体的なパフォーマンスの大幅な改善は、Amazon EMR バージョン 5.28 で導入された Apache Spark の Amazon EMR ランタイムの機能を使用したことによるものです。既存のパイプラインに追加の変更を加えることなく、Amazon EMR 5.27 から 5.29 にアップグレードすることで、すぐにパフォーマンスが向上しました。同一のリソース構成を使用した場合、Spark アプリケーションの合計ランタイムとその後の Amazon EMR コストは 35% を超えて削減されました。これらの改善は、2 つのデータセットに対してベンチマーキングされ、3 つの実稼働実行に対して平均化されました。
次の表は、データセットと EMR クラスターのプロパティをまとめたものです。
| データセット | テーブル行 | バッチファイルの合計サイズ | ストリームファイルの合計サイズ | ストリームファイルのカウント | EC2 インスタンスタイプ | EC2 インスタンスのカウント |
| データセット A | ~3.5M | ~0.5GB | ~0.2GB | ~100k | m5.xlarge | 10 |
| データセット B | ~3,500M | ~500GB | ~120GB | ~250k | r5.2xlarge | 30 |
次の図は、Amazon EMR アップグレードのパフォーマンスベンチマークとメトリクスをまとめたものです。Amazon EMR のブートストラップとリソースのプロビジョニング時間を含めて、これらのコストメトリクスを計算しました。
Amazon EMR ステップの同時実行性
パイプラインアーキテクチャの初期のイテレーションには、データセットごとの新しいバッチ ETL パイプラインの作成と、そのデータセット専用の EMR クラスターの作成が含まれていました。インフラストラクチャはコードとして記述されており、操作とリソースは自己完結型であるため、新しいパイプラインのクローンを作成することで、処理能力を迅速かつ簡単に拡張できました。これにより、最も重要なデータセットのパイプラインを迅速に生成できるようになりましたが、運用の改善のための機会が豊富にありました。
次のスクリーンショットは、Drop のバッチ ETL 処理 DAG を示しています。すべてのクラスターは、Drop のエンジニアリングチームのペットにちなんで名付けられました。
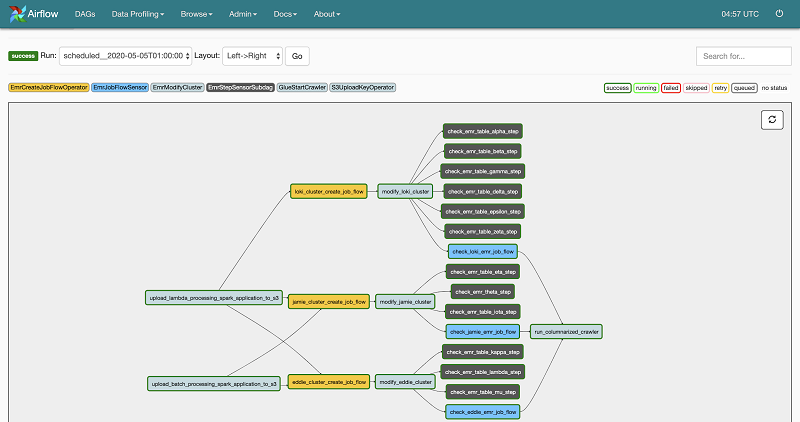
パイプラインアーキテクチャの進化においては、Amazon EMR リソース要件に基づいてデータセットをグループ化し、Amazon EMR ステップの同時実行性により、共通の EMR クラスターにおいて、それらを Spark アプリケーションの Amazon EMR のステップとして同時に実行しました。この方法でバッチ ETL パイプラインを再構築すると、次のことが可能になります。
- データセットごとの個々の EMR クラスター内に関連付けられている EMR クラスターのブートストラップおよびプロビジョニングの時間を削減する
- 全体的に Spark のランタイムを低減する
- より少ない EMR クラスターを使用することで Amazon EMR リソース構成を簡素化する
当社のクラスターは、要求されたスポットインスタンスをブートストラップして提供するのに平均 8〜10 分かかっていました。複数の Spark アプリケーションを共通の EMR クラスターに移行することで、このボトルネックを取り除き、最終的に全体的なランタイムと Amazon EMR のコストを削減することができました。Amazon EMR ステップの同時実行性により、劇的に削減されたリソースのセットに対して複数のアプリケーションを同時に実行することもできました。小規模なデータセット (1,500 万行未満) の場合、リソースを減らして Spark アプリケーションを同時に実行しても、全体的なランタイムに直線的な影響はなく、以前のアーキテクチャと比較して少ないリソースを使用することで、全体でより短いランタイムを実現できることがわかりました。ただし、より大きなデータセット (10 億行を超える) は、Amazon EMR ステップを同時に実行したときに、より小さなテーブルと同じパフォーマンス動作または向上を示しませんでした。したがって、より大きなテーブルの EMR クラスターでは、追加のリソースとステップ数を減らすことが求められます。ただし、全体的な結果は、以前のアーキテクチャと比較して、全体におけるコストとランタイムの点で、わずかではありますが、依然として優れていると言えます。
Amazon EMR インスタンスのフリート
Amazon EMR および Amazon EC2 スポットインスタンスを使用することで、大幅なコスト削減を実現できましたが、EMR クラスターの信頼性が犠牲になる可能性があります。当社では、有効市場でのスポットインスタンスタイプの供給の制約や、競争入札により EC2 インスタンスが失われたことを原因として、スポットインスタンスの可用性の問題が発生したことがあります。いずれの問題も、EMR クラスターリソースのプロビジョニングが長くなり、ノードが失われるために Spark のランタイムが長くなるという態様で、全体的なパイプラインパフォーマンスの低下に直接影響します。
パイプラインの信頼性を向上させ、これらのリスクから保護するために、当社では、Amazon EMR インスタンスフリートの使用を開始しました。インスタンスフリートは、両方の問題点に対処しました。すなわち、インスタンスフリートは、代替の Amazon EMR インスタンスタイプを調達することにより、そして、スポットインスタンスのプロビジョニングが指定されたしきい値の時間を超えた場合にオンデマンドインスタンスに自動的に切り替える機能を使用することで、特定の EC2 スポットインスタンスタイプの供給を制限しました。インスタンスフリートを使用する前は、Amazon EMR 本番稼働の約 15% がスポットインスタンスの供給または入札に関連する制限の影響を受けていました。インスタンスフリートを実装して以来、クラスターに障害が発生したり、プログラムされたしきい値を超えてリソースのプロビジョニングが長期化したりすることはありませんでした。
まとめ
Amazon EMRは、データを使用して、より情報に基づいた製品とビジネスに関する意思決定を行う Drop の能力において重要な役割を果たしてきました。当社は、Amazon EMR の機能を活用してデータ処理パイプラインの全体的なパフォーマンスとコスト効率を向上させることに大きな成功を収めており、パイプラインを継続的に改善するために、新しい方法を引き続き模索していきます。システムを改善する新しい機会について知る最も簡単な方法の 1 つは、最新の AWS テクノロジーと Amazon EMR 機能についての最新情報を常にチェックすることです。
著者について
 Michael Chau 氏は、Drop のソフトウェアエンジニアです。 データを A から B に移動した経験があり、その途中でデータを変換することもあります。
Michael Chau 氏は、Drop のソフトウェアエンジニアです。 データを A から B に移動した経験があり、その途中でデータを変換することもあります。
 LeonardoGómez 氏は、AWS のビッグデータスペシャリストソリューションアーキテクトです。 カナダのトロントを拠点とし、カナダ全土のお客様と協力してビッグデータアーキテクチャの設計と構築を行っています。
LeonardoGómez 氏は、AWS のビッグデータスペシャリストソリューションアーキテクトです。 カナダのトロントを拠点とし、カナダ全土のお客様と協力してビッグデータアーキテクチャの設計と構築を行っています。